




原文地址:https://postgrespro.com/blog/pgsql/5969403
在之前的文章中,我们讨论了系统如何计划查询执行以及它如何收集统计信息以选择最佳计划。以下文章,从这篇文章开始,将重点关注计划实际上是什么,它由什么组成,以及它是如何执行的。
在本文中,我将演示计划器如何计算执行成本。我还将讨论访问方法以及它们如何影响这些成本,并使用顺序扫描方法作为说明。最后,我将讨论 PostgreSQL 中的并行执行,它是如何工作的以及何时使用它。
我将在本文后面使用几个看似复杂的数学公式。您无需记住其中任何一个即可深入了解规划器的工作原理。他们只是在那里显示我从哪里得到我的数字。
可拔插存储引擎
PostgreSQL 将数据存储在磁盘上的方法并不是对所有可能的负载类型都是最佳的。谢天谢地,你有选择。实现其可扩展性的承诺,PostgreSQL 12 及更高版本支持自定义表访问方法(存储引擎),尽管它仅附带库存之一,堆:
SELECT amname, amhandler FROM pg_am WHERE amtype = 't'; amname | amhandler
−−−−−−−−+−−−−−−−−−−−−−−−−−−−−−−
heap | heap_tableam_handler
(1 row)您可以在创建表时指定引擎(CREATE TABLE ... USING)。如果不这样做,则使用default_table_access_method中定义的引擎。
pg_am目录存储引擎名称(列amname)以及它们的处理函数(amhandler)。每个存储引擎都带有一个核心需要的接口,以便使用引擎。处理函数的工作是返回有关接口结构的所有必要信息。
大多数存储引擎利用现有的核心系统组件:
事务管理器,包括 ACID 支持和快照隔离。
缓冲区管理器。
I/O 子系统。
吐司。
查询优化器和执行器。
索引支持。
引擎可能不一定会使用所有这些组件,但这种能力仍然存在。
然后,引擎必须定义一些事情:
行版本格式和数据结构。
表扫描例程。
插入、删除、更新和锁定例程。
行版本可见性规则。
抽真空和分析过程。
顺序扫描成本估算过程。
传统上,PostgreSQL 使用直接内置在核心中的单一数据存储系统,没有接口。现在,创建一个新接口——适应标准引擎的所有长期特殊性并且不干扰其他访问方法——是一个挑战半。
例如,预写日志记录存在问题。一些访问方法想要记录特定于引擎的操作,而核心对此一无所知。由于开销巨大,现有的通用 WAL 记录机制很少成为一种选择。您可以为新的日志记录类型设计一个单独的接口,但这会使崩溃恢复依赖于外部代码,这是您一直想要避免的。到目前为止,重建核心以适应新引擎仍然是唯一可行的选择。
说到新引擎,目前有几个正在开发中。以下是一些比较突出的:
Zheap是一个解决表格膨胀问题的引擎。它实现就地行版本更新并将快照数据存储在单独的撤消存储中。该引擎对于更新密集型工作负载非常有效。引擎设计类似于 Oracle 的引擎设计,但有一些不同之处(例如,索引访问方法接口不支持具有自己的多版本并发控制的索引)。
Zedstore实现了列式存储,旨在更有效地处理 OLAP 事务。它将数据组织到由行版本 ID 组成的主 B 树中,并且每一列都存储在其自己的 B 树中,该 B 树引用主 B 树。未来,该引擎可能支持在一棵树中存储多个列,本质上成为一个混合存储引擎。
顺序扫描
存储引擎确定表数据在磁盘上的物理分布方式并提供访问它的方法。顺序扫描是一种对主表fork的文件(files)进行完整扫描的方法。在每一页上,系统检查每一行版本的可见性,并丢弃与查询不匹配的版本。
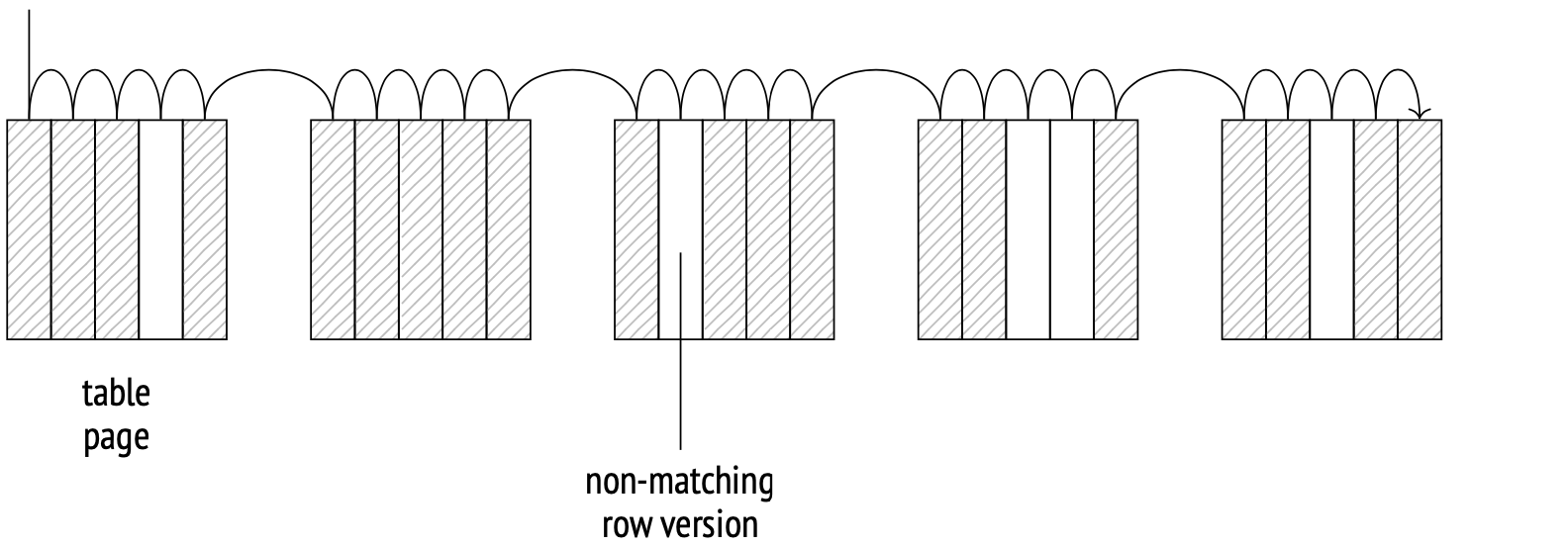
扫描是通过缓冲区高速缓存完成的。系统使用一个小的缓冲环来防止较大的表从缓存中推送可能有用的数据。当另一个进程需要扫描同一张表时,它会加入缓冲环,从而节省磁盘读取时间。因此,扫描不一定从文件的开头开始。
顺序扫描是扫描整个表或其中重要部分的最具成本效益的方法。In other words, sequential scan is efficient when selectivity is low. 在更高的选择性下,当表中只有一小部分行满足过滤器要求时,通常最好使用索引扫描。
示例计划
执行计划中的顺序扫描阶段用Seq Scan节点表示。
EXPLAIN SELECT * FROM flights;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..4772.67 rows=214867 width=63) (1 row)
