




前言
上一篇PostgreSQL 12 安装和配置介绍了在 Linux(Redhat Enterprise 7.6) 环境中如何配置和安装 PostgreSQL 数据库,本章节主要讲述如何使用 PostgreSQL。
PostgreSQL 作为多用户多库的面向对象的关系型数据库,通常我们在一台服务器上跑一个 PostgreSQL 数据库,但是有多个数据库,通常一个数据库对应一个数据库名称,为了能够快速识别 DBA 登陆到哪个数据库环境,我们通常在操作系统层面做一些定制化的配置,高效的配置能够实现快速的目录切换,重复执行命令,显查找文件等。
但是要配置高效的环境,离不开我们对操作系统的熟悉。因此,需要我们了解我们使用的操作系统平台。一般的做法是结合操作系统的 SHELL 来实现。
1
定义操作系统命令提示符
在实际的工作环境中,DBA 或者开发人员会打开多个终端窗口,通常使用以下命令可以识别当前的工作窗口:
#显示当前登陆用户
[postgres@sdedu ~]$ hostname
sdedu
#查看当前用户的组及附属组
[postgres@sdedu ~]$ id postgres
uid=2000(postgres) gid=2000(postgres) groups=2000(postgres)
#显示当前用户配置的环境变量
[postgres@sdedu ~]$ env
[postgres@sdedu ~]$ declare
为了能够清晰的区分当前打开的窗口环境,使用以下脚本来定义新打开的终端环境。
在 Linux系统 中,登陆会话读取脚本的环境变量配置目录为 etc/profile.d,因此登陆相关的脚本可以放置在此目录中,如下:
编写脚本如下:
#切换到 etc/profile.d目录下
[root@sdedu ~]# cd etc/profile.d/
#编辑脚本login.sh
#!/bin/bash
echo -e "\033[44;37m Format: hostname@user sep work_dir \033[0m"
userid=$(id | awk '{print $1}' | awk -F'(' '{print $1}' | awk -F'=' '{print $2}')
if [ "${userid}" == "0" ];then
PS1='[\h@\u:$PWD]#'
else
PS1='[\h@\u:$PWD]$'
fi
#保存退出
#切换用户到postgres
[sdedu@root:/root]#su - postgres
Last login: Mon Dec 2 01:52:18 CST 2019 on pts/0
Format: hostname@user sep work_dir
[sdedu@postgres:/home/postgres]$
关于 PS1 变量的配置,如下:
PS1 是操作系统终端环境提示符的显示配置,常用的参数如下:
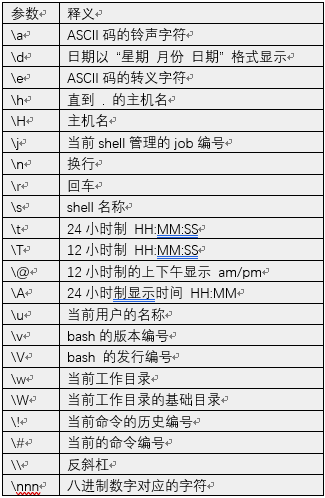
需要注意的是,配置相应的变量不易过长,不然受限于屏幕的显示空间,反而会显得终端里面的字符错乱。
除了 PS1 还有 PS2、PS3、PS4 三个变量也可以定义,但是其作用不同,在此不再赘述。
2
定义PostgreSQL提示符
通常,在 Linux 系统上进入 PostgreSQL 数据库,需要使用psql 数据库,我们知道,PostgreSQL 不同于Oracle(Oracle 11g),是一个多用户多数据库的架构,因此,在 PostgreSQL 服务器上的每一个数据库通常其它用户也具有登录的功能:
如下:
有一个 hr 用户和 hrdb 数据库,使用不同的用户都可以登陆。
#首先使用 postgres 用户登录hrdb
[sdedu@postgres:/home/postgres]$psql -U postgres -d hrdb
psql (12.1)
Type "help" for help.
