




一、概念以及解决的问题
1、Linux namespaces和cgroup是什么?
namespace和cgroup是linux内核中2种隔离的特性。
namespace也就是命名空间,它的存在是为了实现资源在不同的命名空间环境中有相同的名称。调用clone()系统函数,传入参数时指定不同的namespace类型复制出相应隔离的命名空间。
cgroup是控制组,它的存在是为了限制进程对系统各种资源占用的多少,比如cpu,memory,io,net等资源。
2、如何实现一个进程运行环境的隔离?
物理机器上使用fork()一个子进程时,使用命名空间技术,实现子进程与父进程/其他进程之间命名空间的隔离;然后初始化子进程的环境,使用cgroup限制子进程的资源;最后执行用户的命令。这些操作产生的隔离环境,可以称为“容器”。
3、一个简单程序使用pid namespace隔离前后的对比
pid namespace隔离前:sh-4.2# echo $$3414pid namespace隔离后:sh-4.2# ps -ef |grep -i shroot 14938 14934 0 10:04 pts/2 00:00:00 sh###14938的进程通过CLONE_NEWPID隔离后pid成为1;$$是运行的当前进程ID号sh-4.2# echo $$ #输出1
二、一个隔离network namespace的方式
# 物理机器上ifconfigdocker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500# 使用CLONE_NEWNET,让每个fork的子进程拥有自己的网络设备# 输出null,子进程的网络设备为空,此时它与物理机器的网络设备隔离开来sh-4.2# ifconfig #输出null
三、一个mount namespace实现隔离root文件系统的例子
# systemctl start docker# docker run -itd --name busybox busybox# docker exec -it acae3e97bb0f bin/sh# docker ps -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESacae3e97bb0f busybox "sh" 45 hours ago Exited (137) 16 hours ago busybox# mkdir -p rootfs && cd rootfs# docker export acae3e97bb0f > rootfs.tar# tar xf rootfs.tar && cd ..# c语言使用系统clone(),mount(),chdir(),chroot()实现容器镜像,并编译gcc -o dc dc.c并运行if (mount("proc", "rootfs/proc", "proc", 0, NULL) != 0) {perror("proc");}if (mount("sysfs", "rootfs/sys", "sysfs", 0, NULL)!=0) {perror("sys");}if (mount("none", "rootfs/tmp", "tmpfs", 0, NULL)!=0) {perror("tmp");}if (mount("udev", "rootfs/dev", "devtmpfs", 0, NULL)!=0) {perror("dev");}if (mount("devpts", "rootfs/dev/pts", "devpts", 0, NULL)!=0) {perror("dev/pts");}if (mount("shm", "rootfs/dev/shm", "tmpfs", 0, NULL)!=0) {perror("dev/shm");}if (mount("tmpfs", "rootfs/run", "tmpfs", 0, NULL)!=0) {perror("run");}if ( chdir("./rootfs") || chroot("./") != 0 ){}/ # /bin/ps -ef #sh进程的pid是1,当前的mount namespace跟外部是隔离的PID USER TIME COMMAND1 root 0:00 bin/sh2 root 0:00 bin/ps -ef
四、一个使用cgroup限制进程内存的方式
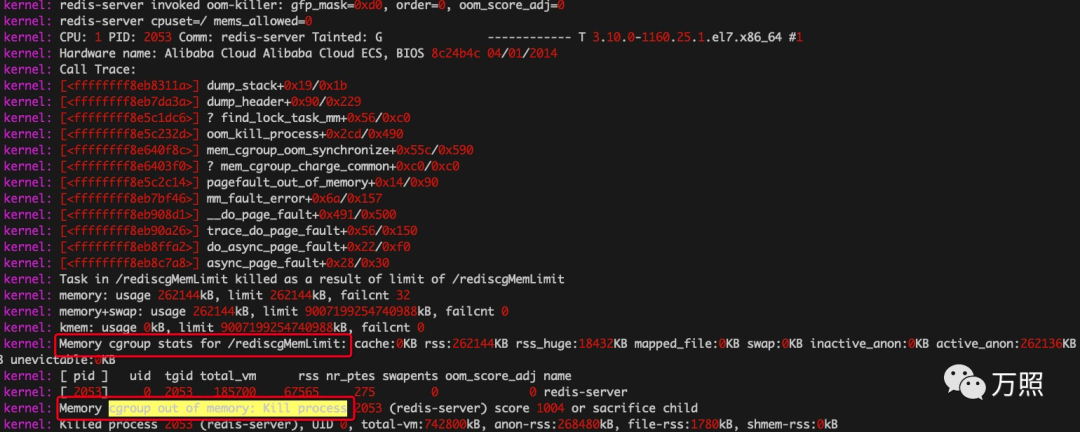
