




今天介绍一种可以让查询速度更快, 代码更简洁,省去记忆大量的 Pandas 命令的方法。
或许你听说过 pandasql(或者 sqldf),这里说的不是它,因为它太慢了。
为了方便理解,做了三种方法的对比, 分别为直接对 DuckDB 的表(视图)进行 SQL 操作、Pandas API 以及把 Pandas DataFrame 当做表,通过 SQL 操作。
环境:Notebook
准备工作
下载数据
wget -q https://github.com/cwida/duckdb-data/releases/download/v1.0/lineitemsf1.snappy.parquetwget -q https://github.com/cwida/duckdb-data/releases/download/v1.0/orders.parquet复制
安装包
!pip install pandasql ipython-sql duckdb-engine==0.1.8rc4 duckdb ipython-autotime复制
导入包及初始化
#自动计算运行时间%load_ext autotime#下面6行和ipython-sql有关%load_ext sql%config SqlMagic.autopandas=True%config SqlMagic.feedback = False%config SqlMagic.displaycon = False%sql duckdb:///:memory:%sql pragma threads=4#导入必要的包import pandas as pdimport numpy as npfrom pandasql import sqldffrom duckdb import query#方便需要定义的两个函数sqlite = lambda q: sqldf(q, globals())ducksql= lambda q: query(q).df()复制
准备数据
DuckDB 以两种方式测试,第一种,通过创建视图的方式,直接访问 parquet 文件,不把数据放内存
%%sqlcreate view lineitem as select * from 'lineitemsf1.snappy.parquet';create view orders as SELECT * FROM 'orders.parquet';show tables;#返回 name0 lineitem1 orders复制
第二种方式就是把 parquet 加载到 DataFrame,然后 SQL on Pandas DataFrame
lineitem_df = %sql SELECT * FROM 'lineitemsf1.snappy.parquet'orders_df = %sql SELECT * FROM 'orders.parquet'复制
对比测试
count
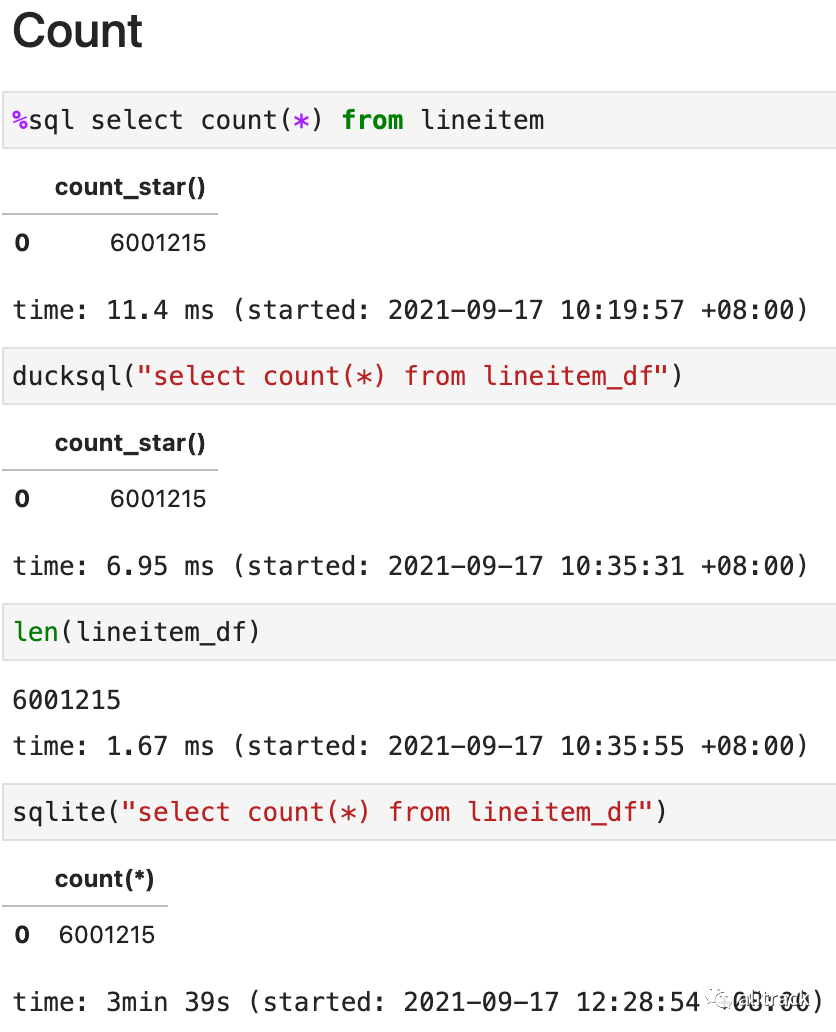
这一步 pandasql 基本就可以出局了,太慢了。
Limit
%sql select * from lineitem limit 5 # 60.9msducksql("select * from lineitem_df limit 5") #23.5mssqlite("select * from lineitem_df limit 5") #3m 57slineitem_df.head(5) #13ms复制
这一轮, pandas 胜,pandasql 最慢,接下来放弃它了
选取部分列
lineitem_df[['l_shipdate','l_extendedprice','l_quantity','l_partkey']].head() #271ms%sql select l_shipdate,l_extendedprice,l_quantity,l_partkey from lineitem limit 5 #18.8msducksql( "select l_shipdate,l_extendedprice,l_quantity,l_partkey from lineitem_df limit 5") #8.1ms复制
pandas 最慢
排序(Sort/Order by)
lineitem_df.sort_values('l_shipdate',ascending=False).head(5) #28sducksql("select * from lineitem_df order by l_shipdate desc limit 5") #1.31s%sql select * from lineitem order by l_shipdate desc limit 5#1.14s复制
查询(Where)
%sql select * from lineitem where l_shipmode ='RAIL' limit 5 #38.5msducksql("select * from lineitem_df where l_shipmode ='RAIL' limit 5") #15.3mslineitem_df.query("l_shipmode =='RAIL'").head()#758ms复制
聚合(Groupby)