hrdb=#
#再次使用 hr 用户登录 hrdb
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb
psql (12.1)
Type "help" for help.
hrdb=>
如果以上操作在一个终端中进行了多次DDL,DML,DQL,DCL 等等,通常只能看到 hrdb 数据库,但是不能确认是哪个用户登录的操作,可能对于我们的运维和开发会带来不便,例如:原本要在 hr 用户下的 hrdb 创建一张 wifi 表,结果使用 postgres 用户创建了 wifi 表,那么会导致使用 hr 的用户到 hrdb 中查不到该表信息,开发或运维人员误以为该表不存在,又或者需要 PostgreSQL 中的字典去确认该表信息,带来时间上的浪费,因此,配置一个 SQL 提示符中至少包含用户名和数据库的信息可以减少不必要的时间浪费,所谓工欲善其事,必先利其器。那么如何在 PostgreSQL 中定义 SQL 提示符呢?
以下便为在 PostgreSQL 中定义 SQL 提示符的方法:
切换到 postgres 用户下,在 postgres 家目录下编辑隐藏文件 .psqlrc
#在 home/postgres 目录下编辑隐藏文件 .psqlrc
[sdedu@postgres:/home/postgres]$cat .psqlrc
\set PROMPT1 '%n@%/=>'
#重新读取变量或者重新登录 postgres 用户后,登录数据库
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb
psql (12.1)
Type "help" for help.
hr@hrdb=>
看到 SQL 提示符已经变了,那么以下是列出的常用的一些定义 SQL 提示符的参数
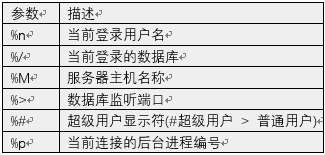
以上几个提示符参数是常用的,对于不常用的如 %R,%x,%l, %~,%digits,%:name:等不再做详细解释。
3
启动和停止 PostgreSQL
启动和停止 PostgreSQL 数据库服务器,通常使用pg_ctl。通常在我们的生产环境中,如果数据库主机发生意外停机或者由于计划内的硬件配置等操作停止了主机后,PostgreSQL 服务也将会停止,需要手动重启。因此,在生产环境中,采用编译安装 PostgreSQL 数据库后,建议配置系统 postgresql.service 服务,通过 systemctl 系统命令设置开机自动启动。
(1)使用 systemctl 命令
#编译安装,该postgresql-12.service需要手动定义
#使用systemctl 命令停止数据库
[sdedu@root:/root]#systemctl stop postgresql-12.service
#使用sytsemctl 命令启动数据库
[sdedu@root:/root]#systemctl start postgresql-12.service
#使用systemctl 命令启用数据库服务开机后自动启动
[sdedu@root:/root]#systemctl enable postgresql-12.service
Created symlink from etc/systemd/system/multi-user.target.wants/postgresql-12.service to usr/lib/systemd/system/postgresql-12.service.
