




MySQL Replication一直是 Github、Twitter、Facebook 等大型组织最常用和最广泛使用的高可用性解决方案。 虽然易于设置,但使用此解决方案时面临的终极挑战来自于进行软件升级等维护、跨副本节点的数据漂移或数据不一致、拓扑更改、故障转移和恢复。当MySQL发布 5.6 版时,它带来了许多重要的增强,特别是在复制方面,包括全局事务 ID (GTID)、事件校验和、多线程从属和崩溃安全从属/主控。MySQL 5.7 和 MySQL 8.0 的复制变得更好。
它可以将来自一台MySQL服务器(主/主)的数据复制到一台或多台 MySQL 服务器(副本/从)。MySQL 复制非常容易设置,用于扩展读取工作负载、提供高可用性和地理冗余以及卸载备份和分析作业。
MySQL 复制本质上
让我们快速了解一下 MySQL 复制在本质上是如何工作的。MySQL 复制范围很广,有多种方法可以配置它以及如何使用它。默认情况下,它使用异步复制,当事务在本地环境中完成时工作,不能保证任何事件都会到达任何从属设备。它是一种松散耦合的主从关系,其中:
- 主节点不等待副本。
- 副本确定要读取多少以及从二进制日志中的哪个点读取。
- 在读取或应用更改时,副本可以任意落后于主机。
如果主节点崩溃,它提交的事务可能不会传输到任何副本。因此,在这种情况下,从主副本到最高级副本的故障转移可能会导致故障转移到所需的主副本,而该主副本实际上缺少与先前服务器相关的事务。
异步复制提供更低的写入延迟,因为写入在写入从机之前由主机在本地确认。它非常适合读取扩展,因为添加更多副本不会影响复制延迟。异步复制的良好用例包括部署用于读取扩展的读取副本、用于灾难恢复的实时备份副本以及分析/报告。
作为半同步
MySQL 还支持半同步复制,其中 master 不会向客户端确认事务,直到至少有一个 slave 将更改复制到其中继日志并将其刷新到磁盘。要启用半同步复制,需要额外的插件安装步骤,并且必须在指定的 MySQL 主从节点上启用。
对于高可用性和无数据丢失很重要的许多情况,半同步似乎是一个很好且实用的解决方案。但是您应该考虑半同步由于额外的往返行程而对性能产生影响,并且不能提供防止数据丢失的强有力保证。当一个 commit 成功返回时,就知道数据至少存在于两个地方(在 master 和至少一个 slave 上)。如果 master 提交但在 master 等待从属设备的确认时发生崩溃,则事务可能尚未到达任何从属设备。这不是什么大问题,因为在这种情况下提交不会返回到应用程序。应用程序的任务是在将来重试事务。重要的是要记住,当主节点失败并且从节点被提升时,旧的 master 不能加入复制链。在某些情况下,这可能会导致与从站上的数据冲突(当主站在从站收到二进制日志事件后但在主站收到从站确认之前崩溃时)。因此,唯一安全的方法是丢弃旧 master 上的数据,并使用来自新提升 master 的数据从头开始提供。
熟能生巧
我们已经偏离了 MySQL 复制的工作原理。我们必须处理它的不完善之处以及如何应用它来根据您的需要调整您的 MySQL 数据库环境。在这篇博客中,我们将看看 MySQL 数据库专家倾向于管理和应用最佳实践的领域,这些实践应该在我们的数据库系统上处理,尤其是在生产环境中时。
错误地使用复制格式
从 MySQL 5.7.7 开始,默认的二进制日志格式或 binlog_format 变量使用 ROW,即 5.7.7 之前的 STATEMENT。不同的复制格式对应于在源的二进制日志中记录事件时使用的方法。复制之所以有效是因为写入二进制日志的事件是从源读取然后在副本上处理的。根据事件的类型,事件以不同的复制格式记录在二进制日志中。不知道确定使用什么可能是一个问题。MySQL 有三种不同格式的复制方法可供使用:STATEMENT、ROW 和 MIXED。
-
基于 STATEMENT 的复制 (SBR) 格式正是它的样子:在主节点上运行的每个语句的复制流,这些语句将在从节点上重放。默认情况下,MySQL 传统(异步)复制不会并行执行复制到从服务器的事务。这意味着复制流中的语句顺序可能不是 100% 相同。同样,重放语句可能会在不与从源执行时完全相同的时间执行时给出不同的结果。这会导致主服务器及其副本的状态不一致。多年来,这都不是问题,因为没有多少人同时运行 MySQL 和许多并发线程,但是对于现代多 CPU 架构,这实际上在正常的日常工作负载中变得非常有可能。
-
ROW 复制格式提供了 SBR 所缺乏的解决方案。使用基于行的复制 (RBR) 日志记录格式时,源将事件写入二进制日志,指示单个表行的更改方式。将源复制到副本的工作方式是将表示表行更改的事件复制到副本。这意味着可以生成更多数据,这可能会影响副本中的磁盘空间,还会影响网络流量和磁盘 I/O。考虑如果一个语句更改了许多行,假设使用 UPDATE 语句,即使对于回滚的语句,RBR 也会将更多数据写入二进制日志。运行时间点快照也可能需要更多时间。考虑到将大量数据写入二进制日志所需的锁定时间,并发问题可能会出现。
-
那么在这两者之间还有一个方法:混合模式复制。这种类型的复制将始终复制语句,除非查询包含 UUID() 函数、触发器、存储过程、UDF 和一些其他例外情况。混合模式不能解决数据漂移问题,应该避免与基于语句的复制一起使用。
计划进行多主机设置?