%sql select l_shipmode,l_shipinstruct, count(*) as cnt, sum(l_extendedprice*l_quantity) rev from lineitem group by 1,2 order by 3 desc limit 5 # 415msducksql("select l_shipmode,l_shipinstruct, count(*) as cnt, sum(l_extendedprice*l_quantity) rev from lineitem_df group by 1,2 order by 3 desc limit 5") # 866mslineitem_df.assign(rev=lineitem_df["l_extendedprice"] * lineitem_df["l_quantity"]).groupby(['l_shipmode','l_shipinstruct']).agg({"rev": np.sum, "l_shipmode": np.size}).head()#4.45s复制
差距有些大,而且代码很长,需要记忆很多函数写法了。
Join(连接)
这里只测试一个 inner join,其它的有兴趣可以自己来
%%sqlSELECT l_returnflag, l_linestatus, sum(l_extendedprice)FROM lineitemJOIN orders ON (l_orderkey=o_orderkey)WHERE l_shipdate <= DATE '1998-09-02' AND o_orderstatus='O'GROUP BY l_returnflag, l_linestatus复制
ducksql("""SELECT l_returnflag, l_linestatus, sum(l_extendedprice)FROM lineitem_dfJOIN orders_df ON (l_orderkey=o_orderkey)WHERE l_shipdate <= DATE '1998-09-02' AND o_orderstatus='O'GROUP BY l_returnflag, l_linestatus""")复制
pd.merge(lineitem_df.query("l_shipdate <= '1998-09-02'")[['l_returnflag','l_orderkey','l_linestatus','l_extendedprice']], orders_df.query("o_orderstatus=='O'")[['o_orderkey']],how='inner', left_on='l_orderkey',right_on='o_orderkey')\.groupby(['l_returnflag','l_linestatus']).agg(sum=('l_extendedprice','sum'))复制
| Method | Time |
|---|---|
| View | 518ms |
| SQL on DataFrame | 854ms |
| Pandas | 6.13s |
Union(合并)
union all(不去重)
pd.concat([lineitem_df.query("l_shipdate =='1992-01-02' and l_shipmode =='FOB'"), lineitem_df.query("l_shipdate <='1992-01-03' and l_shipmode =='FOB'")],axis=0)#1.67s复制
%%sqlselect * from lineitem where l_shipdate ='1992-01-02' and l_shipmode ='FOB'union allselect * from lineitem where l_shipdate <='1992-01-03' and l_shipmode ='FOB'#1.74s复制
ducksql("""select * from lineitem_df where l_shipdate ='1992-01-02' and l_shipmode ='FOB'union allselect * from lineitem_df where l_shipdate <='1992-01-03' and l_shipmode ='FOB'""")#2.31s复制
union(去重)
pd.concat([lineitem_df.query("l_shipdate =='1992-01-02' and l_shipmode =='FOB'"), lineitem_df.query("l_shipdate <='1992-01-03' and l_shipmode =='FOB'")],axis=0).drop_duplicates()# 1.16s复制
%%sqlselect * from lineitem where l_shipdate ='1992-01-02' and l_shipmode ='FOB'unionselect * from lineitem where l_shipdate <='1992-01-03' and l_shipmode ='FOB'#1.75s复制
ducksql("""select * from lineitem_df where l_shipdate ='1992-01-02' and l_shipmode ='FOB'unionselect * from lineitem_df where l_shipdate <='1992-01-03' and l_shipmode ='FOB'""")# 2.51s复制