(2)使用 pg_ctl 命令
pg_ctl 命令为 PostgreSQL 服务端应用程序,可以用来初始化,启动和停止及控制 PostgreSQL 服务器。
pg_ctl 语法格式:
pg_ctl init[db]|start|stop|restart|reload|status
[ -D datadir] [ -s] [ -o initdb-options]
以上为常用的控制 PostgreSQL 服务器的关键词
datadir 为存放 PostgreSQL 数据库相关文件的数据目录
通常 init[db] 在我们初始化新的 PostgreSQL 数据库服务器时使用,也作为不常用参数。
start:启动服务器
stop:停止服务器
restart:重启服务器
reload:重新加载 postgresql.conf 或 pg_hba.conf 文件
status:查看服务器是否在指定的数据目录运行。
可选参数:
-D datadir:指定数据库相关文件的数据目录,如果省略,默认读取 PGDATA 环境变量
-l filename:将服务器日志输出追加到 filename中,也叫做服务器日志文件。如果该文件的 umask 设置为077,访问日志文件默认情况下其它用户不可读。
-m mode:指定关闭数据库的模式,有三个选项,smart,fast,immediate,省略默认为fast
-s:静默输出,仅仅输出错误消息
-t:指定等待操作完成的最大延时秒数。默认为 PGCTLTIMEOUT 环境变量的值,如果省略,默认60秒
-w:等待操作完成,如果操作在延迟时间内未完成,pg_ctl 退出状态为非零
-W:不等待操作完成,不会提示数据库停止是否完成
示例:启动和停止数据库
#停止数据库服务
[sdedu@postgres:/home/postgres]$pg_ctl stop -D data/pgsql/pgdata/ -l tmp/logfile
waiting for server to shut down.... done
server stopped
#启动数据库服务
[sdedu@postgres:/home/postgres]$pg_ctl start -D data/pgsql/pgdata/ -l tmp/logfile
waiting for server to start.... done
server started
4
熟悉两个文件
pg_hda.conf 和 postgresql.conf
(1) pg_hba.conf
该文件是 PostgreSQL 允许非本地服务器连接(远程服务器)连接的配置文件。该文件中主要记录了允许哪些网段的主机可以连接 PostgreSQL 数据库服务器,除了在这里面配置 PostgreSQL 允许连接的网段主机外,还需要结合 postgresql.conf 参数配置文件,启用非本地接口上的监听配置参数。
注意:在该文件中,配置允许主机连接的格式如下:
TYPE DATABASE USER ADDRESS METHOD
第一列TYPE为连接类型
local 为本地连接主机(仅为本地unix 域套接字连接)
host 为远程连接主机
第二列DATABASE为所连接的数据库
all 表示可连接所有数据库
第三列 USER 为所连接服务器的用户名
all 表示所有用户
第四列 ADDRESS 表示连接的主机网段
IPV4网络地址网段分配为 0 – 32
IPV6网络地址网段分配为 128
第五列 METHOD 认证方式
认证方式有"trust", "reject", "md5", "password", "scram-sha-256","gss", "sspi", "ident", "peer", "pam", "ldap", "radius" or "cert"等,通常使用 md5 或者scram-sha-256的认证方式
如果使用 trust ,所有远程连接到数据库服务器主机的数据库都不经过密码验证。
本试验环境中的配置如下:
local all all trust
host all all 127.0.0.1/32 trust
host all all 10.10.20.0/24 md5
host all all ::1/128 trust
local replication all trust
host replication all 127.0.0.1/32 trust
host replication all ::1/128 trust
以上述中 host all all 10.10.20.0/24 md5为例表示仅限 10.10.20.0 – 10.10.20.255之间的IP地址连接,其中0,1,255为特殊地址,不使用,即最大可用连接主机为 254 个。
(2) postgresql.conf
该文件是 PostgreSQL 的参数文件,该文件中配置了 PostgreSQL 启动所读取的初始化参数,如果没有指定初始化参数,使用默认的初始化参数启动。类似于 Oracle 中的初始化参数文件。在这里仅仅解释与本文相关的 listen_addresses 参数。
listen_addresses 参数有两个选项列表,如果使用localhost 表示仅仅监听本地主机的连接,如果使用 * 号,表示监听所有待连接的主机地址。该参数要求重启PostgreSQL服务器后生效,属于静态参数。
本文环境配置为 listen_addresses = '*'
关于远程连接到 PostgreSQL 数据库服务器,必须配置 pg_hba.conf 文件和 postgresql.conf 中的listen_addresses 参数,否则仅在 pg_hba.conf 文件中配置了远程连接主机的IP地址网段,而 postgresql.conf 中的 listen_addresses 配置为 localhost,远程连接将会失败。
5
psql 命令
psql 命令是与 PostgreSQL 服务器交互的客户端程序,要登录到数据库服务器,需要使用psql 客户端工具或者第三方客户端工具如PostgreSQL for Navicat,pgAdmin,Visualizer 等等。psql 作为 DBA 通常使用的与 PostgreSQL 交互的客户端终端程序,因此,熟悉这个命令的用法可以帮助 DBA 快速的操作和维护数据库。
psql 的默认语法
psql [OPTION]... [DBNAME [USERNAME]]
根据语法,说明 psql 可以直接使用,在 shell 命令行输入 psql,会直接进入数据库,此时的数据库默认用户名是 postgres,默认的数据库是 postgres。
如下:
[sdedu@postgres:/home/postgres]#psql
psql (12.1)
Type "help" for help.
