




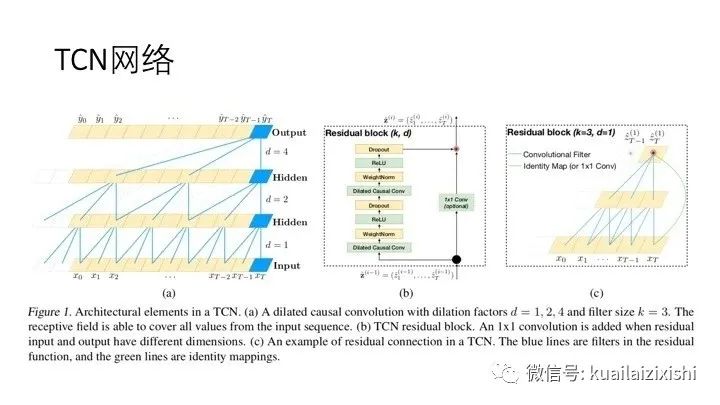
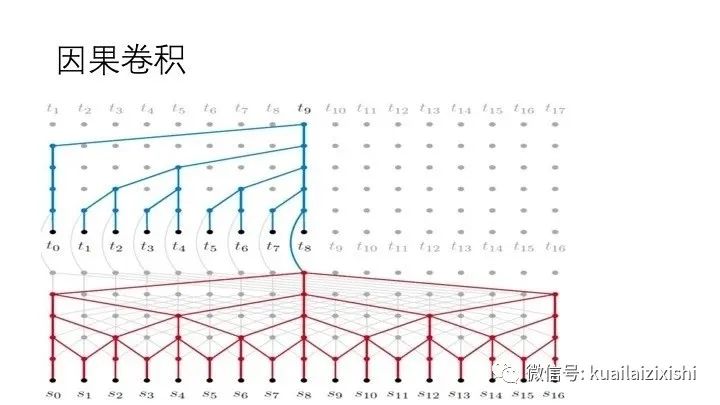
因果卷积:可以看到每一层 时刻的值只依赖于上一层 时刻的值,体现了因果卷积的特性;
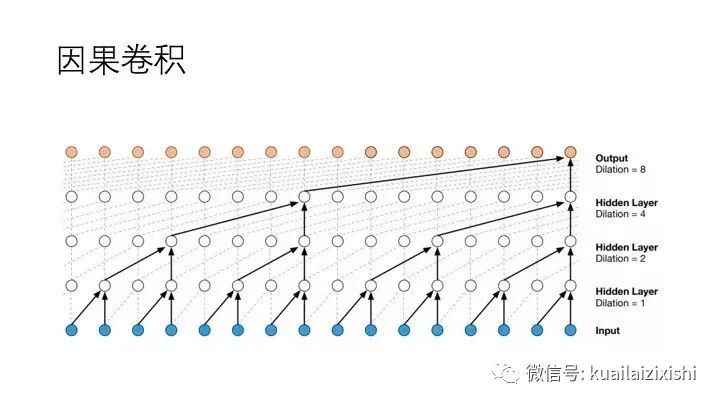
2.2 空洞卷积(扩张卷积)

扩张卷积:首先来看下扩张卷积如何工作的,上图就是不同空洞系数下的扩张卷积示意图。d=1、2、4代表的是空洞系数的不同取值,三条蓝色线代表卷积核的大小为3(k),输入的是从X0到XT的一维向量,输出与输入维度一致。( 当 时,空洞卷积退化为普通卷积 )

