






本文主要介绍HBase中Region的7种切分策略,和切分策略的设置方法。

一、Region的切分策略
HBase 中创建表时,如果不指定预分区,默认只生成一个Region,当Region大小(准确说应该是Region中最大的Store)达到一定阈值时,会进行Region的切分。以2.2.2版本为例,可以看到RegionSplitPolicy有7个子类:
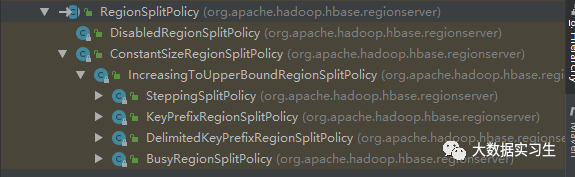
1.ConstantSizeRegionSplitPolicy:固定大小切分策略(0.94版本之前默认切分策略)
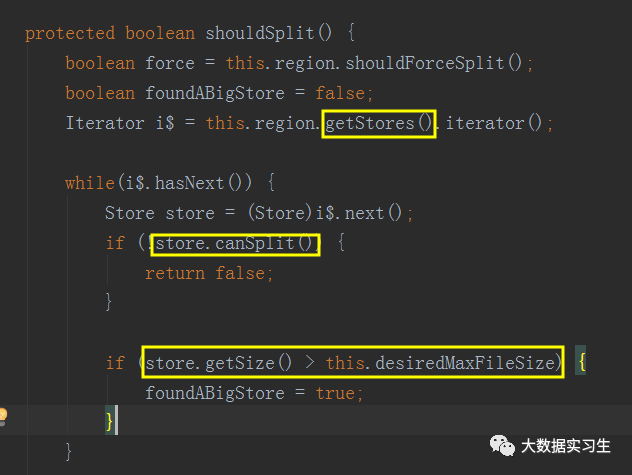
shouldSplit()方法判断Region是否应该被切分。会先获取Region中所有的Store,然后判断Store是否可以被切分,如果不可以,直接返回false,不进行切分;如果所有Store都可以切分,会看最大的Store的大小是否超过desiredMaxFileSize的值,如果超过了,对该Region中的所有Store进行切分。

