




IT圈经常流传一句笑柄:“作为一个程序员,你居然只会CRUD”,其实这句话有点贬义,也不乏有一些程序员喜欢用CRUD自嘲。什么是CRUD?CRUD是4个单词的首字母,C指增加(Create)、R指读取查询(Retrieve)、U指更新(Update)、D指删除(Delete),通俗来讲,CRUD说的就是增查改删。真实工作中,我们使用查询的比重是最大的。今天先来介绍一下CUD。
INSERT-插入数据
库有了,表有了,下面就要往表中插入一些数据了。还是拿上次的student表举例,先来回顾一下student的表结构定义语句:
CREATE TABLE `student` (
`student_id` INT(11) NOT NULL AUTO_INCREMENT COMMENT '学生编号',
`student_name` VARCHAR(20) NOT NULL COMMENT '学生姓名',
`address` VARCHAR(100) NULL COMMENT '家庭住址',
PRIMARY KEY(`student_id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT='学生表';复制
表结构有了,我们在插入数据之前,还是要先了解一下INSERT语句的语法。如下所示是MySQL官档中提供的INSERT语法:
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
{VALUES | VALUE} (value_list) [, (value_list)] ...
[ON DUPLICATE KEY UPDATE assignment_list]
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
SET assignment_list
[ON DUPLICATE KEY UPDATE assignment_list]
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
SELECT ...
[ON DUPLICATE KEY UPDATE assignment_list]
value:
{expr | DEFAULT}
value_list:
value [, value] ...
assignment:
col_name = value
assignment_list:
assignment [, assignment] ...复制
INSERT语句
用法1:
[root@localhost][employee]> INSERT INTO `student`(`student_id`,`student_name`,`address`) VALUE(10001,'赵甲','北京市前门大街');
Query OK, 1 row affected (0.01 sec)复制
用法2:
[root@localhost][employee]> INSERT INTO `student`(`student_id`,`student_name`,`address`) VALUES(10002,'钱乙','北京市东直门');