postgres@postgres=>
连接选项:
-U: 数据库用户名
-d: 数据库名称
-h: 远程数据库服务器主机 ip 或 Unix 套接字目录,默认 local
-w: 禁用密码提示
-p: 数据库运行监听端口,默认5432
示例:使用hr用户连接数据库 hrdb。
[sdedu@postgres:/data/pgsql/pgdata]#psql -U hr -d hrdb -p 5432
psql (12.1)
Type "help" for help.
hr@hrdb=>
#通常情况下,远程连接如果没有提供用户名登录密码,那么会提示你输入密码,如下:
[sdedu@postgres:/home/postgres]#psql "host=10.10.20.53 port=5432 user=hr dbname=hrdb"
Password for user hr:
psql (12.1)
Type "help" for help.
hr@hrdb=>
hr@hrdb=>
#如果不需要密码提示,使用-w
[sdedu@postgres:/home/postgres]#psql "host=10.10.20.53 port=5432 user=hr dbname=hrdb" -w
psql: error: could not connect to server: fe_sendauth: no password supplied
#此时客户端会直接提示报错
-c : 执行单行命令。
该命令用于脚本中检测 psql 是否能成功连接到数据库服务器主机时特别有用。
示例:查看数据库 hrdb 是否能远程登陆
[sdedu@postgres:/home/postgres]#psql "host=10.10.20.53 port=5432 user=hr dbname=hrdb password=hr" -c "select 1"
?column?
----------
1
(1 row)
-d: 指定的数据库名称。
示例:登录 hrdb 数据库,此时,不指定用户名,默认使用 postgres 管理员用户登录
[sdedu@postgres:/home/postgres]#psql -d hrdb
psql (12.1)
Type "help" for help.
postgres@hrdb=>
-U: 指定登录的用户名,此时不指定数据库名称,则默认寻找与用户名同名的数据库,因此,通常使用-U参数,需要结合 -d 参数一起使用。
示例如下:使用 hr 用户登录 hrdb 数据库
[sdedu@postgres:/home/postgres]#psql -U hr -d hrdb
psql (12.1)
Type "help" for help.
hr@hrdb=>
-f : 从外部调用脚本文件。
示例:编辑脚本文件 test.sql,写入 SQL 语句或者 PL/pgSQL 存储过程,则可以使用 –f 参数在外部直接调用执行
示例:
[sdedu@postgres:/home/postgres]$cat test.sql
--显示当前日期
SELECT current_date;
--创建一个自定义函数,返回一个整型值
CREATE OR REPLACE FUNCTION test(v1 int)
RETURNS integer AS
$FUNCTION$
BEGIN
RETURN v1 * 100;
END;
$FUNCTION$
LANGUAGE plpgsql;
--调用自定义函数 test,传入参数8
SELECT test(8);
#使用 -f 参数进行外部脚本调用
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -f test.sql
current_date
--------------
2019-12-02
(1 row)
CREATE FUNCTION
test
------
800
(1 row)
-l: 列出可用的数据库后退出。

输入输出选项:
-a: 将脚本中的所有输入都输出,包含 SQL 命令,存储过程和默认的 psqlrc 文件中的命令。
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -ac "SELECT 1"
\set PROMPT1 '%n@%/=>'
SELECT 1
?column?