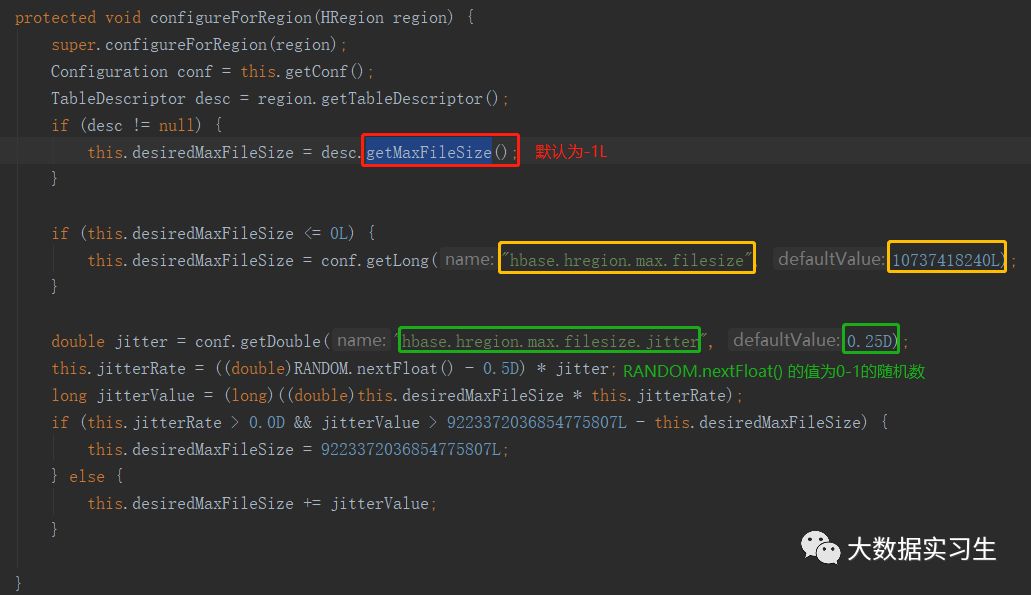
desiredMaxFileSize值的计算:
①先获取表描述器对象,如果用户没有设置,getMaxFileSize()默认为-1L;
②查看是否配置"hbase.hregion.max.filesize",没有的话取默认值10737418240L(10G);
③查看是否配置"hbase.hregion.max.filesize.jitter"参数,这是一个抖动范围,默认为0.25D;
④计算抖动比例:RANDOM.nextFloat()返回一个[0,1)的float数值,所以如果没有设置上面抖动参数的话,抖动比例为[-0.125D,0.125D)
⑤计算抖动值,并根据抖动比例和抖动值计算desiredMaxFileSize的值
当shouldSplit()方法返回true后,会调用getSplitPoint()方法查找切分点,如果是metaRegion或者Region存在引用,则不会进行切分;
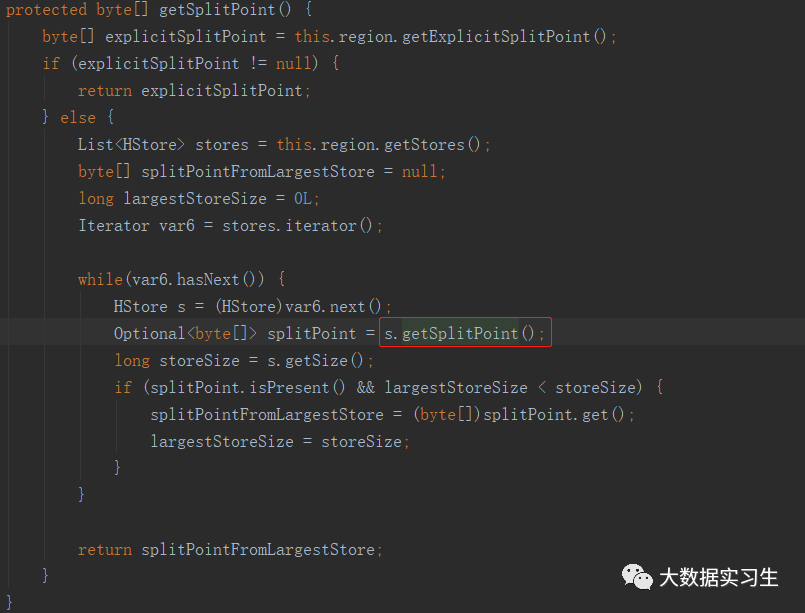
如果用户显示设置了切分点(通过预分区设置),则使用用户定义的切分点;如果没有则取当前Region中最大Store中最大StoreFile的中间块的首行rowkey最为切分点,如果定位到的rowkey为整个Store的首行或尾行,则没有切分点,这种情况下一个Store只有一个文件块,不能再进行切分。