Query OK, 1 row affected (0.01 sec)复制
用法3:
[root@localhost][employee]> INSERT INTO `student` VALUE(10003,'孙丙','北京市西直门');
Query OK, 1 row affected (0.01 sec)
[root@localhost][employee]> INSERT INTO `student` VALUES(10004,'李丁','北京市望京');
Query OK, 1 row affected (0.01 sec)复制
用法4:
[root@localhost][employee]> INSERT INTO `student` VALUES(NULL,'周戊','北京市海淀区');
Query OK, 1 row affected (0.02 sec)复制
用法5:
[root@localhost][employee]> INSERT INTO `student` VALUES(10006,'吴己','北京市朝阳区'),(10007,'郑庚','北京市西城区');
Query OK, 2 rows affected (0.02 sec)
Records: 2 Duplicates: 0 Warnings: 0
[root@localhost][employee]> INSERT INTO `student`(`student_id`,`student_name`,`address`) VALUE(10008,'冯戌','北京市石景山区'),(10009,'褚壬','北京市昌平区'),(10010,'卫癸','北京市小汤山');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0复制
来看一下当前表中的数据:
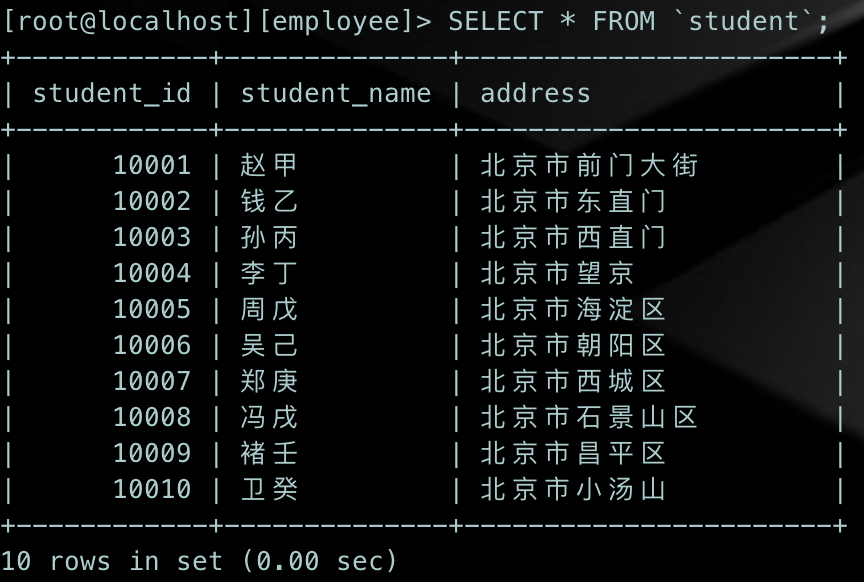
用法1和用法2:相同点是将所有的字段名和对应的值一一对应,同时,字符串类型的数据需要加''单引号引起来,整型数据类型无需加''单引号。不同点是,VALUE关键字最后的"S"可以加也可不加;
用法3:当我们提前知道了字段顺序,我们不用指定字段名,可以直接按字段顺序指定VALUE值进行数据插入;
用法4:因为我们的字段有AUTO_INCREMENT属性,含有此属性的字段,在插入数据时,可以用NULL或者0来代替字段的值。字段属性后面也会开辟单独文章进行讲解,让我们拭目以待。
用法5:VALUE关键字后面可以跟1~N个值,用于批量插入数据,同样,批量插入数据的语法也同时满足上述方法的所有特点。
INSERT ... SELECT语句
CREATE TABLE `student_foreign` (
`student_id` INT(11) NOT NULL AUTO_INCREMENT COMMENT '学生编号',
`student_name` VARCHAR(20) NOT NULL COMMENT '学生姓名',
`address` VARCHAR(100) NULL COMMENT '家庭住址',