#创建并挂载自定义的root cgroup,当前的pid存在于root cgroup# mount -t cgroup -o none,name=cgroup123 cgroup123 cgrouptry/# echo $$1825# cat proc/1825/cgroup12:name=cgroup123:/#在root cgroup下扩展1个cgroup# mkdir -p cgroup1├── cgroup1│ ├── cgroup.clone_children│ ├── cgroup.event_control│ ├── cgroup.procs│ ├── notify_on_release│ └── tasks├── cgroup.clone_children├── cgroup.event_control├── cgroup.procs├── cgroup.sane_behavior├── notify_on_release├── release_agent└── tasks# cd cgroup1# echo $$ >> tasks# cat /proc/1825/cgroup #当前的进程pid被加入到/cgroup1控制组12:name=cgroup123:/cgroup1# 使用系统定义的subsystem来限制进程的资源,memory subsystem被映射到/sys/fs/cgroup/memory# mount |grep -i memorycgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)# mkdir -p rediscgMemLimit && cd rediscgMemLimit# ls rediscgMemLimit #每个配置都是资源限制文件cgroup.clone_children memory.kmem.slabinfo memory.memsw.failcnt memory.soft_limit_in_bytescgroup.event_control memory.kmem.tcp.failcnt memory.memsw.limit_in_bytes memory.statcgroup.procs memory.kmem.tcp.limit_in_bytes memory.memsw.max_usage_in_bytes memory.swappinessmemory.failcnt memory.kmem.tcp.max_usage_in_bytes memory.memsw.usage_in_bytes memory.usage_in_bytesmemory.force_empty memory.kmem.tcp.usage_in_bytes memory.move_charge_at_immigrate memory.use_hierarchymemory.kmem.failcnt memory.kmem.usage_in_bytes memory.numa_stat notify_on_releasememory.kmem.limit_in_bytes memory.limit_in_bytes memory.oom_control tasksmemory.kmem.max_usage_in_bytes memory.max_usage_in_bytes memory.pressure_level# echo 268435456 > memory.limit_in_bytes #设置进程使用的最大内存为256mb# echo 2053 >> tasks #ps aux查看Redis-server进程的信息,并将它加入rediscgMemLimit控制组限制USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 2053 0.1 0.2 154000 8152 pts/2 Sl+ 17:00 0:00 /work/soft/redis-5.0.12/src/redis-server *:6379# ./redis-benchmark -p 6379 -c 20 -t set -n 300 -d 1000000 -r 10000#redis-server写入数据超过262144kB,发生Memory cgroup out of memory: Kill process
五、实现namespace的原理
命名空间是分层的,父进程的命名空间可以看到子进程的命名空间,子进程的命名空间被映射到父进程的命名空间,这样在Linux内核中会生成一棵树。
六、实现cgroup的原理
cgroup采用虚拟文件系统来管理需要限制的资源信息(subsystem)和被限制的进程列表,先创建root cgroup,再创建子cgroup,root/子cgroup都是文件,然后向资源文件中写入限制进程/进程组的限制信息,最后把被限制的进程号加入到子cgroup中,表示该进程受到子cgroup的资源限制。
文章转载自万照,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
