




一个生产系统告警,如何让它成为技术新手的上手机会,通过使用ORACLE的基本技能,分析出较复杂问题的根本原因所在,在分析过程中大胆猜测,步步推进,并最终形成一个非常有警示性的风险提示,给出规避方案和解决方案,老K希望能给大家一些不一样的启示。
 技术的锲子
技术的锲子
找不到的 SQL
 “老K,快来帮忙,有个SQL找不到了!!”监控同事求助。
“老K,快来帮忙,有个SQL找不到了!!”监控同事求助。
“什么叫SQL找不到呢?会是什么问题呢?”边嘀咕着很快赶到现场并了解情况,原来是监控报某重要系统有ORA-01555错误,需要分析,监控的来源是alert日志,原错误很简单。
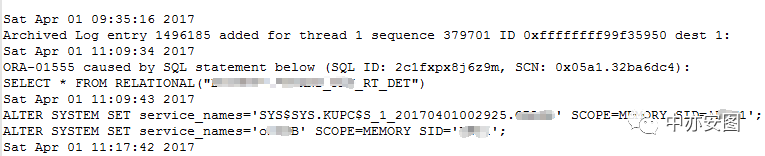 可以看到,抛错的sql_id是2c1fxpx8j6z9m,sql文本直接能看到,很简单的一条语句,唯一的遗憾是一般ORA-01555报错带的duration信息此处没有。
可以看到,抛错的sql_id是2c1fxpx8j6z9m,sql文本直接能看到,很简单的一条语句,唯一的遗憾是一般ORA-01555报错带的duration信息此处没有。



ORA-01555概念:
1.SQL语句执行时间过长,UNDO表空间过小,或者说是事务量过大等,在SQL执行过程中需要构造一致性读时,UNDO块已经被覆盖了;
2.SQL语句执行过程中涉及延迟块清除时,无法确认块的事务提交时间与SQL发起时间的先后关系,导致报错;
3.其他已知或者未知的bug。

它藏在了哪里?
我们不妨来仔细看看之前的这个图:
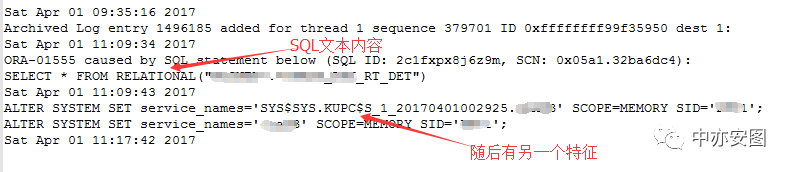
我们可以看到两个特征:
SQL文本是SELECT *FROM RELATIONAL("XXX"."XXX_RT_DET");
抛错后随后即出现了ALTER SYSTEM SET service_names='SYS$SYS.KUPC类似的语句;
那么这两个特征能说明什么呢?有经验的朋友可能一眼就看出来了,没错!!SQL显然是在导出时执行的语句,在抛错完成后,导出任务也就结束了。有了这个信息之后,我们再通过相关查询以及与应用维护团队的沟通后,很快就能找到本地操作系统上的导出日志,我们看到当天的导出日志信息:
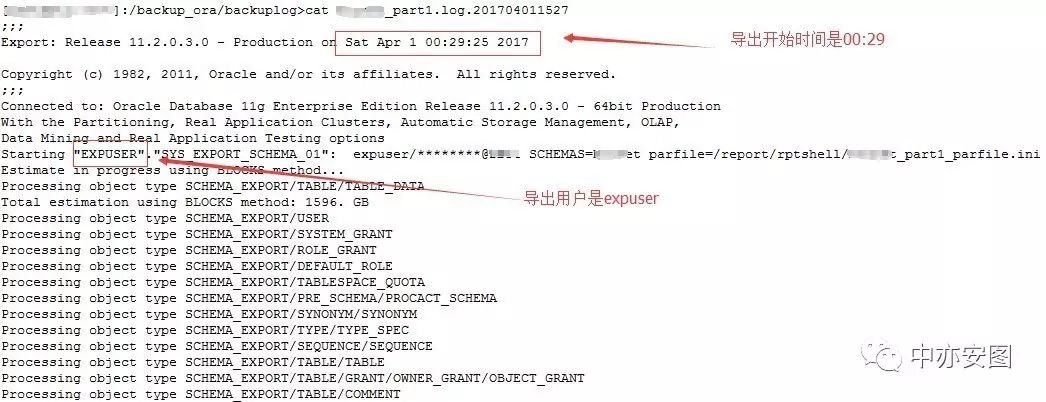
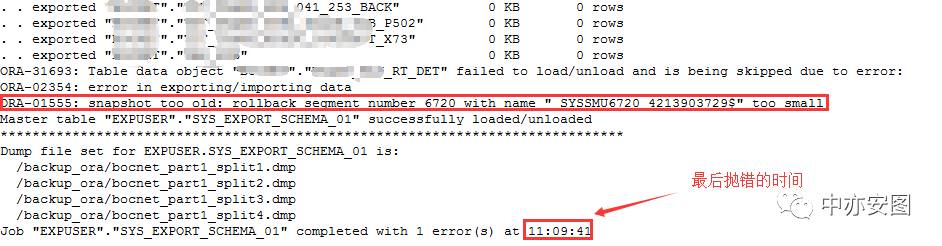 导出时间从0点开始,到11:09结束,导出用户是expuser,而且导出日志中确实也是在导出XXX_RT_DET抛出了ORA-01555错误。
导出时间从0点开始,到11:09结束,导出用户是expuser,而且导出日志中确实也是在导出XXX_RT_DET抛出了ORA-01555错误。

