




前言


越向往光明,越要默默的扎根于黑暗
本篇文章已收录到 GitHub 仓库 https://github.com/logerJava/loger

关于 Spring 相关的一些知识 loger 暂时没有想出一些其他知识点, 如果小伙伴们有发现可以下方留言, SpringCloud 会放在后面一点, 在分布式理论之类的东西写过之后再去写, 本篇和后面的文章我们重回 MySQL, 讲解一下 MySQL 中的索引
索引
什么叫做索引呢 ? 你可以理解为文章的目录, 比如一本书我要找到里面关于 Java 篇的内容, 在没有目录的情况下我需要一篇一篇的翻到 Java 章节, 但是如果有了目录, 我就可以在目录中找到页数然后直接找到 Java 章节
在 MySQL 中我们常见的索引如下 :
B+Tree 索引
Hash 索引
全文索引
空间数据索引
我们将以 B+Tree 索引为主要讲解, 其他索引本篇中仅简单讲解
B+Tree 索引
比较常用的是 B+Tree 索引, 下方所讲解 B+Tree 层高都是 4, 层高不同结构也会不同
1
B+Tree
了解 B+Tree 索引前我们需要先了解 B+Tree 这个数据结构, B+Tree 指 Balance Tree 平衡树, 平衡树是查找树, 所有叶子节点位于同一层, 下面给大家安利一个好东西, 旧金山大学做的 BPlusTree Visualization 可以模拟各种数据结构
首页地址
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
B+Tree 地址
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
B+Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现的, 它具有 B Tree 的平衡性, 可以通过顺序访问指针来提高区间查询的性能
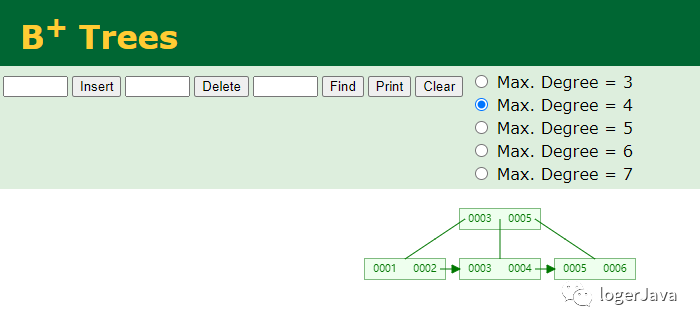
上图为插入 1 - 6 后树的可视化状态, 大家可以在网站自己尝试一下从 1 一直插入数字查看树的变化
2
聚簇索引
了解完成了 B+Tree 我们来了解一下聚簇索引的概念, 我们可以思考一下, 平时如果需要对字段建立索引的时候, 一般都会采用create index 然后去建立索引, 但是事实上, 在表创建的时候就已经有索引了, 这个索引就是聚簇索引, 还记得前面说的目录的概念吗 ? 没错这个聚簇索引就是建表时同时建立的目录
举个例子来讲吧
SELECT * FROM student WHERE studentId = 6复制
我要查询学生表中学生 id 为 6 的学员全部信息, 如果没有目录, 也就是聚簇索引的情况下, 会怎么样呢 ?
那么它就是无序的, 需要全表查询才能找到这个索引, 那么问题就来了, 主键是自增的不可以用二分查找去解决吗 ?
实际上并不是这样的, 你想如果你的数据写入磁盘时是 1, 2, 3, 4, 5, 6 我删除掉了 4, 那么怎么将 5 向前移动呢 ? 如果没有维护一个有序数组的数据结构, 那么数据在磁盘就认为它是无序的, 如果你维护了有序数组, 那么也是建立了索引, 只不过是换了一种数据结果
言归正传, 现在我们在创建表的时候建立了聚簇索引, 那么再次执行上面的 SQL 会变成什么样子呢 ? 因为上图只有 key 所以这里换一个图
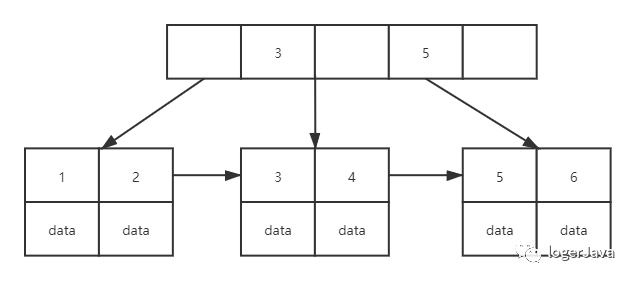
数据库里面有 1, 2, 3, 4, 5, 6 个学生 :
从上到下查找, 在根节点进行二分查找, 找到一个 studentId 所在的指针, 这里指向右侧
在叶子节点上进行二分查找, 找到 studentId = 5 对应的 data
聚簇索引的叶子节点 data 域记录着完整的数据记录, 因为无法把数据存放在两个不同的地方, 所以一个表只能有一个聚簇索引
聚簇索引是无论如何都会创建的, 如果设定了主键, 则主键是聚簇索引, 如果没有设定主键会寻找唯一键作为索引, 就算你连唯一键都没有, 也没关系, MySQL 会建立一个 rowid 字段, 来完成 B+Tree
3
二级索引
讲完了聚簇索引我们来说一下二级索引, 因为我们并不是永远知道主键是什么, 还是拿学生表举例, 可能我要用学生的手机号查询, 又可能用学生的姓名查询, 我们可以看一下上面的树结构, 并没有学生的手机号与姓名, 这个时候怎么办 ?
CREATE INDEX idx_studentName ON student(studentName)复制