而每一层对上一层信息的提取,都是跳跃式的,且逐层 dilated rate 以 2 的指数增长,体现了空洞卷积的特性。
由于采用了空洞卷积,因此每一层都要做 padding(通常情况下补 0),padding 的大小为 ,因此上图padding分别为:2、4、8。
2.3 残差模块
残差模块:TCN 的残差模块内有两层扩张卷积(Dilated Causal Conv)和 ReLU 非线性函数,且卷积核的权重都经过了权重归一化(WeightNorm)。此外TCN 在残差模块内的每个空洞卷积后都添加了 Dropout 以实现正则化,如上图所示。
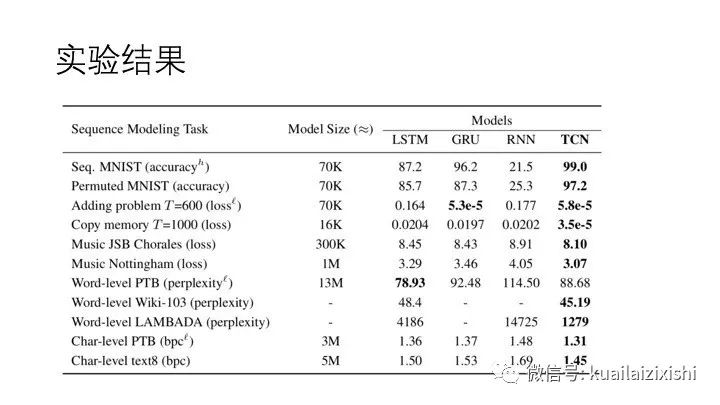
3. Conclusion with this experiment
4. 代码
import torch import torch.nn as nn from torch.nn.utils import weight_norm class Chomp1d(nn.Module): def __init__(self, chomp_size): super(Chomp1d, self).__init__() self.chomp_size = chomp_size def forward(self, x): """ 其实这就是一个裁剪的模块,裁剪多出来的padding """ return x[:, :, :-self.chomp_size].contiguous() class TemporalBlock(nn.Module): def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2): """ 相当于一个Residual block :param n_inputs: int, 输入通道数 :param n_outputs: int, 输出通道数 :param kernel_size: int, 卷积核尺寸 :param stride: int, 步长,一般为1 :param dilation: int, 膨胀系数 :param padding: int, 填充系数 :param dropout: float, dropout比率 """ super(TemporalBlock, self).__init__() self.conv1 = weight_norm(nn.Conv1d(n_inputs, n_outputs, kernel_size, stride=stride, padding=padding, dilation=dilation)) # 经过conv1,输出的size其实是(Batch, input_channel, seq_len + padding) self.chomp1 = Chomp1d(padding) # 裁剪掉多出来的padding部分,维持输出时间步为seq_len self.relu1 = nn.ReLU() self.dropout1 = nn.Dropout(dropout) self.conv2 = weight_norm(nn.Conv1d(n_outputs, n_outputs, kernel_size, stride=stride, padding=padding, dilation=dilation)) self.chomp2 = Chomp1d(padding) # 裁剪掉多出来的padding部分,维持输出时间步为seq_len self.relu2 = nn.ReLU() self.dropout2 = nn.Dropout(dropout) self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1, self.dropout1, self.conv2, self.chomp2, self.relu2, self.dropout2) self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else None self.relu = nn.ReLU() self.init_weights() def init_weights(self): """ 参数初始化 :return: """ self.conv1.weight.data.normal_(0, 0.01) self.conv2.weight.data.normal_(0, 0.01) if self.downsample is not None: self.downsample.weight.data.normal_(0, 0.01) def forward(self, x): """ :param x: size of (Batch, input_channel, seq_len) :return: """ out = self.net(x) res = x if self.downsample is None else self.downsample(x) return self.relu(out + res) class TemporalConvNet(nn.Module): def __init__(self, num_inputs, num_channels, kernel_size=2, dropout=0.2): """ TCN,目前paper给出的TCN结构很好的支持每个时刻为一个数的情况,即sequence结构, 对于每个时刻为一个向量这种一维结构,勉强可以把向量拆成若干该时刻的输入通道, 对于每个时刻为一个矩阵或更高维图像的情况,就不太好办。 :param num_inputs: int, 输入通道数 :param num_channels: list,每层的hidden_channel数,例如[25,25,25,25]表示有4个隐层,每层hidden_channel数为25 :param kernel_size: int, 卷积核尺寸 :param dropout: float, drop_out比率 """ super(TemporalConvNet, self).__init__() layers = [] num_levels = len(num_channels) for i in range(num_levels): dilation_size = 2 ** i # 膨胀系数:1,2,4,8…… in_channels = num_inputs if i == 0 else num_channels[i-1] # 确定每一层的输入通道数 out_channels = num_channels[i] # 确定每一层的输出通道数 layers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size, padding=(kernel_size-1) * dilation_size, dropout=dropout)] self.network = nn.Sequential(*layers) def forward(self, x): """ 输入x的结构不同于RNN,一般RNN的size为(Batch, seq_len, channels)或者(seq_len, Batch, channels), 这里把seq_len放在channels后面,把所有时间步的数据拼起来,当做Conv1d的输入尺寸,实现卷积跨时间步的操作, 很巧妙的设计。 :param x: size of (Batch, input_channel, seq_len) :return: size of (Batch, output_channel, seq_len) """ return self.network(x)