但是它为什么没有记录在ASH视图中呢?


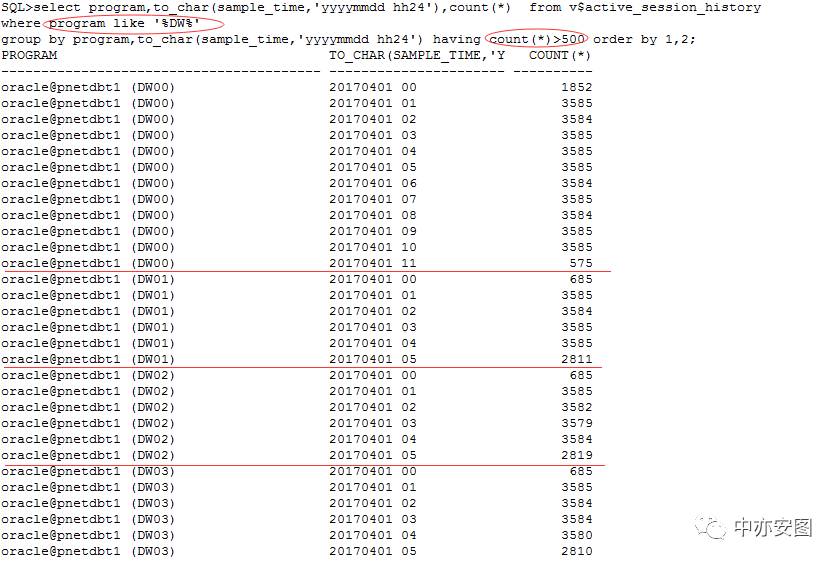 通过ASH视图过滤program like ‘%DW%’找到在数据库中导出过程的活动会话,其中DW00从0点一直到11点都能采样到,也就是说ASH视图中记录了最近一整天的数据,正常情况下sql执行,就应该被采样到才对;
通过ASH视图过滤program like ‘%DW%’找到在数据库中导出过程的活动会话,其中DW00从0点一直到11点都能采样到,也就是说ASH视图中记录了最近一整天的数据,正常情况下sql执行,就应该被采样到才对;
 再看导出时执行的主要SQL是5m8ruy0agb6mw:
再看导出时执行的主要SQL是5m8ruy0agb6mw:
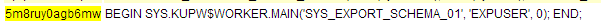
是一个导出时调用的sys用户下的存储过程,那么,我们其实可以说2c1fxpx8j6z9m就是存储过程语句5m8ruy0agb6mw下的子语句,因为ASH只采样了父语句5m8ruy0agb6mw,所以我们说因为ASH没有采样到2c1fxpx8j6z9m而判断它执行时间短是草率的,不严谨的!
我们说,2c1fxpx8j6z9m藏在了5m8ruy0agb6mw后面!
可是根本问题还是没有答案,我们的SQL到底执行了多长时间呢?