行数估计是一个基本的统计量:
SELECT reltuples FROM pg_class WHERE relname = 'flights';
reltuples −−−−−−−−−−− 214867 (1 row)
在估算成本时,优化器会考虑磁盘输入/输出和 CPU 处理成本。
I/O 成本估计为单个页面获取成本乘以表中的页面数,前提是这些页面是按顺序获取的。当缓冲区管理器向操作系统请求一个页面时,系统实际上从磁盘读取了更大的数据块,因此接下来的几个页面可能已经在操作系统的缓存中。这使得顺序获取成本(计划器在seq_page_cost的权重,默认为 1)大大低于随机访问的获取成本(在random_page_cost的权重,默认为 4)。
默认权重适用于 HDD 驱动器。如果您使用 SSD,则可以将random_page_cost设置得更低(seq_page_cost通常保留为 1 作为参考值)。成本取决于硬件,因此它们通常设置在表空间级别
(ALTER TABLESPACE ... SET)。
SELECT relpages, current_setting('seq_page_cost') AS seq_page_cost, relpages * current_setting('seq_page_cost')::real AS total FROM pg_class WHERE relname='flights';
relpages | seq_page_cost | total −−−−−−−−−−+−−−−−−−−−−−−−−−+−−−−−−− 2624 | 1 | 2624 (1 row)
这个公式完美地说明了由于后期清理导致的表膨胀的结果。主表分支越大,要获取的页面就越多,无论这些页面中的数据是否是最新的。
CPU 处理成本估计为每个行版本的处理成本之和(由规划器在 cpu_tuple_cost 加权,默认为0.01):
SELECT reltuples, current_setting('cpu_tuple_cost') AS cpu_tuple_cost, reltuples * current_setting('cpu_tuple_cost')::real AS total FROM pg_class WHERE relname='flights';
reltuples | cpu_tuple_cost | total −−−−−−−−−−−+−−−−−−−−−−−−−−−−+−−−−−−−−− 214867 | 0.01 | 2148.67 (1 row)
两项费用之和为计划总费用。该计划的启动成本为零,因为顺序扫描不需要任何准备步骤。
任何表过滤器都将列在Seq Scan节点下方的计划中。行数估计将考虑过滤器的选择性,成本估计将包括它们的处理成本。该EXPLAIN ANALYZE命令显示扫描的实际行数和过滤器删除的行数:
EXPLAIN (analyze, timing off, summary off) SELECT * FROM flights WHERE status = 'Scheduled';
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..5309.84 rows=15383 width=63) (actual rows=15383 loops=1) Filter: ((status)::text = 'Scheduled'::text) Rows Removed by Filter: 199484 (5 rows)
具有聚合的示例计划
考虑这个涉及聚合的执行计划:
EXPLAIN SELECT count(*) FROM seats;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Aggregate (cost=24.74..24.75 rows=1 width=8) −> Seq Scan on seats (cost=0.00..21.39 rows=1339 width=0) (2 rows)
该计划中有两个节点:Aggregate和Seq Scan。Seq Scan扫描表并将数据向上传递到Aggregate,而Aggregate持续计算行数。
请注意,Aggregate节点有一个启动成本:聚合本身的成本,它需要来自子节点的所有行来计算。估计值是根据输入行数乘以任意操作的成本(cpu_operator_cost,默认为 0.0025)计算得出的:
SELECT reltuples, current_setting('cpu_operator_cost') AS cpu_operator_cost, round(( reltuples * current_setting('cpu_operator_cost')::real )::numeric, 2) AS cpu_cost FROM pg_class WHERE relname='seats';
reltuples | cpu_operator_cost | cpu_cost −−−−−−−−−−−+−−−−−−−−−−−−−−−−−−−+−−−−−−−−−− 1339 | 0.0025 | 3.35 (1 row)
然后将估计值添加到Seq Scan节点的总成本中。
然后Aggregate的总成本增加cpu_tuple_cost,这是结果输出行的处理成本:
WITH t(cpu_cost) AS ( SELECT round(( reltuples * current_setting('cpu_operator_cost')::real )::numeric, 2) FROM pg_class WHERE relname = 'seats' ) SELECT 21.39 + t.cpu_cost AS startup_cost, round(( 21.39 + t.cpu_cost + 1 * current_setting('cpu_tuple_cost')::real )::numeric, 2) AS total_cost FROM t;
startup_cost | total_cost −−−−−−− −−+−−−−−−−−−−−− 24.74 | 24.75 (1 row)
并行执行计划
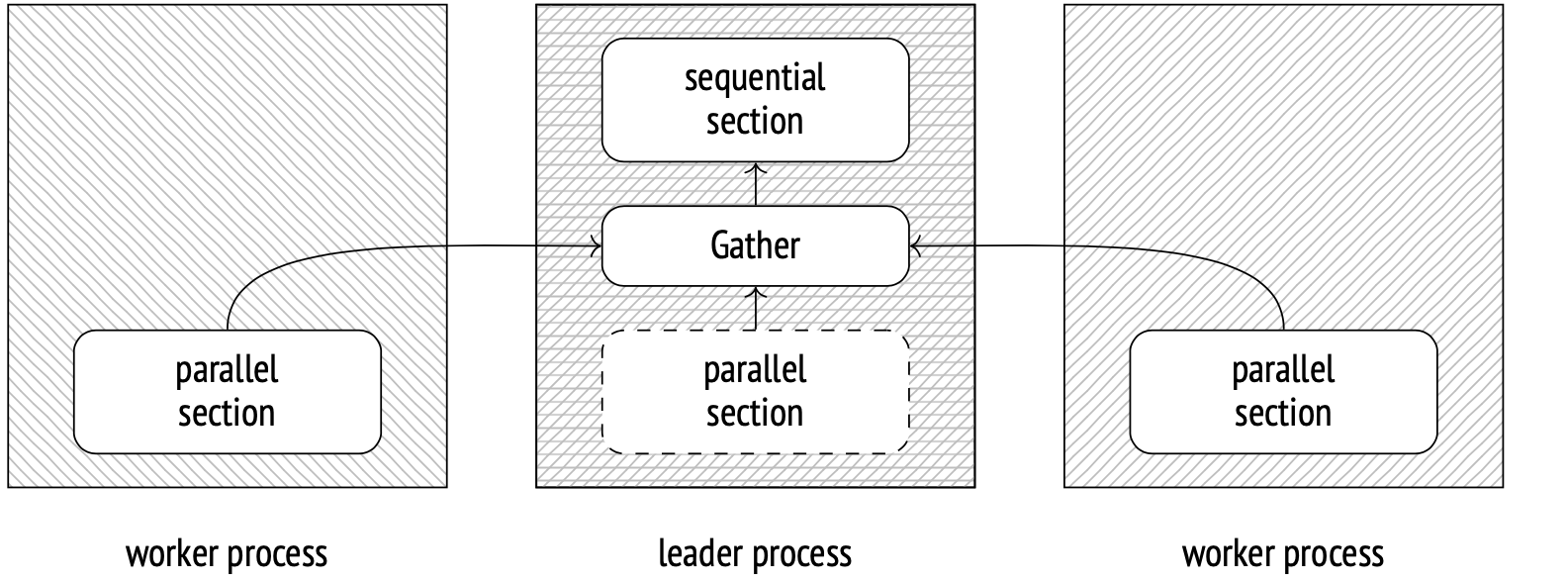
在 PostgreSQL 9.6 及更高版本中,计划的并行执行是一回事。它是这样工作的:领导进程(通过 postmaster)创建了几个工作进程。然后这些进程同时并行执行计划的一部分。然后由领导进程在Gather节点收集结果。虽然领导进程不忙于收集数据,但领导进程也可以参与并行计算。
您可以通过将parallel_leader_participation参数设置为 0来禁用此行为,但仅限于版本 11 或更高版本。
产生新进程并在它们之间发送数据会增加总成本,因此您通常最好不要使用并行执行。
此外,有些操作根本无法并行执行。即使启用了并行模式,领导进程仍将单独按顺序执行某些步骤。
并行顺序扫描
该方法的名称可能听起来有争议,声称同时是并行和顺序的,但这正是Parallel Seq Scan节点发生的事情。从磁盘的角度来看,所有文件页面都是按顺序获取的,与常规顺序扫描相同。然而,获取是由多个并行工作的进程完成的。这些进程在一个特殊的共享内存部分中同步它们的获取计划,以避免两次获取相同的页面。
另一方面,操作系统不认为这种获取是顺序的。从它的角度来看,它只是请求看似随机页面的几个进程。这打破了通过常规顺序扫描为我们服务的预取。这个问题在 PostgreSQL 14 中得到了修复,当系统开始为每个并行进程分配几个连续的页面来一次获取而不是一个。
并行扫描本身对成本效率没有多大帮助。事实上,它所做的只是在常规页面获取成本之上增加了进程之间的数据传输成本。但是,如果工作进程不仅扫描行,还对它们进行某种程度的处理(例如聚合),那么您可能会节省大量时间。
具有聚合的示例并行计划
优化器在一个大表上看到这个简单的聚合查询,并提出最佳策略是并行模式:
EXPLAIN SELECT count(*) FROM bookings;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Finalize Aggregate (cost=25442.58..25442.59 rows=1 width=8) −> Gather (cost=25442.36..25442.57 rows=2 width=8) Workers Planned: 2 −> Partial Aggregate (cost=24442.36..24442.37 rows=1 width=8) −> Parallel Seq Scan on bookings (cost=0.00..22243.29 rows=879629 width=0) (7 rows)