----------
1
(1 row)
-L: 发送会话日志到指定的文件。
示例:将hr执行的操作和结果保存到 hr.log 文件中
该参数可以帮助 DBA 和开发人员记录操作的历史记录,方便查找和问题定位。
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -c "select 1" -L hr.log
?column?
----------
1
(1 row)
[sdedu@postgres:/home/postgres]$cat hr.log
********* QUERY **********
select 1
**************************
?column?
----------
1
(1 row)
-o: 和-L不同的是,该参数仅仅将当前登录用户的执行操作结果保存到指定的文件,并且不会显示输出到屏幕。
示例:将 hr 用户的执行结果保存到 hr_result.log 文件中
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -c "select 1" -o hr_result.log
[sdedu@postgres:/home/postgres]$cat hr_result.log
?column?
----------
1
(1 row)
-q: 以静默方式运行,没有额外信息显示,只输出查询结果,一般结合 Aqt 一起使用。
示例:以静默方式运行查询结果行
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -Aqt -c "SELECT 1,2"
1|2
-S: 单行模式,SQL 语句只能写在一行,而不能换行,不加该参数,SQL 语句可换行。
示例:使用 -S 仅能将 SQL 语句置于一行
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -S
psql (12.1)
Type "help" for help.
hr@hrdb=>select 1
?column?
----------
1
(1 row)
输出格式选项:
-A: 不对齐输出。
示例:对于查询结果输出使用不对齐显示
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -A -c "SELECT 1"
?column?
1
(1 row)
--csv: 以逗号分隔的表输出模式。
示例:将查询结果以表分隔模式输出
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -A -c "SELECT 1,2" --csv
?column?,?column?
1,2
-F: 域分隔符,默认 |。
示例:指定以 @符号分隔输出
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -A -c "SELECT 1,2" -F'@'
?column?@?column?
1@2
(1 row)
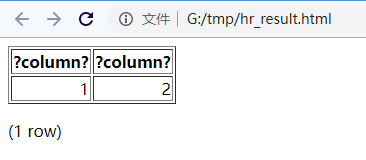
-H: 以HTML表格输出查询结果。
示例:将查询结果以 HTM L表格输出
通常该输出会保存成 html 后缀或者 htm 后缀结尾的文件,以便于对多结果集使用浏览器美化查看。
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -A -c "SELECT 1,2" -H
<table border="1">
<tr>
<th>?column?</th>
<th>?column?</th>
</tr>
<tr valign="top">
<td>1</td>
<td>2</td>
</tr>
</table>
<p>(1 row)<br >
</p>
#保存到html文件
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -A -c "SELECT 1,2" -H > hr_result.html
然后使用浏览器打开
-t: 仅输出结果行。
示例:仅输出结果行
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -A -c "SELECT 1,2" -t
1|2
6
数据库元命令
在psql 中输入的以反斜杠开头的内容都是psql元命令,也叫做反斜杠命令。元命令由psql自身进行处理。
元命令格式为反斜杠后跟参数,如\copy 命令即为元命令,语法格式为
\command [options]
元命令和选项之间可以有一个或者多个空格隔开,如果可选参数中包含了空格,可以用单引号将其引起来,如果是转义字符如: \ n(换行),\ t(制表符),\ b(退格键),\ r(回车),\ f(换页),\ digits(八进制)和\ xdigits(十六进制)都可以使用单引号引起来。
部分元命令以SQL标识符(如表名,函数,序列等)作为参数,这些参数需遵循SQL语法规则:不带引号的字母将被强制小写,双引号之间的字母不进行大小写转换,并允许在标识符中包含空格。在双引号中,成对的双引号会当成单引号使用。
psql 提供了丰富的元命令,如查看数据库对象定义,数据库对象空间大小,导入导出等元命令,以便于DBA或者开发人员能够方便的管理和维护数据库。
下面列出常用的元命令
\c 连接到本地或远程数据库服务器
\c [dbname [usrname] [host] [port] | conninfo]
示例:在postgres用户登录的数据库postgres中使用\c连接到 hr用户的数据库hrdb
[sdedu@postgres:/home/postgres]$psql -U postgres -d postgres
psql (12.1)
Type "help" for help.
postgres@postgres=>\c hrdb hr
You are now connected to database "hrdb" as user "hr".