循环复制(也称为环形拓扑)是 MySQL 复制的一种已知且常见的设置。如果您正在运行多主设置(见下图),这是众所周知的并已实践过。如果您有一个多数据中心环境,这通常是必要的。由于应用程序无法等待其他数据中心的主节点确认写入,因此首选本地主节点。通常使用自动增量偏移来防止主设备之间的数据冲突。让两个 master 以这种方式相互写入是一种被广泛接受的解决方案。
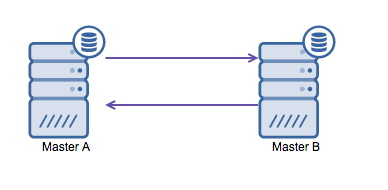
但是,如果您需要将多个数据中心写入同一个数据库中,您最终会遇到多个需要相互写入数据的主服务器。在 MySQL 5.7.6 之前,没有方法进行网状复制,因此替代方法是使用圆环复制。
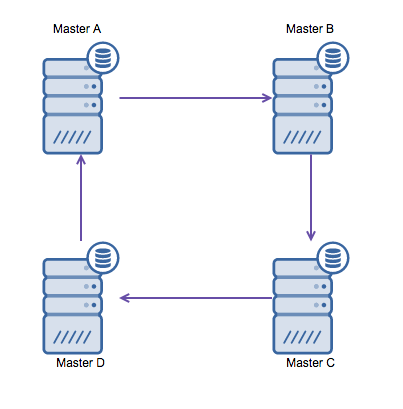
MySQL 中的环形复制存在问题,原因如下:延迟、高可用性和数据漂移。向服务器 A 写入一些数据,最终到达服务器 D 需要三跳(通过服务器 B 和 C)。由于(传统的)MySQL 复制是单线程的,复制中的任何长时间运行的查询都可能会拖延整个环。此外,如果任何服务器出现故障,环就会损坏,目前还没有可以修复环结构的故障转移软件。那么当数据写入服务器 A 并同时在服务器 C 或 D 上更改时,可能会发生数据漂移。
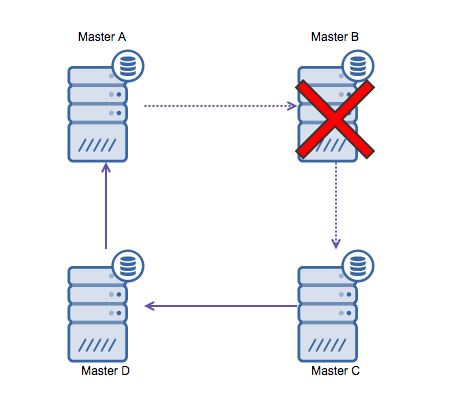
一般来说,循环复制不适合 MySQL,应该不惜一切代价避免它。Galera Cluster 是多数据中心写入的一个很好的选择,因为它的设计考虑到了这一点。
用大更新拖延你的复制
通常,各种内务批处理作业将执行各种任务,从清理旧数据到计算从另一个来源获取的“喜欢”的平均值。这意味着在设定的时间间隔内,作业将创建大量数据库活动,并且很可能会将大量数据写回数据库。自然,这意味着复制流中的活动将同样增加。
基于语句的复制将复制批处理作业中使用的确切查询,因此如果查询在主服务器上处理需要半小时,从属线程将至少停滞相同的时间。这意味着没有其他数据可以复制,从节点将开始落后于主节点。如果这超出了故障转移工具或代理的阈值,它可能会从集群中的可用服务器中删除这些从节点。如果您使用基于语句的复制,则可以通过以较小的批次处理作业的数据来防止这种情况发生。
现在,您可能认为基于行的复制不受此影响,因为它将复制行信息而不是查询。这在一定程度上是正确的,因为对于 DDL 更改,复制将恢复为基于语句的格式。此外,大量 CRUD 操作会影响复制流:在大多数情况下,这仍然是单线程操作,因此每个事务都将等待通过复制重放前一个事务。这意味着如果您在主服务器上具有高并发性,则从服务器可能会在复制期间因事务过载而停顿。
为了解决这个问题,MariaDB 和 MySQL 都提供了并行复制。实施可能因供应商和版本而异。只要查询由模式分隔,MySQL 5.6 就提供并行复制。MariaDB 10.0 和 MySQL 5.7 都可以处理跨模式的并行复制,但有其他边界。如果你写的很重,通过并行从线程执行查询可能会加速你的复制流,否则,最好坚持传统的单线程复制。
处理您的架构更改或 DDL
