




良心公众号
关注不迷路
01
MySQL架构概述
在之前的文章中,菜鸡曾经总结过MySQL各层级之间的关系,其基本架构可以用下面这张图来大致概括:
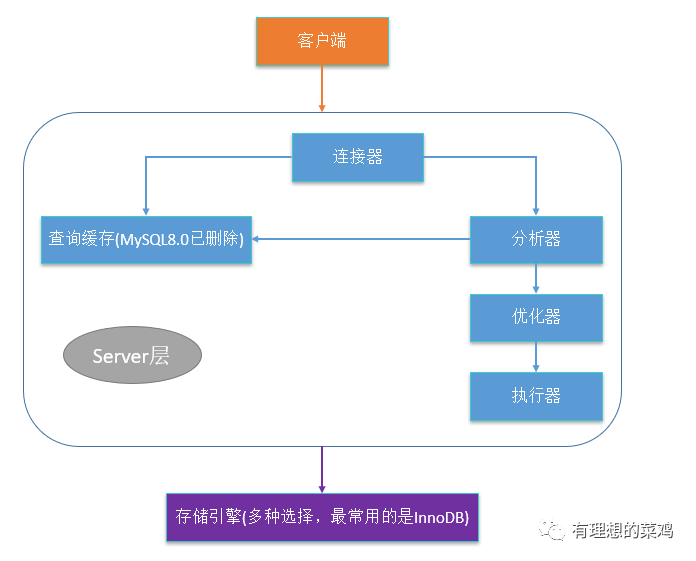
02
binlog和redo log简介
通过上面这张图,我们可以轻松地描述出一次MySQL的读操作在其背后所经历的步骤。而写操作则稍许复杂,因为其涉及到两个极其重要的日志:binlog和redo log。
了解binlog和redo log这两个日志的作用和原理,对我们恢复误操作的数据,数据库横向扩容,以及一些特殊需求(比如业务上要求增量写,则可以通过分析一定时间段内的binlog来实现增量写)有很大的指导意义。不仅如此,这两个日志相辅相成,其背后的设计思想是可以借鉴到日常的开发过程中的。
话不多说,接下来我们来具体看一下这两种日志。
在MySQL的Server层中,有一个极其重要的归档日志,称为binlog。而在InnoDB存储引擎中,也有一个同样重要的重做日志称为redo log。
为什么如此强调其重要性呢?
首先,binlog作为归档日志,它存储了语句的原始逻辑,其主要有两种模式:statement模式和row模式。statement模式记录的是原始sql语句,而row模式记录的是数据行的内容。这意味着,如果需要回滚数据库表,或者进行数据库扩容,binlog将起到重要的作用。binlog写的方式是“追加写”的。
其次,redo log作为重做日志,其记录了在某个数据页所做的修改,通过顺序写代替随机写,降低了IO开销,同时保证了即便数据库崩溃,也不会丢失之前的数据,也即具备了crash-safe的能力。redo log写的方式是“循环写”的。
通过上述的总结,可以得出三点结论:
首先,如果不采用InnoDB存储引擎,则不具备redo log的相关功能,而binlog是属于MySQL的server层的,与选取何种存储引擎无关。
其次,两种日志的侧重点是不一样的,而且其中一个无法完全替代另一个。
