




Spark SQL中的Join是连接两个或多个数据集(dataset,下同),类似于基于SQL的数据库表连接。Spark的工作在dataset和dataframe这样的表格上。Spark SQL支持几种类型的连接,如inner join, cross join, left outer join, right outer join, full outer join, left semi-join, left anti join。在Spark SQL中根据业务使用情况来实现连接方案。有些连接需要较多资源和有有效的计算。为了面对这样的场景,Spark支持SQL优化器和启动cross join特性。
Spark SQL中JOIN的类型
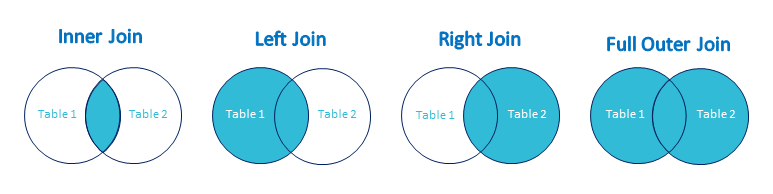
以下是不同类型的join:
- INNER JOIN
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
- LEFT SEMI JOIN
- LEFT ANTI JOIN
数据创建例子
我们将使用以下数据来证明不同类型的join:
Book Dataset
case class Book(book_name: String, cost: Int, writer_id:Int) val bookDS = Seq( Book("Scala", 400, 1), Book("Spark", 500, 2), Book("Kafka", 300, 3), Book("Java", 350, 5) ).toDS() bookDS.show()复制

Writer Dataset
case class Writer(writer_name: String, writer_id:Int) val writerDS = Seq( Writer("Martin",1), Writer("Zaharia " 2), Writer("Neha", 3), Writer("James", 4) ).toDS() writerDS.show()复制

Join的类型
下面提到了7种不同类型的连接:
1.INNER JOIN
INNER JOIN返回的数据集包含两个数据集中值匹配的行,即公共字段的值将是相同的。
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner") BookWriterInner.show()复制

2.LEFT OUTER JOIN
LEFT OUTER JOIN返回的dataset包含左面数据集的所有行,以及右面数据集匹配的行。
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter") BookWriterLeft.show()复制

3.RIGHT OUTER JOIN
RIGHT OUTER JOIN返回的数据集包含右面数据集的所有行,以及左面数据集匹配的行。
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter") BookWriterLeft.show()复制

4.FULL OUTER JOIN
当左面数据集或右面数据集中存在匹配时,FULL OUTER JOIN返回包含所有行的数据集。
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter") BookWriterFull.show()复制

5.LEFT SEMI JOIN
LEFT SEMI JOIN返回一个数据集,其中左面数据集所有行都与右面数据集对应。与LEFT OUTER JOIN不同,LEFT SEMI JOIN中返回的数据集只包含来自左面数据集的列。
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi") BookWriterLeftSemi.show()复制
6.LEFT ANTI JOIN
ANTI SEMI JOIN返回一个数据集,该数据集包含来自左面数据集,但在右面数据集中没有匹配的所有行。它只包含来自左面数据集的列。
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti") BookWriterLeftAnti.show()复制

总结
join数据是完成我们业务例子中最常见和最重要的操作之一。Spark SQL支持所有基本类型的连接。在连接时,我们还需要考虑性能,因为它们可能需要大量的网络传输,甚至创建的dataset超出我们处理能力。
原文标题:Different Types of JOIN in Spark SQL
原文作者:Meenakshi Goyal
原文地址:https://blog.knoldus.com/different-types-of-join-in-spark-sql/