Gather下面的所有节点都是计划的平行部分。它将由所有工作进程(在这种情况下,其中 2 个是计划的)和领导进程(除非被parallel_leader_participation选项禁用)执行。Gather节点和它上面的所有节点由leader 进程顺序执行。
考虑Parallel Seq Scan节点,扫描本身发生在这里。行字段显示一个进程要处理的行的估计值。计划了 2 个工作进程,领导进程也将协助,因此行数估计等于表总行数除以 2.4(工作进程为 2,领导者为 0.4;工作人员越多,领导者越少贡献)。
SELECT reltuples::numeric, round(reltuples / 2.4) AS per_process FROM pg_class WHERE relname = 'bookings';
reltuples | per_process −−−−−−−−−−−+−−−−−−−−−−−−− 2111110 | 879629 (1 row)
并行 Seq Scan成本的计算方式与Seq Scan成本大致相同。我们通过让每个进程处理更少的行来赢得时间,但我们仍然通过和通过读取表,因此 I/O 成本不受影响:
SELECT round(( relpages * current_setting('seq_page_cost')::real + reltuples / 2.4 * current_setting('cpu_tuple_cost')::real )::numeric, 2) FROM pg_class WHERE relname = 'bookings';
round −−−−−−−−−− 22243.29 (1 row)
Partial Aggregate节点聚合工作进程生成的所有数据(在这种情况下计算行数)。
总成本的计算方式与之前相同,并添加到扫描成本中。
WITH t(startup_cost) AS ( SELECT 22243.29 + round(( reltuples / 2.4 * current_setting('cpu_operator_cost')::real )::numeric, 2) FROM pg_class WHERE relname='bookings' ) SELECT startup_cost, startup_cost + round(( 1 * current_setting('cpu_tuple_cost')::real )::numeric, 2) AS total_cost FROM t;
startup_cost | total_cost −−−−−−−−−−−−−−+−−−−−−−−−−−− 24442.36 | 24442.37 (1 row)
下一个节点Gather由领导进程执行。该节点启动工作进程并收集它们的输出数据。
启动一个工作进程(或多个;成本不变)的成本由参数parallel_setup_cost(默认为 1000)定义。将单行从一个进程发送到另一个进程的成本由parallel_tuple_cost(默认为 0.1)设置。大部分节点成本是并行进程的初始化。它被添加到Partial Aggregate节点启动成本中。还有两排传动;此成本被添加到部分聚合节点的总成本中。
SELECT 24442.36 + round( current_setting('parallel_setup_cost')::numeric, 2) AS setup_cost, 24442.37 + round( current_setting('parallel_setup_cost')::numeric + 2 * current_setting('parallel_tuple_cost')::numeric, 2) AS total_cost;
setup_cost | total_cost −−−−−−−−−−−−+−−−−−−−−−−−− 25442.36 | 25442.57 (1 row)
Finalize Aggregate节点将Gather节点收集的部分数据连接在一起。它的成本评估就像使用常规Aggregate一样。启动成本包括三行的聚合成本和Gather节点总成本(因为Finalize Aggregate需要其所有输出进行计算)。总成本之上的樱桃是一个结果行的输出成本。