自 5.7 发布以来,管理 MySQL 中的架构更改或 DDL(数据定义语言)更改已得到很大改进。在 MySQL 8.0 之前,支持的 DDL 更改算法是 COPY 和 INPLACE。
- COPY:该算法使用更改后的模式创建一个新的临时表,一旦它将数据完全迁移到新的临时表,它就会交换并删除旧表。
- INPLACE:该算法对原始表执行就地操作,并尽可能避免表复制和重建。
在 MySQL 8.0 中,引入了 INSTANT 算法,它可以对列添加进行即时和就地表更改,并允许并发 DML,在繁忙的生产环境中提高响应能力和可用性。这有助于避免副本中的巨大滞后和停顿,这在应用程序方面通常是大问题,导致由于滞后而导致从站中的读取尚未更新而导致检索陈旧数据。
尽管这是一个很有希望的改进,但它们仍然存在局限性,有时无法应用那些 INSTANT 和 INPLACE 算法。例如,更改列的数据类型这也是一种常见的更改,尤其是在开发角度由于数据更改。这些情况是不可避免的,因此您不能继续使用 COPY 算法,因为这会锁定表,导致从站延迟,并且在此执行期间还会影响主/主服务器,因为它堆积了同样引用受影响表的传入事务. 您不能在繁忙的服务器上执行直接的 ALTER 或架构更改,因为这会伴随停机时间,或者如果您失去耐心,尤其是在目标表很大的情况下,可能会损坏您的数据库。
确实,在正在运行的生产设置上执行架构更改总是很痛苦。一个常用的解决方法是首先将架构更改应用于从节点。对于基于语句的复制,这可以正常工作,但对于基于行的复制,这可以在一定程度上起作用。基于行的复制允许在表的末尾存在额外的列,所以只要它能够写入第一列就可以了。首先将更改应用于所有从站,然后故障转移到其中一个从站,然后将更改应用于主站并将其附加为从站。如果您的更改涉及在中间插入一列或删除一列,这将适用于基于行的复制。
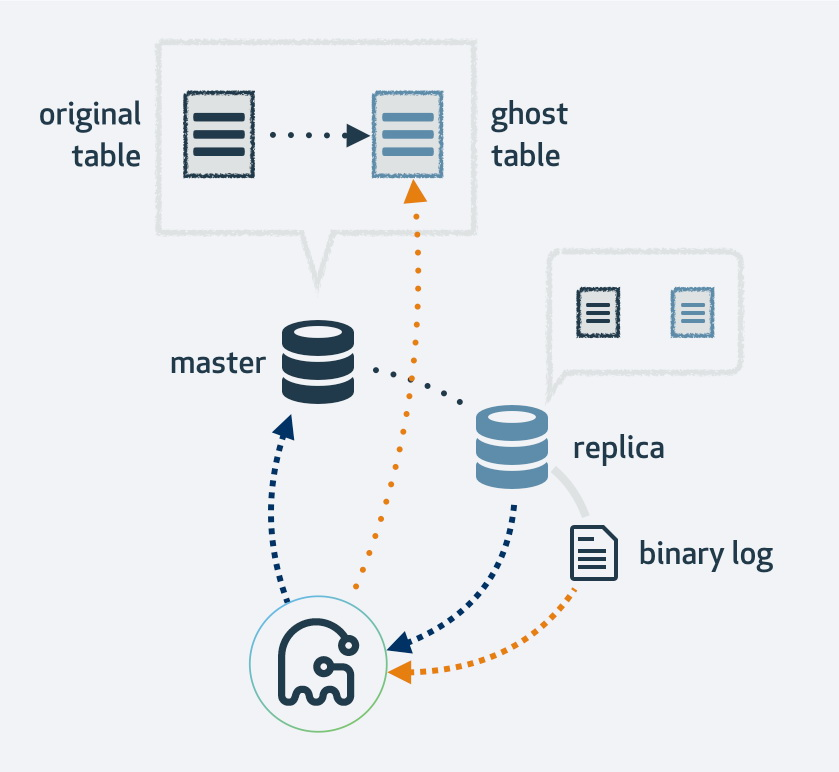
有一些工具可以更可靠地执行在线模式更改。通常使用的的DBA的Percona的在线模式变更(已知为PT-OSC)和GH-OST通过Schlomi Noach。这些工具通过将受影响的行分组为块来有效地处理架构更改。而这些块可以根据您要分组的数量进行相应配置。
如果您打算使用 pt-osc 跳转,此工具将创建一个具有新表结构的影子表,通过触发器插入新数据并在后台回填数据。完成创建新表后,它将在事务中简单地将旧表替换为新表。这并不适用于所有情况,特别是如果您现有的表已经有触发器。

而使用 gh-ost,它会首先复制您现有的表布局,将表更改为新布局,然后将该过程作为 MySQL 副本连接起来。它将利用复制流来查找已插入到原始表中的新行,同时回填表。完成回填后,原始表和新表将切换。自然地,对新表的所有操作也将在复制流中结束,因此在每个副本上,迁移同时发生。
内存表和复制
当我们讨论 DDL 时,一个常见的问题是内存表的创建。内存表是非持久化表,其表结构保持不变,但在MySQL重启后数据丢失。在 master 和 slave 上创建新的内存表时,它们将有一个空表,这将工作得很好。一旦其中任何一个被重新启动,该表将被清空并发生复制错误。
一旦slave节点的数据返回不同的结果,基于行的复制就会中断,而当试图插入已经存在的数据时,基于语句的复制就会中断。对于内存表,这是一个频繁的复制破坏者。修复很简单:制作数据的新副本,将引擎更改为 InnoDB,现在它应该是复制安全的。