2.IncreasingToUpperBoundRegionSplitPolicy:动态切分策略(0.94-2.0默认切分策略)
固定大小切分策略中,如果切分阈值设置太大,小表可能永远都不会切分;而如果设置太小,大表会分成过多的分片;所以引入动态切分策略。
首先还是调用ShouldSplit()方法,如果每个Store都可切分,会判断Store的大小是否大于阈值sizeToCheck,大于进行切分:
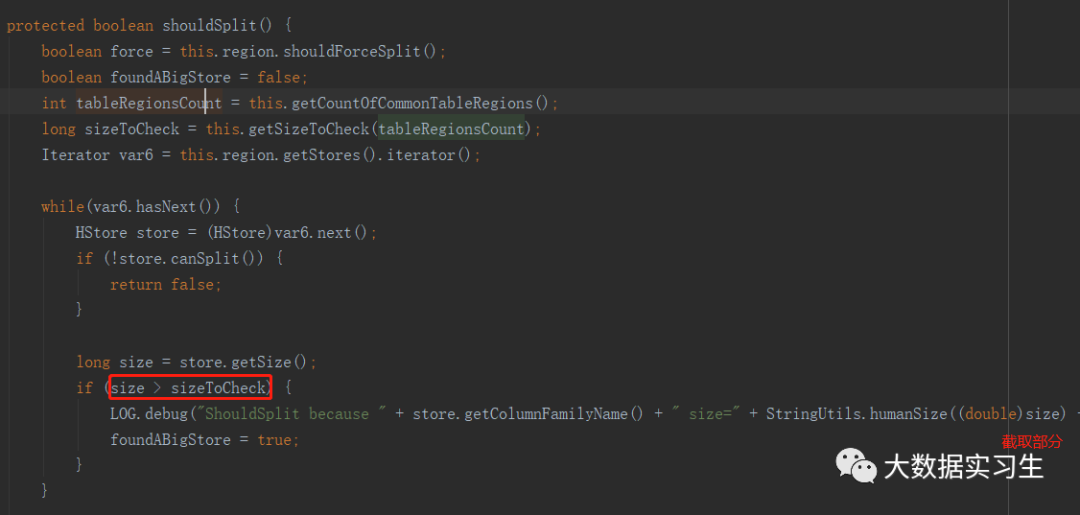
确定切分阈值前,会先计算initialSize,如果参数未设置,默认为2倍“hbase.hregion.memstore.flush.size”:2*128M=256M
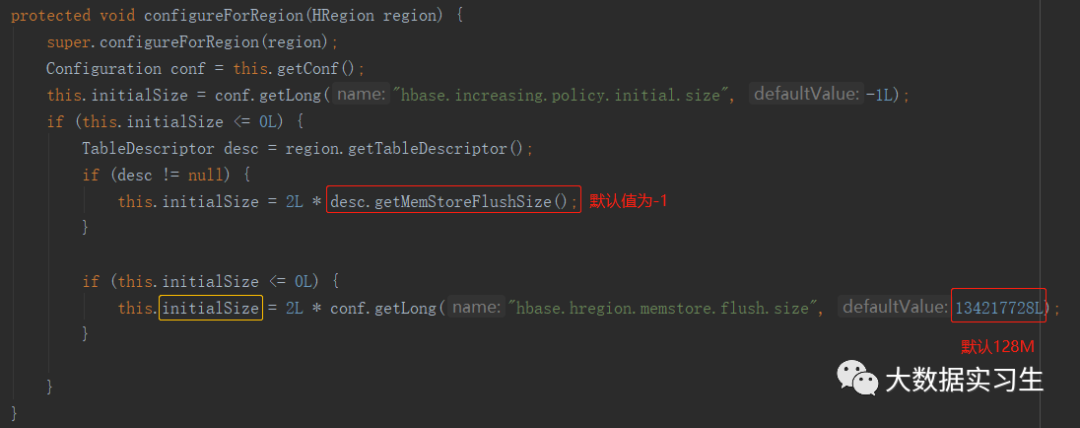
然后根据Region的数量,计算切分阈值:
①如果Region数为0或大于100,仍取固定大小切分中的desiredMaxFileSize值;
②如果Region数为[1,100],取(initialSize和Region数的三次方的乘积)和(固定大小切分中的desiredMaxFileSize值)的较小值。

如果要达到每次切分大小为10G,需要Region数 >=4 :
Region数为1:1^3*256=256M
Region数为2:2^3*256=2048M
Region数为3:3^3*256=6912M
Region数为4:4^3*256=16384M > 10G
之后每次都按10G进行拆分
3.SteppingSplitPolicy:分级切分策略(2.0以后默认切分策略)
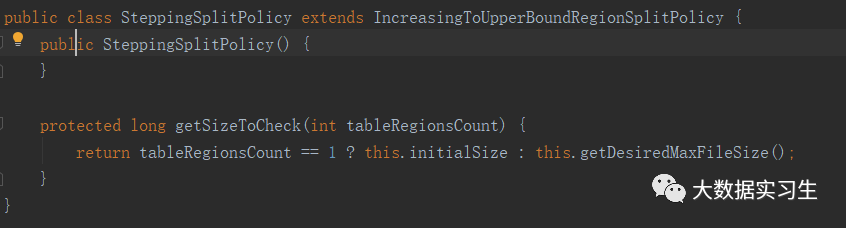
作为IncreasingToUpperBoundRegionSplitPolicy子类,如果Region数为1,切分阈值取initialSize,默认256M;否则取固定大小切分中的desiredMaxFileSize值。
4.KeyPrefixRegionSplitPolicy:固定长度前缀切分策略
源码头部说明:

作为IncreasingToUpperBoundRegionSplitPolicy子类,根据rowkey的前缀进行分组,即指定rowkey的前几位作为前缀,前缀相同的数据切分时分到同一个Region
通过表描述器的“KeyPrefixRegionSplitPolicy.prefix_length”参数控制前缀长度(旧版为“prefix_split_key_policy.prefix_length”参数)
这里通过前缀长度来截取返回的SplitPoint长度,即当前缀长度和SplitPoint均大于0,且SplitPoint长度大于前缀长度时,返回的SplitPoint只取前缀大小长度

5.DelimitedKeyPrefixRegionSplitPolicy:分隔符前缀切分策略
源码头部说明

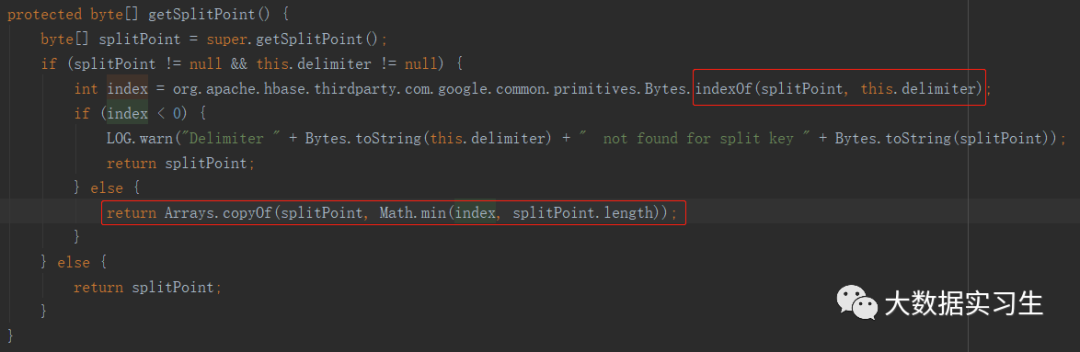
作为IncreasingToUpperBoundRegionSplitPolicy子类,根据rowkey中的分隔符对rowkey切分后进行分组,分隔符左边字符相同的数据分到同一个Region;例如rowkey为userid_eventtype_eventid,且指定了分隔符为下划线_,那么rowkey分割后为userid的数据会分到同一个Region,通过参数“DelimitedKeyPrefixRegionSplitPolicy.delimiter”控制分隔符
根据分隔符的下标,对SplitPoint进行截取
6.BusyRegionSplitPolicy:热点切分策略
如果某个Region某段时间被频繁访问,负载压力大,这段时间内被阻塞的请求数/请求总数超过了一定阈值,且距离上次检测达到一定时间间隔,那么这个Region就被称为热点Region,会被进行切分
控制参数:

①hbase.busy.policy.blockedRequests:请求阻塞率,即请求被阻塞的比例,范围[0.0-1.0],默认0.2。(是判断一个Region是否为热点的主要依据,但不是唯一依据)
②hbase.busy.policy.minAge:拆分最小年龄,当Region大于这个值才拆分,防止判断是否要拆分时短时间的高访问频率导致没必要拆分的Region被拆分,默认600000毫秒,即10分钟。(也就是上次拆分后,如果10分钟内某个Region的请求阻塞率即使达到20%,也不会进行拆分)
③hbase.busy.policy.aggWindow:计算是否为热点Region的时间窗口,默认3000000毫秒,即5分钟,用来控制计算热点Region的频率。
7.DisabledRegionSplitPolicy:手动切分
shouldSplit()方法返回false,即无法进行自动拆分。
具体切分方法后续进行介绍......
二、切分策略的设置
1.通过hbase-site.xml设置全局默认配置:
<property><name>hbase.regionserver.region.split.policy</name><value>org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy</value></property>复制
2.通过hbase shell在建表时设置:
hbase> create 'table_name', {METADATA => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy'}},{NAME => 'column_family'}复制
3.通过API在建表时设置:
通过一个表描述器对象进行设置
HTableDescriptor tableDesc = new HTableDescriptor("table_name");tableDesc.setValue(HTableDescriptor.SPLIT_POLICY, IncreasingToUpperBoundRegionSplitPolicy.class.getName());tableDesc.addFamily(new HColumnDescriptor(Bytes.toBytes("column_family")));admin.createTable(tableDesc);复制