WITH t(startup_cost) AS ( SELECT 25442.57 + round(( 3 * current_setting('cpu_operator_cost')::real )::numeric, 2) FROM pg_class WHERE relname = 'bookings' ) SELECT startup_cost, startup_cost + round(( 1 * current_setting('cpu_tuple_cost')::real )::numeric, 2) AS total_cost FROM t;
startup_cost | total_cost −−−−−−−−−−−−−−+−−−−−−−−−−−− 25442.58 | 25442.59 (1 row)
并行处理限制
应该牢记并行处理的几个限制。
工作进程数
后台工作进程的使用不限于并行查询执行:它们由逻辑复制机制使用,并且可以由扩展创建。系统最多可以同时运行max_worker_processes 个后台工作者(默认为 8 个)。
其中,最多可以将max_parallel_workers(默认情况下也是 8 个)分配给并行查询执行。
每个领导进程允许的工作进程数由max_parallel_workers_per_gather设置(默认为 2)。
您可以根据几个因素选择更改这些值:
硬件配置:系统必须有备用处理器内核。
表大小:并行查询对较大的表很有帮助。
负载类型:从并行执行中受益最多的查询应该很普遍。
这些因素对于 OLAP 系统通常是正确的,而对于 OLTP 系统通常是错误的。
规划器甚至不会考虑并行扫描,除非它期望读取至少min_parallel_table_scan_size的数据(默认为 8MB)。
下面是计算计划工作进程数的公式:
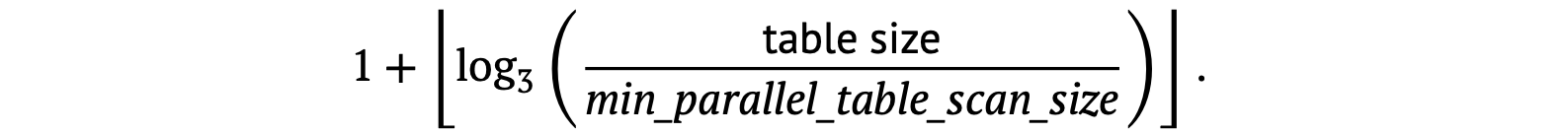
本质上,每当表大小增加三倍时,规划器就会增加一个并行工作者。这是一个带有默认参数的示例表。
| 表,MB | 工人人数 |
|---|---|
| 8 | 1 |
| 24 | 2 |
| 72 | 3 |
| 216 | 4 |
| 648 | 5 |
| 1944年 | 6 |
可以使用表存储参数parallel_workers显式设置工作人员的数量。
不过,worker 的数量仍将受到 max_parallel_workers_per_gather参数的限制。
让我们查询一个 19MB 的小表。只会计划和创建一个工作进程(请参阅计划的工作人员和启动的工作人员):
EXPLAIN (analyze, costs off, timing off) SELECT count(*) FROM flights;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Finalize Aggregate (actual rows=1 loops=1) −> Gather (actual rows=2 loops=1) Workers Planned: 1 Workers Launched: 1 −> Partial Aggregate (actual rows=1 loops=2) −> Parallel Seq Scan on flights (actual rows=107434 lo... (6 rows)
现在让我们查询一个 105MB 的表。系统将只创建两个工人,遵守max_parallel_workers_per_gather限制。
EXPLAIN (analyze, costs off, timing off) SELECT count(*) FROM bookings;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Finalize Aggregate (actual rows=1 loops=1) −> Gather (actual rows=3 loops=1) Workers Planned: 2 Workers Launched: 2 −> Partial Aggregate (actual rows=1 loops=3) −> Parallel Seq Scan on bookings (actual rows=703703 l... (6 rows)
如果增加限制,则会创建三个工人:
ALTER SYSTEM SET max_parallel_workers_per_gather = 4; SELECT pg_reload_conf(); EXPLAIN (analyze, costs off, timing off) SELECT count(*) FROM bookings;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Finalize Aggregate (actual rows=1 loops=1) −> Gather (actual rows=4 loops=1) Workers Planned: 3 Workers Launched: 3 −> Partial Aggregate (actual rows=1 loops=4) −> Parallel Seq Scan on bookings (actual rows=527778 l... (6 rows)
如果执行查询时系统中的计划工作人员数量多于可用工作人员插槽,则只会创建可用数量的工作人员。
不可并行查询
并非每个查询都可以并行化。这些是不可并行化查询的类型:
修改或锁定数据的查询(
UPDATE、DELETE等SELECT FOR UPDATE)。在 PostgreSQL 11 中,当在 commands 中调用时,此类查询仍然可以并行执行
CREATE TABLE AS,SELECT INTO并且CREATE MATERIALIZED VIEW(在版本 14 和更高版本中也可以在 中REFRESH MATERIALIZED VIEW)。但是,即使在这些情况下,所有
INSERT操作仍将按顺序执行。可以在执行期间暂停的任何查询。游标内的查询,包括 PL/pgSQL FOR 循环中的查询。
调用
PARALLEL UNSAFE函数的查询。默认情况下,这包括所有用户定义的函数和一些标准函数。您可以从系统目录中获取不安全函数的完整列表:SELECT * FROM pg_proc WHERE proparallel = 'u';从已经并行化的查询中调用的函数内部的查询(以避免递归地创建新的后台工作人员)。
未来的 PostgreSQL 版本可能会消除其中一些限制。例如,版本 12 添加了在 Serializable 隔离级别并行化查询的能力。
查询不会并行运行的可能原因有多种:
它首先是不可并行的。
您的配置会阻止创建并行计划(包括当表小于并行化阈值时)。
并行计划比顺序计划成本更高。
如果你想强制一个查询并行执行——出于研究或其他目的——你可以设置参数 force_parallel_mode on。这将使规划器总是产生并行计划,除非查询是严格不可并行的:
EXPLAIN SELECT * FROM flights;QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights (cost=0.00..4772.67 rows=214867 width=63) (1 row)
SET force_parallel_mode = on; EXPLAIN SELECT * FROM flights;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Gather (cost=1000.00..27259.37 rows=214867 width=63) Workers Planned: 1 Single Copy: true −> Seq Scan on flights (cost=0.00..4772.67 rows=214867 width=63) (4 rows)
并行受限查询
一般来说,并行计划的好处主要取决于计划中有多少是并行兼容的。但是,从技术上讲,有些操作不会阻止并行化,但只能按顺序执行,并且只能由领导进程执行。换句话说,这些操作不能出现在计划的并行部分,在Gather下面。
不可扩展的子查询。包含不可扩展子查询的操作的一个基本示例是公用表表达式扫描(CTE Scan下面的节点):
EXPLAIN (costs off) WITH t AS MATERIALIZED ( SELECT * FROM flights ) SELECT count(*) FROM t;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−− Aggregate CTE t −> Seq Scan on flights −> CTE Scan on t (4 rows)
如果公用表表达式没有具体化(这仅在 PostgreSQL 12 及更高版本中成为可能),则没有CTE 扫描节点并且没有问题。
表达式本身可以并行处理,如果它是更快的选项。