换一个思路
虽然我们找到了应用没有关注的导出报错的信息,也能匹配上确实报了ORA-01555错误,但似乎还是不能帮我们确认SQL执行了多长时间,我们不妨换一个思路来看这个问题;
首先,语句在手,我们不妨看看正常情况下2c1fxpx8j6z9m的执行计划是什么样的:
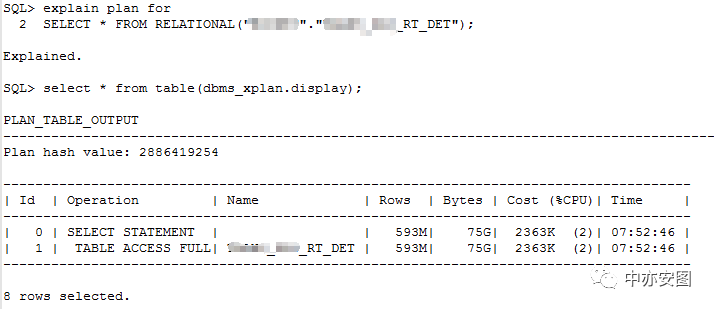
全表扫描没毛病!这个表有多大呢?

89G的表可不小!全表扫描可需要很长一段时间的呢?
其次,我们说导出也好,或者2c1fxpx8j6z9m的执行也罢,最终访问的依然是 XXX_RT_DET对象,查不到SQL语句,我们不妨查查都在什么时间段内访问了这个对象了,以及在这个对象上的等待事件;
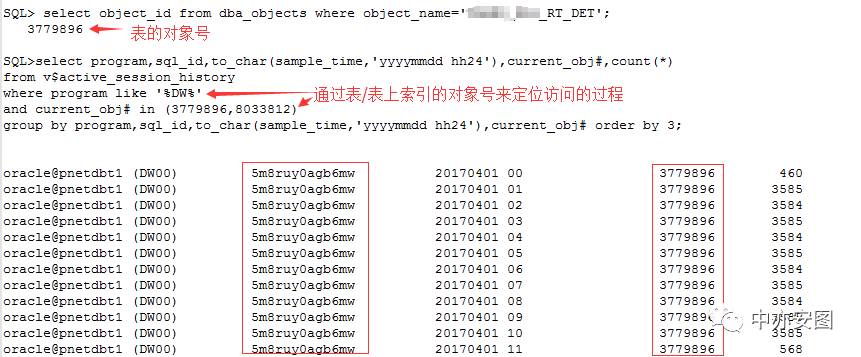
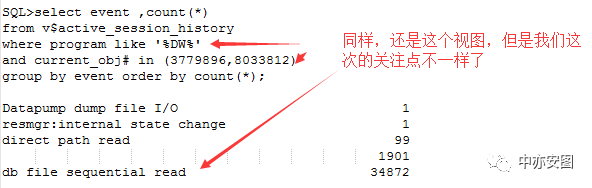 可以看到整个导出过程中,5m8ruy0agb6mw语句也就是导出过程对XXX_RT_DET对象的访问持续了10个小时,访问过程中主要的等待事件是db file sequential read;
可以看到整个导出过程中,5m8ruy0agb6mw语句也就是导出过程对XXX_RT_DET对象的访问持续了10个小时,访问过程中主要的等待事件是db file sequential read;
你看吧,之前的语句2c1fxpx8j6z9m应该是全表扫描,这里5m8ruy0agb6mw的等待事件是单块读,明显不一样嘛。我还是觉得,是不是导出过程中时是要通过5m8ruy0agb6mw来做,但是最后还是要另外执行2c1fxpx8j6z9m,然后报错了。
接下来就是见证奇迹的时刻了……