设置 read_only={True|1}
当您使用环形拓扑时,这当然是一种可能的情况。然而,如果可能,我们不鼓励使用环形拓扑。我们之前描述过,从节点中没有相同的数据会破坏复制。通常,这是由某些(或某人)更改从节点上的数据而不是主节点上的数据引起的。一旦主节点的数据被更改,这将被复制到无法应用更改的从属节点,这会导致复制中断。这也可能导致集群级别的数据损坏,特别是如果从站已升级或因崩溃而故障转移。那可能是一场灾难。
一个简单的预防方法是确保 read_only 和 super_read_only(仅在 > 5.6 上)设置为 ON 或 1。您可能已经了解这两个变量的不同之处以及如果禁用或启用它们会产生什么影响。禁用 super_read_only(自 MySQL 5.7.8 起),这允许 root 用户防止目标或副本中的任何更改。因此,当两者都被禁用时,这将禁止任何人对数据进行更改,复制除外。大多数故障转移管理器,例如ClusterControl,会自动设置此标志以防止用户在故障转移期间写入使用的主服务器。他们中的一些人甚至在故障转移后保留了这一点。
启用 GTID
在 MySQL 复制中,必须从二进制日志中的正确位置启动从站。可以在进行备份(xtrabackup 和 mysqldump 支持此功能)或停止在要复制的节点上进行从属时获得此位置。使用 CHANGE MASTER TO 命令开始复制将如下所示:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;
复制在错误的位置开始复制可能会产生灾难性的后果:数据可能被重复写入或未更新。这会导致主节点和从节点之间的数据漂移。
此外,当将主设备故障转移到从设备时,需要找到正确的位置并将主设备更改为适当的主机。MySQL 不会保留其 master 的二进制日志和位置,而是创建自己的二进制日志和位置。为了将一个从节点重新对齐到新的主节点,这可能会成为一个严重的问题:必须在新的主节点上找到主节点在故障转移时的确切位置,然后才能重新对齐所有从节点。
为了解决这个问题, Oracle MySQL 和 MariaDB 都实现了全局事务标识符(GTID)。GTID 允许自动对齐从站,服务器自行确定正确的位置。但是,两者都以不同的方式实现了 GTID,因此不兼容。如果需要设置从一个到另一个的复制,复制应该设置为传统的二进制日志定位。此外,您的故障转移软件应注意不要使用 GTID。
崩溃安全从站
崩溃安全意味着即使从属 MySQL/OS 崩溃,您也可以恢复从属并继续复制,而无需将 MySQL 数据库恢复到从属上。为了让崩溃安全的 slave 工作,你只需要使用 InnoDB 存储引擎,并且在 5.6 中你需要设置relay_log_info_repository=TABLE 和relay_log_recovery=1。
结论
熟能生巧,但如果没有这些重要技术的适当培训和知识,它可能会很麻烦或可能导致灾难。MySQL专家通常遵循这些做法,并且在管理生产数据库服务器中的 MySQL 复制时,大型行业将其作为日常工作的一部分进行调整。