#也可以远程连接
postgres@postgres=>\c hrdb hr 10.10.20.53 5432
Password for user hr:
You are now connected to database "hrdb" as user "hr" on host "10.10.20.53" at port "5432".
hr@hrdb=>
需要注意的是,第一个参数一定是数据库名称
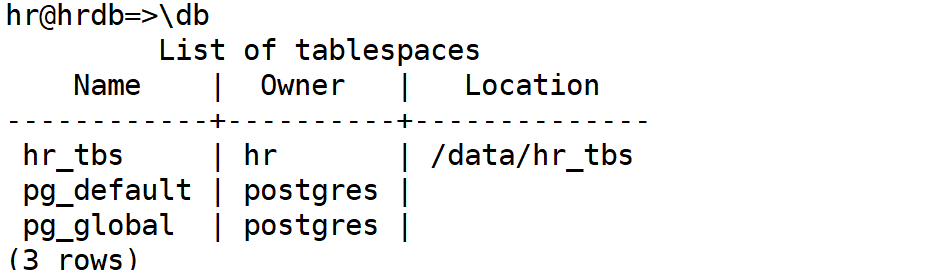
\db: 列出表空间信息
示例:
\d:列出表、视图、序列、或索引

\d后面也可以跟具体的表,视图,序列,索引,函数等对象。
示例:列出函数信息

其它的\d开头的都是其衍生元命令,可以使用\?获取帮助在使用过程中自行查看。
\l:列出数据库信息
示例:列出所有的数据库信息,也可以跟具体的数据库名称

\sf: 查看函数定义信息
示例:列出之前的 test 函数的定义语法
hr@hrdb=>\sf test
CREATE OR REPLACE FUNCTION public.test(v1 integer)
RETURNS integer
LANGUAGE plpgsql
AS $function$
BEGIN
RETURN v1 * 100;
END;
$function$
\sv:列出视图的定义信息
#定义两张表,并各插入两行数据
hr@hrdb=>create table t1(id int,name varchar(20));
CREATE TABLE
hr@hrdb=>create table t2(id int,name varchar(20));
CREATE TABLE
hr@hrdb=>insert into t1 values(1,'a');
INSERT 0 1
hr@hrdb=>insert into t1 values(2,'b');
INSERT 0 1
hr@hrdb=>insert into t2 values(1,'a');
INSERT 0 1
hr@hrdb=>insert into t2 values(3,'c');
INSERT 0 1
#创建视图
hr@hrdb=>create or replace view t_v as
hrdb-> select t1.id,t2.name
hrdb-> from t1,t2
hrdb-> where t1.id = t2.id;
CREATE VIEW
hr@hrdb=>select * from t_v;
id | name
----+------
1 | a
(1 row)
#查看视图定义
--注意,这里\sv可以带+号,也可以不带加号,输出显示将会不同,其它类似,注意即可。
hr@hrdb=>\sv t_v
CREATE OR REPLACE VIEW public.t_v AS
SELECT t1.id,
t2.name
FROM t1,
t2
WHERE t1.id = t2.id
到这里还需要注意的是物化视图,物化视图只能使用\d+ mv_names来查看。
示例:创建物化视图t_mv,并使用\d+来查看其定义
hr@hrdb=>create materialized view t_mv as
hrdb-> select t1.id,t2.name
hrdb-> from t1,t2
hrdb-> where t1.id = t2.id;
SELECT 1
--插入一行新数据
hr@hrdb=>insert into t1 values(3,'c');
INSERT 0 1
--刷新物化视图
hr@hrdb=>refresh materialized view t_mv ;
REFRESH MATERIALIZED VIEW