见证奇迹的时刻
前面因为有导出抛ORA-01555与alert中的匹配,已经可以知道语句2c1fxpx8j6z9m是在导出的过程中执行的了,但是还不能确认2c1fxpx8j6z9m和语句5m8ruy0agb6mw的关系,也就不能确认2c1fxpx8j6z9m到底执行了多长时间;这里我们已经知道了SQL的执行结束时间,那么只需要知道SQL的开始时间,不就可以确认执行时间了吗?没错!就是这个方法;

如图所示这条SQL的最近解析时间是00:52(正是ASH视图中采样到开始访问XXX_RT_DET对象的时刻),执行计划是2886419254(与explain出来的执行计划是一致的),解析的用户是expuser(导出的操作用户),executions为空(意味着在00:52解析完后仅此一次失败的执行,而失败的原因当然就是ORA-01555);
结论:
导出表XXX_RT_DET花费了10个小时,也就是2c1fxpx8j6z9m执行了10个小时,执行时间过长,在开门营业时间内,因为联机业务对表XXX_RT_DET存在大量的DML操作,导致了ORA-01555的出现。
可是它的等待事件是db file sequential read呀?这个你没有解释!
小总结到这我们来看看,我们是如何一步一步走到现在这一步的:
SQL报了ORA-01555,在ASH视图中找不到,但是其语句特征与导出密切相关;
找到导出日志,确实发现导出抛出了ORA-01555,时间也能匹配上;
通过ASH视图找到导出的5m8ruy0agb6mw并不是具体语句,那么它极有可能就调用了2c1fxpx8j6z9m;
通过2c1fxpx8j6z9m访问/导出时抛错的对象XXX_RT_DET的对象号,确认该表导出花费了10个小时;
最终通过解析时间/解析用户等信息与其他情况匹配,确认SQL 2c1fxpx8j6z9m就是从00:52执行到了11:09;
sql的执行计划是全表扫描,却出现了大量db sequential read,这正是导致这一问题的根本原因;目前我们的关注点也就转移到了导出时等待事件异常的分析上了。

可恶的行迁移
那么,一个全表扫描的执行计划跑出来的sql通常会有哪些情况导致db file sequential read呢?通常有几种:
表上有LOB字段
表数据已经大量缓存到buffer cache中,导致direct path read/db file scatterd read时无法连续,而产生部分db filesequential read;
表上数据存在大量的行迁移/行链接的情况
还是各种bug
简单一查就能得出结论,第一条和第二条不符合我们目前面临的情况,那我们来看看怎么定位有没有行迁移呢?其实很简单,我们收一个导出时段的AWR报告,查找关键字continued row,如下:

可以看到存在行迁移的情况,不过这并不能说明就是这个表上存在XXX_RT_DET行迁移;这样,我们不妨通过db file sequential read等待事件中的p1、p2来做个数据块的dump确认了;
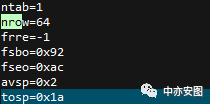
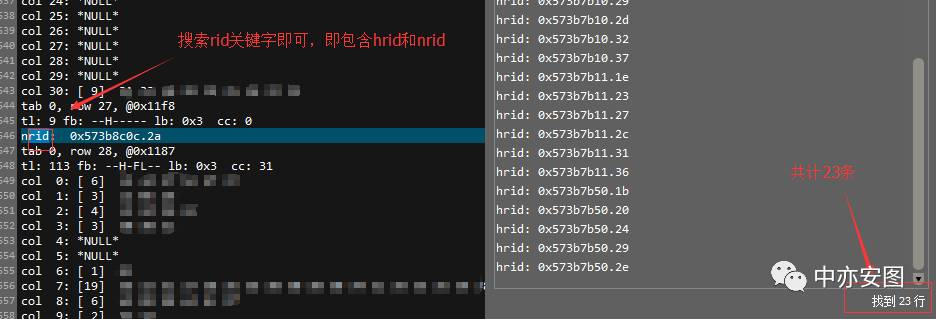
其中,需要说明的是,nrow代表的是块中记录的行数,而nrid/hrid分别代表的是行迁移指向的目标数据块和行迁移的源头块,hrid/nrid后的十六进制数字可以使用dbms_utility包转换为文件号和块号,此处不再赘述;单从此块可以看出,该表的行迁移数量还是很高的;做了多个块的dump看,确实每个都存在多条记录有行迁移的情况;
另外,我们根据等待事件粗略地估算一下整体的行迁移比例:
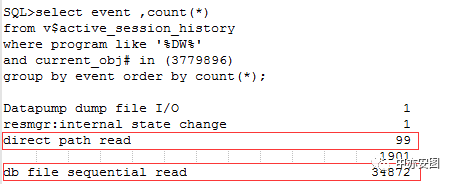
可以看到多块读的采样次数是99,单块读的采样次数是34872,数据库中db_file_multiblock_read_coun参数的值为16;如果忽略单次等待时间的影响,我们可以说表中的行迁移的比例简单计为34872/(99*16+34872)=95%,也就是说表中有95%的块存在行迁移的情况;太高!真是可恶的行迁移!