PRIMARY KEY(`student_id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT='国外学生表';
INSERT INTO `student_foreign` (`student_id`,`student_name`,`address`) VALUES (20001,'Danny','America');
INSERT INTO `student_foreign` (`student_id`,`student_name`,`address`) VALUES (20002,'Jenny','Canada');
INSERT INTO `student_foreign` (`student_id`,`student_name`,`address`) VALUES (20003,'工藤新一','Japan');复制
查看一下当前student_foreign表的数据:
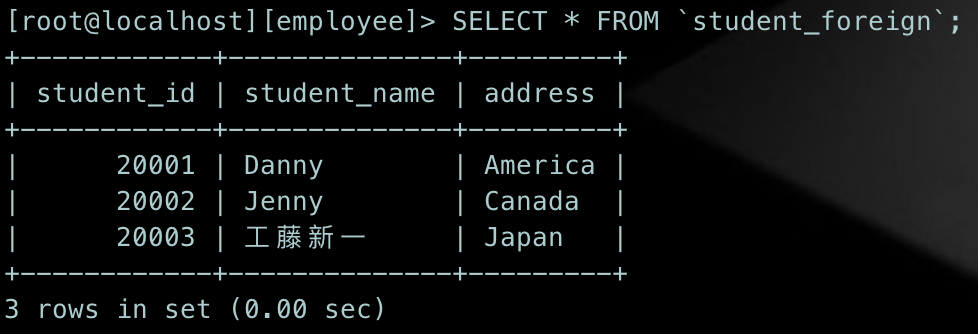
现在有一个需求,要将student_foreign国外学生表里面的学生信息插入汇总到student学生表中,按照下面的语法来操作:
[root@localhost][employee]> INSERT INTO `student` (`student_id`,`student_name`,`address`) SELECT `student_id`,`student_name`,`address` FROM `student_foreign`;
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0复制
查看一下当前student表的数据:
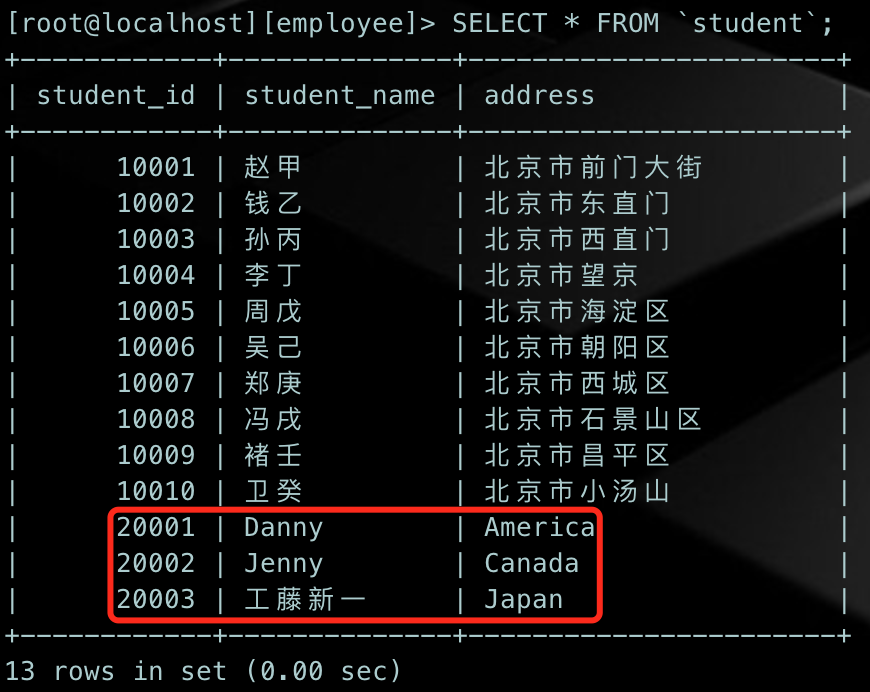 可以看到,我们已经将student_foreign表中的数据插入到student表中了,如果以后大家工作遇到类似的需求,也可以使用这种方式。
可以看到,我们已经将student_foreign表中的数据插入到student表中了,如果以后大家工作遇到类似的需求,也可以使用这种方式。INSERT ... ON DUPLICATE KEY UPDATE语句
这个语法又涉及到字段属性的问题,因为我们的student表中student_id字段设置了PRIMARY KEY属性,该属性含有“字段值不为空”和“值唯一”双重约束,INSERT ... ON DUPLICATE KEY UPDATE语句是为了防止插入过程违反唯一约束后做什么操作。详看下例:
[root@localhost][employee]> INSERT INTO `student_foreign` (`student_id`,`student_name`,`address`) VALUES (20003,'野原新之助','Japan');
ERROR 1062 (23000): Duplicate entry '20003' for key 'student_foreign.PRIMARY'复制
[root@localhost][employee]> INSERT INTO `student_foreign` (`student_id`,`student_name`,`address`) VALUES (20003,'野原新之助','Japan') ON DUPLICATE KEY UPDATE `student_name`='野原新之助';