hr@hrdb=>select * from t_mv;
id | name
----+------
1 | a
3 | c
查看物化视图t_mv的定义
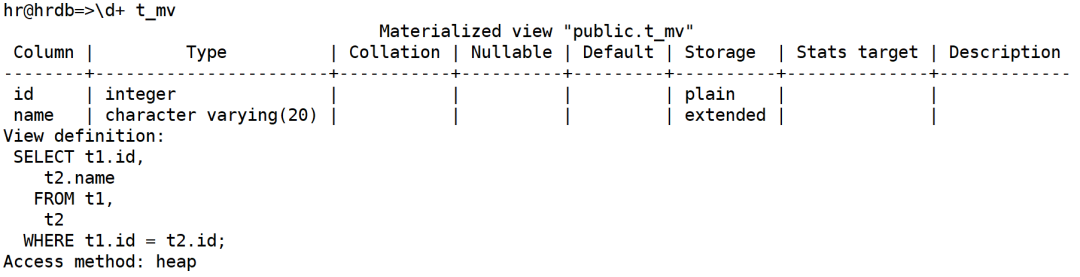
此时如果使用\sv 无法查看物化视图的定义,只能使用\d+来查看定义。
7
数据库中表数据导入导出
psql 客户端提供了即可以将外部平面文本的数据导入到数据库表中,也提供了可以将数据库表导出到外部文件中的方式。copy 和 \copy 都是 psql 支持的数据导入导出的两种方式,但是这两种方式虽然都可以将表数据导入导出,但是又有所不同:
(1)如果登录的数据库用户不具有SUPERUSER的用户,那么无法使用 COPY 命令,只能使用 \copy 命令
示例:将 t1 表中的数据导出到 home/postgres/t1.txt 文件中

示例中,hr 用户不具有 superuser 的权限,所以不能使用 copy 命令
(2)copy 是 SQL 命令,\copy 是 psql 命令
(3)copy 可以读取或者写入远程服务器上的文件,而\copy只能读取和写入 psql 客户端的文件
(4)性能上,一般情况下,copy 性能强于 \copy ,但是如果 copy 读取或者写入远程服务器上的文件,性能受限于其它因素,如网络。
示例:
从 10.10.20.10 服务器上远程读取 10.10.20.53服务器上的表并写入到10.10.20.10服务器的 home/postgres 目录下,当然也可以直接在 10.10.20.53 上读取和写入
#使用copy从 10.10.20.10 服务器上导出表文件到10 服务器本地,使用stdout的方式,该方式并不要求普通用户是否具有superuser的权限就可以直接执行。
#定义提示符
[postgres@sdedu IP:20]export PS1='[\u@\h IP:10]'
#查看IP地址
[postgres@sdedu IP:10]ifconfig ens33 | egrep "inet" | awk '{print $2}' | head -1
10.10.20.10
#从 10.10.20.10服务器登陆 10.10.20.53数据库服务器
[postgres@sdedu IP:10]psql -h 10.10.20.53 -p 5432 -U hr -d hrdb
Password for user hr:
psql (12.012.0, server 12.1)
Type "help" for help.
hrdb=> copy t1 to stdout; --该用户不具有 superuser用户的权限,但是copy后跟stdout便可以执行它
1 a
2 b
3 c
hrdb=> \q
#将10.10.20.53服务器上的表数据重定向到10.10.20.10本地服务器上的文件t1.txt中
[postgres@sdedu IP:10]psql -h 10.10.20.53 -p 5432 -U hr -d hrdb -c "copy t1 to stdout" >> t1.txt
Password for user hr:
#查看输入内容
[postgres@sdedu IP:10]cat t1.txt
1 a
2 b
3 c
#注意:如果直接使用 copy tab_name to path的方式将会报错,如下:
[postgres@sdedu IP:10]psql -h 10.10.20.53 -p 5432 -U hr -d hrdb
Password for user hr:
psql (12.012.0, server 12.1)
Type "help" for help.