EXPLAIN (costs off) WITH t AS MATERIALIZED ( SELECT count(*) FROM flights ) SELECT * FROM t;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− CTE Scan on t CTE t −> Finalize Aggregate −> Gather Workers Planned: 1 −> Partial Aggregate −> Parallel Seq Scan on flights (7 rows)
不可扩展子查询的另一个示例是带有SubPlan节点的查询。
EXPLAIN (costs off) SELECT * FROM flights f WHERE f.scheduled_departure > ( -- SubPlan SELECT min(f2.scheduled_departure) FROM flights f2 WHERE f2.aircraft_code = f.aircraft_code );
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights f Filter: (scheduled_departure > (SubPlan 1)) SubPlan 1 −> Aggregate −> Seq Scan on flights f2 Filter: (aircraft_code = f.aircraft_code) (6 rows)
前两行显示主查询的计划:扫描flights表并过滤每一行。过滤条件包括一个子查询,其计划遵循主计划。SubPlan节点执行多次:在这种情况下,每个扫描行执行一次。
Seq Scan父节点无法并行化,因为它需要SubPlan输出才能继续。
最后一个示例是执行由InitPlan节点表示的不可扩展子查询。
EXPLAIN (costs off) SELECT * FROM flights f WHERE f.scheduled_departure > ( -- SubPlan SELECT min(f2.scheduled_departure) FROM flights f2 WHERE EXISTS ( -- InitPlan SELECT * FROM ticket_flights tf WHERE tf.flight_id = f.flight_id ) );
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Seq Scan on flights f Filter: (scheduled_departure > (SubPlan 2)) SubPlan 2 −> Finalize Aggregate InitPlan 1 (returns $1) −> Seq Scan on ticket_flights tf Filter: (flight_id = f.flight_id) −> Gather Workers Planned: 1 Params Evaluated: $1 −> Partial Aggregate −> Result One−Time Filter: $1 −> Parallel Seq Scan on flights f2 (14 rows)
与SubPlan不同,InitPlan节点仅执行一次(在这种情况下,每次SubPlan 2执行一次)。
InitPlan节点的父节点不能并行化,但使用InitPlan输出的节点可以,如此处所示。
临时表。临时表只能按顺序扫描,因为只有领导进程才能访问它们。
CREATE TEMPORARY TABLE flights_tmp AS SELECT * FROM flights; EXPLAIN (costs off) SELECT count(*) FROM flights_tmp;
QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Aggregate −> Seq Scan on flights_tmp (2 rows)
并行受限功能。PARALLEL RESTRICTED仅允许在计划的顺序部分中调用标记为的函数。您可以在系统目录中找到受限功能的列表:
SELECT * FROM pg_proc WHERE proparallel = 'r';只有在彻底研究了现有的限制并非常小心之后,才能标记您自己的功能PARALLEL RESTRICTED(更不用说)。PARALLEL SAFE
继续阅读。