开窗函数(Window Function)
row_number()
%%sqlSELECT * FROM ( SELECT t.*, ROW_NUMBER() OVER(PARTITION BY l_shipdate ORDER BY l_extendedprice DESC) AS rn FROM lineitem t)WHERE rn =1ORDER BY l_extendedprice, rn;#14s复制
ducksql("""SELECT * FROM ( SELECT t.*, ROW_NUMBER() OVER(PARTITION BY l_shipdate ORDER BY l_extendedprice DESC) AS rn FROM lineitem_df t)WHERE rn =1ORDER BY l_extendedprice, rn;""")#37.8s复制
( lineitem_df.assign( rn=lineitem_df.sort_values(["l_extendedprice"], ascending=False) .groupby(["l_shipdate"]) .cumcount() + 1 ) .query("rn ==1") .sort_values(["l_shipdate", "rn"]))#24.6s复制
( lineitem_df.assign( rnk=lineitem_df.groupby(["l_shipdate"])["l_extendedprice"].rank( method="first", ascending=False ) ) .query("rnk == 1") .sort_values(["l_shipdate", "rnk"]))# 5.81s,这个快很多复制
rank
%%sqlSELECT * FROM ( SELECT t.*, RANK() OVER(PARTITION BY l_shipmode ORDER BY l_quantity) AS rnk FROM lineitem t where l_quantity<10)WHERE rnk < 3
ORDER BY l_shipmode, rnk;
#3.03s复制
ducksql("""
SELECT * FROM (
SELECT
t.*,
RANK() OVER(PARTITION BY l_shipmode ORDER BY l_quantity) AS rnk
FROM lineitem_df t
where l_quantity<10
)
WHERE rnk < 3
ORDER BY l_shipmode, rnk;
""")
#4.17复制
(
lineitem_df[lineitem_df["l_quantity"] < 10]
.assign(rnk_min=lineitem_df.groupby(["l_shipmode"])["l_quantity"].rank(method="min"))
.query("rnk_min < 3")
.sort_values(["l_shipmode", "rnk_min"])
)
# 3.31复制
更新(UPDATE)与删除(DELETE)
SQL on DataFrame 不支持。
从上面的例子可以看出,使用 SQL on DataFrame, 省去了记忆复杂 Pandas 的函数、速度也比较保证(复杂的 SQL 反而快很多),另外如果数据比较大,还是建议直接放在 DuckDB 数据库里,不用担心丢失、节省内存,还保证速度,只在需要的时候才把数据取出来。
文章转载自alitrack,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
数据库国产化替代深化:DBA的机遇与挑战
代晓磊
1279次阅读
2025-04-27 16:53:22
2025年4月国产数据库中标情况一览:4个千万元级项目,GaussDB与OceanBase大放异彩!
通讯员
757次阅读
2025-04-30 15:24:06
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
623次阅读
2025-04-14 09:40:20
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
525次阅读
2025-04-17 17:02:24
一页概览:Oracle GoldenGate
甲骨文云技术
486次阅读
2025-04-30 12:17:56
GoldenDB数据库v7.2焕新发布,助力全行业数据库平滑替代
GoldenDB分布式数据库
477次阅读
2025-04-30 12:17:50
优炫数据库成功入围新疆维吾尔自治区行政事业单位数据库2025年框架协议采购!
优炫软件
365次阅读
2025-04-18 10:01:22
给准备学习国产数据库的朋友几点建议
白鳝的洞穴
339次阅读
2025-05-07 10:06:14
XCOPS广州站:从开源自研之争到AI驱动的下一代数据库架构探索
韩锋频道
301次阅读
2025-04-29 10:35:54
国产数据库图谱又上新|82篇精选内容全览达梦数据库
墨天轮编辑部
283次阅读
2025-04-23 12:04:21