hrdb=> copy t1 to '/home/postgres/t1_data.txt';
ERROR: must be superuser or a member of the pg_write_server_files role to COPY to a file
HINT: Anyone can COPY to stdout or from stdin. psql's \copy command also works for anyone.
copy 和 \copy 还有其它的一些可选参数,以下列举常见的一些:
copy 或 \copy 的用法基本上相似,这里列举的参数为SQL 命令中的 copy 参数,这些参数也可以在元命令\copy 中使用。
语法格式:
COPY table_name [ ( column_name [, ...] ) ]
FROM { 'filename' | PROGRAM 'command' | STDIN }
[ [ WITH ] ( option [, ...] ) ]
[ WHE RE condition ]
COPY { table_name [ ( column_name [, ...] ) ] | ( query ) }
TO { 'filename' | PROGRAM 'command' | STDOUT }
[ [ WITH ] ( option [, ...] ) ]
where option can be one of:
FORMAT format_name
FREEZE [ boolean ]
DELIMITER 'delimiter_character'
NULL 'null_string'
HEADER [ boolean ]
QUOTE 'quote_character'
ESCAPE 'escape_character'
FORCE_QUOTE { ( column_name [, ...] ) | * }
FORCE_NOT_NULL ( column_name [, ...] )
FORCE_NULL ( column_name [, ...] )
ENCODING 'encoding_name'
copy 参数描述

以上为常用的一些参数选项。
示例:将t1数据表以逗号分隔的方式导出到平文本文件。
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb
psql (12.1)
Type "help" for help.
hr@hrdb=>\copy t1 to '/home/postgres/t1.txt' DELIMITER ',' NULL AS '';
COPY 3
hr@hrdb=>\q
[sdedu@postgres:/home/postgres]$cat t1.txt
1,a
2,b
3,c
示例:导出 t1 表数据为 t1.csv 文件
hr@hrdb=>copy t1 to stdout null as '' csv ;
1,a
2,b
3,c
注意,使用 csv 时,不要和 delimiter 一起使用,否则 delimiter 将会覆盖 csv 格式。
示例:将t1.txt 文件中的数据导入到表 t1中
[sdedu@postgres:/home/postgres]$cat t1.txt
1 Oracle
2 MySQL
3 PostgreSQL
4 DB2
5 MariaDB
6 SQL Server
7 MongoDB
8 Redis
9 GuassDB
10 Gbase
#使用 copy 的stdin 方式导入数据
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -Aq -c "copy t1 from stdin" <t1.txt
#查看t1 表
[sdedu@postgres:/home/postgres]$psql -U hr -d hrdb -q
hr@hrdb=>SELECT * FROM t1;
id | name
----+------------
1 | a
2 | b
3 | c
1 | Oracle
2 | MySQL
3 | PostgreSQL
4 | DB2
5 | MariaDB
6 | SQL Server
7 | MongoDB
8 | Redis
9 | GuassDB
10 | Gbase
(13 rows)
以上就是常用的 copy 参数的示例,对于其它的格式,自己可以尝试一下。
8
总结
工欲善其事,必先利其器,学习了如何使用 PostgreSQL 后,才能游刃有余的深入 PostgreSQL 数据库,探索数据库价值。
关于我们
中国开源软件推进联盟PostgreSQL分会(简称:PG分会)于2017年成立,由国内多家PG生态企业所共同发起,业务上接受工信部产业发展研究院指导。PG分会致力于构建PG产业生态,推动PG产学研用发展,是国内唯一受官方认可的PG行业协会组织。