进一步地思考,通过binlog和redo log的结合,我们可以将MySQL的状态恢复到这两个日志所保存的任意时间点的状态。之所以能够完成这个目标,是因为同一个写操作的写binlog和写redo log在同一个事务里,也就是说,二者的状态始终能够保持一致。
03
更新操作的流程
我们可以以下面这条MySQL更新语句为例,讲述一下在执行一次更新操作的过程中,binlog和redo log在一次MySQL更新操作中所进行的步骤。
mysql> update table set count = count + 1 where id = 10244201;复制
运行上面这条sql语句,将会依次经过如下步骤:
连接器:客户端与数据库建立连接
分析器:通过“词法分析”和“语法分析”得到这是一条查询语句
优化器:使用id主键索引
执行器:验证更新权限,调用存储引擎接口,找到这一行,然后更新
在此过程中的最后一步,又可以细分为如下步骤:
执行器首先调用存储引擎接口,查询到id = 10244201的这一行数据
将获取到的行数据对应的count字段加1,得到新的行数据,然后调用存储引擎的接口,写入这条更新后的行数据
引擎将新的行数据更新到内存中,同时将这个更新操作记录到redo log里面,然后告知执行器执行结果,此时redo log处于prepare状态
执行器生成该更新操作的binlog,并将binlog写入磁盘
执行器调用引擎的提交事务接口,引擎将redo log改成提交状态,更新完成
上面执行器与存储引擎交互的这个过程中,redo log的这个先prepare后commit的操作,称为两阶段提交,正是这个两阶段提交,保证了binlog和redo log不会因为数据库崩溃等特殊原因而造成恢复数据不一致的问题。
我们如果用一张图对上面的两阶段提交过程加以概括,大致如下:
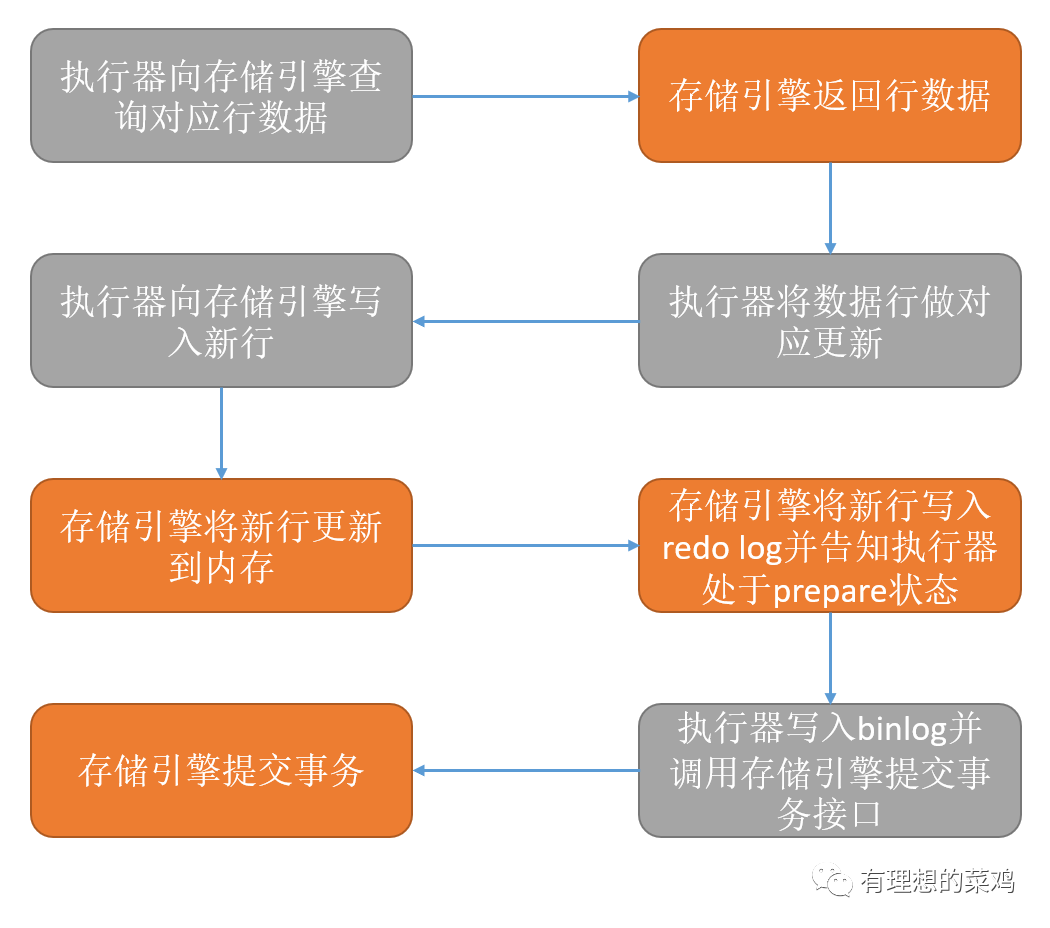
在了解了这个过程之后,对于binlog和redo log所发挥的作用应该会有一个更加深刻的认识,从而能够在日常工作中更加有效地利用它们。
本篇关于binlog和redo log的总结就到这里了。
欢迎大家一起讨论技术,共同成长!
04
推荐阅读

学习 | 工作 | 分享

👆长按关注“有理想的菜鸡”