根因定位
在了解上述情况后,再回头来检查以往的导出日志,我们还是会发现:XXX_RT_DET表的导出总是最晚导完,并不一定报ORA-01555,不过这里ORA-01555已经不是我们关注的重点了:如果让导出不跑到联机时段,是不会报ORA-01555的;而且该表导出偏晚并不是一个逐步的过程,是由某一天突然变化的,那么问题又来了,这又是为什么呢?
因为历史太久,数据库的历史视图已经看不到当时的变化前后的情况了,这里就需要把几种产生行迁移的可能给应用团队列出来,看看咱们的业务符合哪个特征:
频繁的update表,而且update的字段存在字段长度变长的现象;
使用modify修改过表的列或者为表增加过非空的列;
将可能的原因列出来之后,应用团队通过自己的变更排查最终找到了确实是导出变慢的前一天有过为表增加字段并且字段存在默认值的情况!
增加一个字段会导致95%的块都存在行迁移的情况吗?太厉害了吧!
不查以前还真没关注过,这里简单搜一下MOS,就能看到下面的文章(截取精华部分):

原来,如果有行迁移,而导出时使用默认的DIRECT_PATH方式导出的话,db file sequential read的等待事件会特别特别高,所以前面的行迁移估算可能需要修正!
这样,我们这里的根本原因,我们可以认为是两条:
1. 表上做过列修改,导致表本身产生了大量的行迁移!
2.数据泵导出时,默认对该表使用DIRECT_PATH方式导出,导致导出非常慢!

风险提示与排查方法
其实从上述案例中,我们可以知道行迁移导致的数据泵导出缓慢只是其中一种现象;同理,如果一个表上存在大量的行迁移,可能会导致表的访问性能出现严重下降;简单来说,当SQL访问到某条记录在A块中,但是该条记录又被链接到B块,那么这时SQL访问一条记录就读取了两个块,而且如果是类似本CASE中的全表扫描,还会出现高比例的db file sequential read等待事件的情况;所以,我们应该要规避行迁移;
业务逻辑上存在update导致字段长度变长的那些表,我们将其pct_free值设置的更大一些;
对于存在需要修改列定义长度变化,以及新增列的情况,我们建议尽量避免在原表上修改,而通过构造新表来实现;
针对于单条记录非常大的,我们建议使用单独的更大块表空间来存放这类表(实际上这里就是针对的行链接的情况)
那么,对于已有的系统,我们应该如何针对单个表来排除呢?像上文提到的
使用导出时的比例统计因为bug原因可能并不准确;
需要更精确的方法:
官方命令里有一个analyze table XXX list chained rows的方法,但是该命令会对表持有表级锁,进而阻塞其他针对该表的DML操作;
如前文所提到的,我们可以通过table fetch continued row统计值来统计表中存在行迁移的行数;具体如下:
(1)已知一个会话sid,执行下述语句:
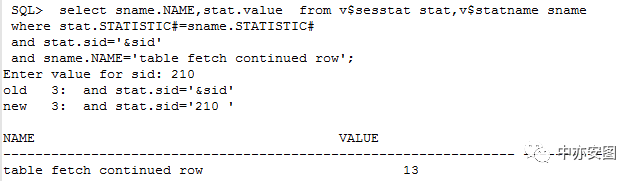
(2)然后针对想检查的表做一个全表扫描,注意需要加上full的hint
最好先确认该语句确实是全表扫描
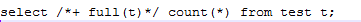
(3)再次查看table fetchcontinued row的值
(4)前后两次值相减即为该表中的行迁移/行链接的条数,214-13即该表中行迁移的记录数为201条。