Query OK, 2 rows affected (0.01 sec)复制
查看一下当前student_foreign表的数据:
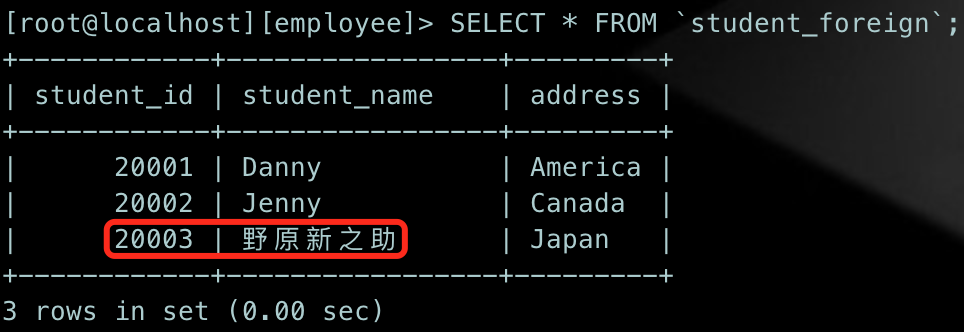
UPDATE-修改数据
UPDATE [LOW_PRIORITY] [IGNORE] table_reference
SET assignment_list
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
value:
{expr | DEFAULT}
assignment:
col_name = value
assignment_list:
assignment [, assignment] ...复制
[root@localhost][employee]> UPDATE `student_foreign` SET `student_name`='工藤新一' WHERE `student_id`=20003;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0复制
查看一下当前student_foreign表的数据:
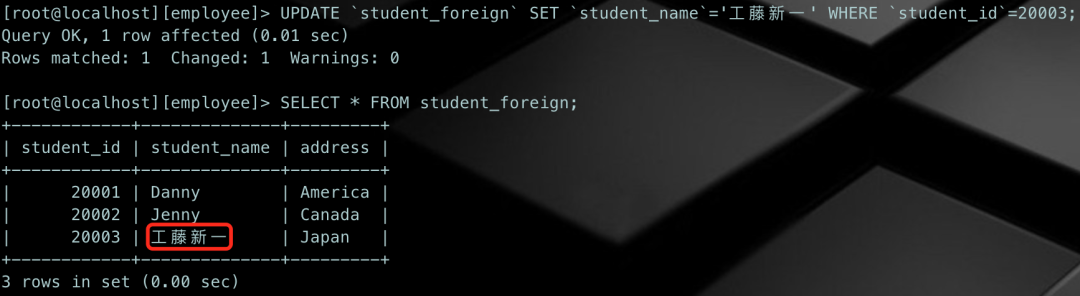
不过,这个例子中,还有一个很重要的点需要注意,就是我们在修改数据的时候是通过WHERE条件进行匹配的,只修改了我们想要修改的一行数据,如果不加WHERE条件的话,全表的student_name都会被修改,如果一个学生表的学生姓名都变成了'工藤新一',后果不堪设想,所以,使用UPDATE的时候一定要注意。同时,MySQL也为我们提供了一些安全性的参数选项:safe_updates,重点参数后面也会开辟新文章来讲解,不是本文的重点,这里不再赘述。还有,如果一张表的数据量非常大,执行UPDATE的时候不加WHERE语句,不仅对数据的准确性有一定破坏,对系统负载也会产生影响,所以,在使用UPDATE的时候一定要加WHERE条件!
DELETE-删除数据
DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]复制
[root@localhost][employee]> DELETE FROM `student_foreign` WHERE `student_name`='Danny';
Query OK, 1 row affected (0.01 sec)复制
查看一下当前student_foreign表的数据:
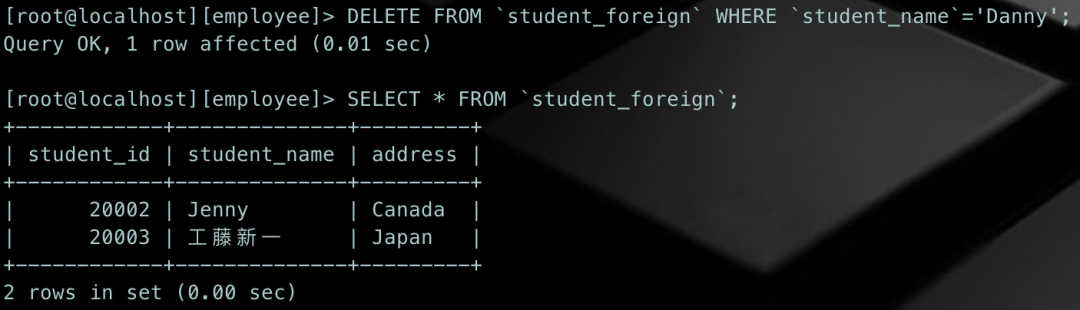
表中的结果可见,'Danny'的信息已经不在了。和UPDATE一样,我们同样是指定WHERE条件先匹配到我们要操作的数据,再做操作,如果不指定WHERE条件,DELETE操作同样会把所有数都删掉。safe_updates安全更新参数同样对DELETE有效。所以,在使用DELETE的时候也一定要加WHERE条件!
DML小结

end