对吧, 建立一个学生姓名的索引, 那么此时 MySQL 发生了什么呢 ?
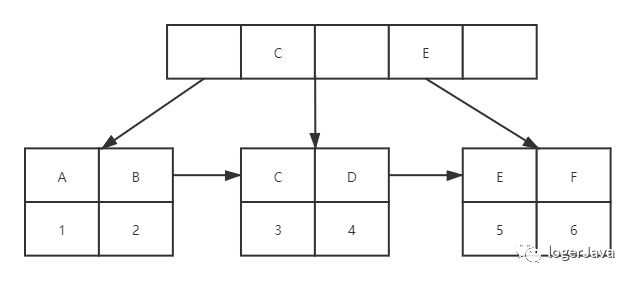
首先它会新创建一个 B+Tree, 里面存储着学生姓名, data 存储着主键 id
SELECT * FROM student WHERE studentName = 'F'复制
当我在二级索引中查询姓名为 F 的学员时 :
还是二分查找, 找到对应指针
会在 B+Tree 中找到 key 是 F 的记录
二级索引的 data 域中存储的是主键id, 那么就拿到主键 id
因为是查询全部字段, 所以用主键 id 到聚簇索引中进行查找
4
复合索引
事实上复合索引也属于二级索引, 那么为什么要单独提出来呢 ? 比如我如果想要同时查询, 姓名和年龄呢 ?
CREATE INDEX idx_studentName_age ON student(studentName,age)复制
没错, MySQL 会再次新建一个树, 它的结构又双叒叕变了
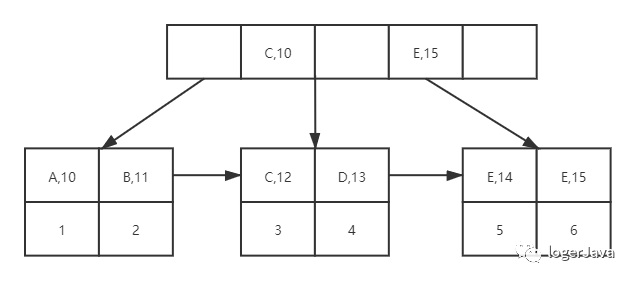
这回索引的 key 中不光有姓名了, 还有年龄, 其实它的查找步骤和上面是一样的, 唯一需要注意的一点, 相信大家也发现了, 在图中姓名为 E 的 14 岁学员, 和姓名为 E 的 15 岁学员, 他们两个是同名的年龄不同, 那么在排序比较时, 会先按照姓名比较, 如果姓名相同再按照年龄比较 .
Hash 索引
Hash 索引, 听名字就比较熟啊, HashMap, HashSet 什么的 .Hash 索引可以以 O(1) 时间进行查找, 不仅只存在于索引中, 每个数据库应用中都存在这个数据结构
我们都是到 Hash 表, 也就是散列表, 通过计算 key 的槽位置然后找到 value, Hash 索引也是如此 .
Hash 索引解决冲突的方式也是应用链表有点类似 HashMap, 因为索引的结构是十分紧凑的,所以 Hash 索引的查询很快
知识点 :
无法用于排序与分组
只支持精确查找,无法用于部分查找和范围查找
自适应索引
InnoDB 存储引擎有一个特殊的功能叫 "自适应哈希索引",当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就可以让 B+Tree 索引具有哈希索引的一些优点,比如更快的哈希查找
全文索引
MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。
查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
全文索引使用倒排索引实现,它记录着关键词到其所在文档的映射。
InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引
空间数据索引
MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。
空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
必须使用 GIS 相关的函数来维护数据
参考
MySQL 技术内幕 : InnoDB 存储引擎 (第2版) - 姜承尧 著
高性能 MySQL (第3版) - 施瓦茨 (Baron Schwartz) 扎伊采夫 (Peter Zaitsev) 特卡琴科 (Vadim Tkachenko)
MySQL 索引之哈希索引
https://www.cnblogs.com/igoodful/p/9361500.html
MySQL的索引是怎么加速查询的 ? - 柳树
https://zhuanlan.zhihu.com/p/107208937
结尾
其实关于索引方面有很多的知识点都可以通过了解索引查询的原理去解决, 比如上面有提到的复合索引, 复合索引有一个最左有限原则, 那么如果我们知道了复合索引查询时的机制, 怎么可能不知道最左优先原则的问题呢 ?
CREATE INDEX idx_studentName_age ON student(studentName,age)SELECT * FROM student WHERE studentName = "loger";SELECT * FROM student WHERE age = 18;复制
依照着上面的图, 是不是可以推导出来哪个走了索引, 哪个没有走索引呢 ?
我是 loger, 扫码关注下方公众号, 更多知识分享等你来看, 兄弟们别忘了点赞哦 👍