解决方案
临时性的方案:针对XXX_RT_DET表,我们单独拎出来导出,指定导出的access_method为external_table模式,避免再出现导出时间非常长的情况,进而避免ORA-01555的情况;但是该方案只能是针对导出的。
根本性解决方案:针对XXX_RT_DET表,及检查到的类似的表,通过DBMS_REDEFINITION的包重定义表,消除行迁移;其他表如果存在日常业务大量导致字段长度变长的update操作,在重定义时,增加表的pct_free值。
目前,本CASE中的XXX_RT_DET表已经重定义完成,完成后表的大小变化不多,但是导出已经从10个小时下降到十几分钟。
后记
好啦,今天就到这里,看完整篇文章很是辛苦了,当然小编也辛苦;如果觉得还有所收获,不如和我们一样,多多分享啊,您的转发是我们继续分享的最大动力哦!!更多实战分享和风险提示,请关注“中亦安图”公众号!也可以加小y微信,进微信群探讨技术,shadow-huang-bj。


关注公众号:
回复“001” 第一期:技术人生系列 · 我和数据中心的故事(第一期)小机上运行Oracle需要注意的进程调度bug
回复“002” 第二期:技术人生系列 · 我和数据中心的故事(第二期)-风险提醒之Oracle RAC高可用失效
回复“003” 第三期:技术人生系列 · 我和数据中心的故事(第三期)-中亦科技关于数据库文件损坏风险的提醒
回复“004” 第四期:技术人生系列 · 我和数据中心的故事(第四期)-导致Oracle性能抖动的参数提醒
回复“005” 第五期:技术人生系列 · 我和数据中心的故事(第五期)-清算/报表/日终跑批程序之性能优化案例(一)
回复“006” 第六期:技术人生系列 · 我和数据中心的故事(第六期)-Oracle内存过度消耗风险提醒
回复“007” 第七期:技术人生系列 · 我和数据中心的故事(第七期)-Systemstate Dump分析经典案例(上)
回复“008” 第八期:技术人生系列 · 我和数据中心的故事(第八期)-Systemstate Dump分析经典案例(下)
回复“009” 第九期:技术人生系列 · 我和数据中心的故事(第九期)-SQL优化之基于SQL特征的改写
回复“010”第十期:技术人生系列·我和数据中心的故事(第十期)-一次导致数据丢失的小变更
回复“011”第十一期:技术人生系列·我和数据中心的故事(第十一期)-一次启停引发的故障
回复“012”第十二期:技术人生系列·我和数据中心的故事(第十二期)-风险预警·如何预防开发问题流到生产
回复“013”第十三期:技术人生系列·我和数据中心的故事(第十三期)-风险预警-容易忽略的导入问题问题
回复“014”第十四期:技术人生系列·我和数据中心的故事(第十四期)-橙色预警-Oracle游标泄露(open_cursor耗尽)
回复“015”第十五期:技术人生系列·我和数据中心的故事(第十五期)-橙色预警:索引空间泄露导致业务中断
回复“016”第十六期:技术人生系列·我和数据中心的故事(第十六期)-红色警报--Oracle宕机潮来临,快快行动起来!
回复“016续”第十六期续:技术人生系列·我和数据中心的故事(第十六期续)-oracle rbal进程内存泄露问题续集
回复“017”第十七期:技术人生系列·我和数据中心的故事(第十七期)-看中国最美女DBA的一次价值连城的系统优化!
回复“018”第十八期:技术人生系列·我和数据中心的故事(第十八期)-记一条500行执行计划的SQL问题分析-从应急处理到根因分析
回复“019”第十九期:技术人生系列·我和数据中心的故事(第十九期)-通过案例教你识别操作系统重启是否为ORACLE CRS引起



