




DBA日常运维过程中经常会碰到一些rd过来询问,为什么我检索的字段上有索引,但是sql执行就是不走该索引 ,该怎么办。今天,通过这篇文章来解释这个问题,并提供一种快速解决这种问题的办法。
本文只考虑MySQL内部因素,只讨论innodb表。我们先来看看影响sql执行计划的相关因素有哪些,据我所知,目前主要有3大因素,如果有其他因素 ,欢迎大家指出,3大主要因素如下:
表统计信息
hint语法
optimizer_switch设置
日常hint和optimizer_switch使用较少,本文不重点讨论,重点讨论表统计信息对sql执行计划的影响。
MySQL优化器主要是根据表的索引统计信息来计算sql执行花费的成本,选择不同的索引,花费的成本不同,优化器会选择花费最低的索引方案。
因为innodb表的统计信息并不是实时统计更新,如果统计信息和实际的索引信息差异很大,就会导致优化器计算各个索引成本后,做出非预期的选择。所以怎么确定表统计信息和实际索引信息有多大差异,是我们今天探讨的重点。
首先,我们来看看innodb表统计信息的相关因素:
innodb_stats_persistent_sample_pages:innodb表信息统计采样页数,默认20,该值越大,统计信息 约准确,耗时也就越长
innodb_stats_persistent:统计信息是否持久化到磁盘,默认开启
innodb_stats_auto_recalc:是否自动更新统计信息,默认开启,表更新超过10%记录会自动重新统计表信息进行更新
mysql.innodb_table_stats(innodb表统计信息存储表),结构说明如下:
database_name:库名
table_name:表名
last_update:最近更新时间
n_rows:记录数
clustered_index_size:主键索引页数
sum_of_other_index_sizes:非主键索引页数
mysql.innodb_index_stats(innodb表索引信息存储表),结构说明如下 :
database_name:库名
table_name:表名
index_name:索引名
last_update:最近更新时间
stat_name:统计项
stat_value:统计项值
sample_size:统计采样页数
stat_description:统计项说明
innodb_index_stats常用统计项说明
n_diff_pfx{NUM}:该索引统计项不同的值有多少,对于非联合索引,NUM均为 01,联合索引该项表示前NUM列组合不同的值的有多少,如n_diff_pfx02表示该索引 key1,key2组合有多少个不同的值。
n_leaf_pages:该索引叶子节点页数
size:索引总页数
从上面的innodb表统计信息相关参数,我们可以知道innodb是通过采样部分数据页来做表信息统计 ,这就注定结果不会特别准确。
MySQL提供了两种统计信息更新方式,一种是表更新的记录超过1/10自动触发统计更新,另一种就是手动执行 analyze table xxx来触发统计更新,这种方式可能比较耗时。从原理我们可以知道,这两种方式就算更新后,统计信息也未必准确,今天我们来看看一种相对比较精确的统计更新方式。
innodb表统计信息存储在mysql.innodb_table_stats和mysql.innodb_index_stats中,我们直接更新这两表,看看结果如何。
我们先看看celery_taskmeta表索引信息,注意cardinality的值,为该索引统计不同值的个数:

我们看看表celery_taskmeta实际的主键和索引不同值,可以看到和自动统计的结果有85%以上的差异。
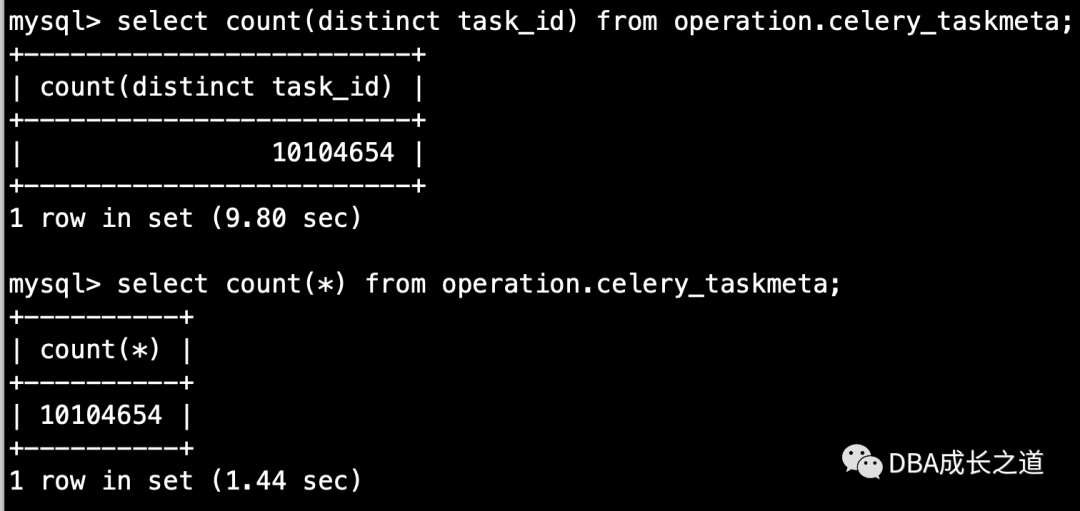
我们手动更新下表统计信息为人工查出来的结果



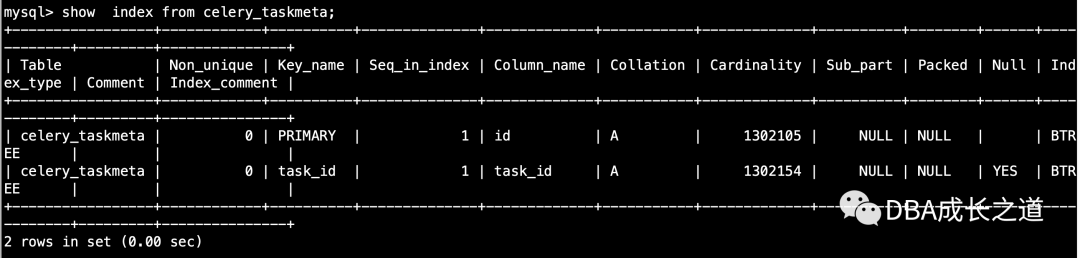
再查看下更新后的index统计信息
刷新下表,再看看统计信息,已经变成了手动更新的结果,该结果比自动统计信息精确的多。
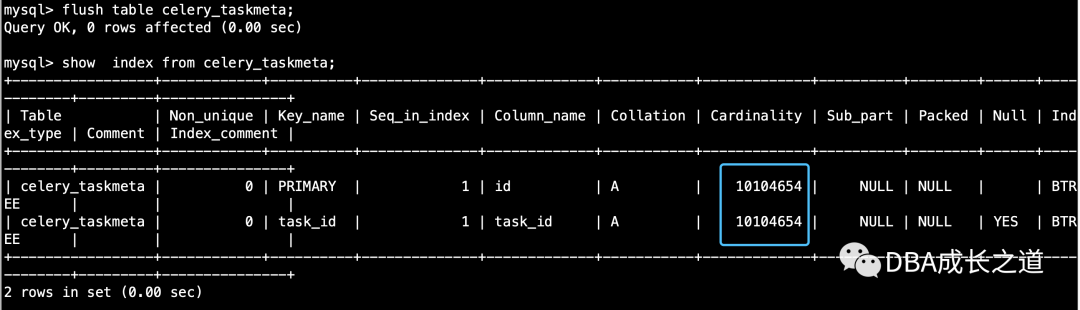
由以上,我们是不是想到可以写个脚本,定时去从机精确统计表的索引信息 ,然后去主上更新,这样表的索引统计信息相对自动统计来说,就精确的多,而且更新速度很快,只需执行flush table xx使更新生效,执行flush table xxx时注意慢语句。
比起analyze table xx来说 ,上面这种更新方式不进效率高,而且统计信息也精确的多。
表在更新10%以上数据或手动执行analyze table xx时会重新统计表信息
表统计信息不准确,可以手动查出表索引精确的信息,然后更新至innodb_table_stats、innodb_index_stats相关统计项中,最后通过flush table xx使手动更新统计项生效,执行flush table xx注意慢语句。
