




点击蓝字 · 关注我们
1、概述
为了加速数据库对数据的访问,我们需要通过buffer cache来将磁盘的数据块缓存,那么在PostgreSQL中是如何对buffer进行管理的呢?
说的直接点,我要在buffer中访问某个page,数据库怎么去判断buffer中是否存在呢,如果存在又是怎么定位到这个page呢?很简单,通过hash算法。在数据库中似乎hash算法随处可见,hash索引、hash连接等等。之所以使用hash算法,自然是因为其速度快、效率高了。在PostgreSQL几乎内存管理中所用的都是hash算法。
在介绍PostgreSQL如何使用hash算法进行 buffer管理前,我们先来了解下hash算法。
2、hash算法
2.1、什么是hash算法
我们在数据库中可能经常会听到hash这个词,那什么是hash呢?打个比方,给1个数字,然后对这个数字取余,得到该余数,这个就是hash。
可以发现hash函数主要的两个特点:
给一个定值(hash key),得到另一个定值(hash value);
过程可重复,对于同样的传入值,输出值总是一样的。
当然真正的hash函数不只是取余这么简单,取余这个操作是很占用CPU的,况且只能对数字进行操作。我们以下面的例子来看看简单的hash函数:
long hash(char *key, int len){int i;long ret = 0;if (key == 0)return 0;for (i=0; i<1 ; i++)ret ^=(key[i] << (i&0x0f));return ret;}
上面这个函数大致作用就是,对传入值char *key(hash key)的每个字符进行位运算,返回值ret就是我们要求的hash值。
相较于前面的取余运算,位运算就快很多了,占用CPU周期也少很多,但是hash运算仍然是CPU密集型的操作。因此在数据库中hash运算较多的情况下,CPU使用率自然是会比较高。
例如我们前面说的在buffer中搜索某个page,就是对buffer_tag进行hash操作得到hash值,然后使用hash值进行搜索。这样做的好处很显然,就是可以更快速的搜索。
2.2、链表与hash
既然我们前面说了是在buffer中搜索page,假设我们现在buffer中有这样3个page:
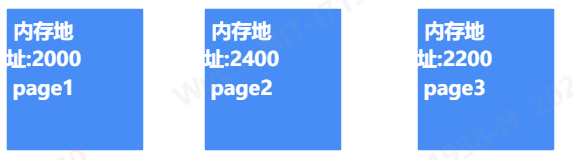
我们看到有这样存放在不同内存地址的3个page,一般它们在内存中会被存放成链表的形式,如下:

在内存地址2000的块中记录下下一个内存地址2400,在内存块2400中记录下下一个内粗地址2200,依次类推,这样就构成了链表结构。
通常还会加上一个链表头,如下所示:
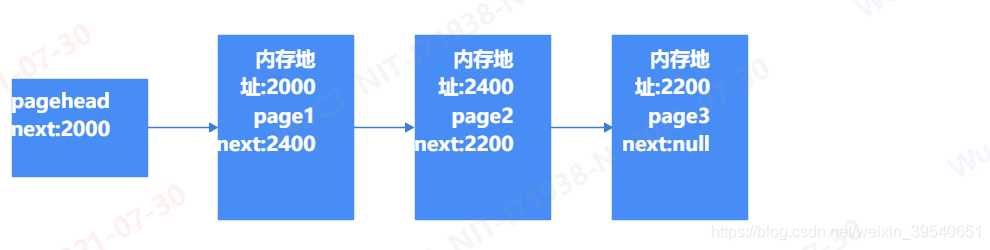
那如果我们需要查找page2的信息,步骤大致如下:
1、取出头中记录的下一个地址2400;
2、对比内存地址2400中的内容是不是所需的;
3、判断结果不是,继续取出下一个内存地址2200;
4、对比内存地址2200中的内容是不是所需的,发现正是所需的。
可以看到这就是链表中搜索某个内存块的步骤,方式很简单,但是如果链表很长,搜索时间必然要很久。因此hash算法应运而生。
hash算法需要对内存块的分布进行重新组织。在前面的链表中,我们的3个page的内存地址是随机的,但是hash算法需要他们的内存地址是连续的。而且还有一些其它特殊的要求,例如这3个page的hash值除以3取余分别为1、2、3,假设每个page大小为8个字节,那么需要在内存中分配24个字节,并且根据其hash值的余数的顺序,在内存中这三个page的顺序依次是page1->page2->page3。
假设这三个page在内存中地址开始为10000,那么page1的内存块为10000~10008,page2为10008 ~ 10016,page3为10016~10024,其结构大致为:

可以看到不需要在存储下一个内存块的地址了,因为根据自己的内存地址加上8就是下一个。那么这样有什么好处呢?例如我们的某个page的hash值是10000,除以3取余为1,那么它的地址就是10000+8*1 = 10008,这便是hash算法,避免了遍历链表的过程,我们将整个hash链表统称为hash表。
下面简单小结下链表和hash表的区别:
1、链表中,如果需要找的对象在第N个节点,那么必须从链表头开始逐个搜索直至第N个节点,如果N很大,那么搜索时间便会很长;
2、在hash表中,只需要计算搜索对象的hash值,根据hash表的hash值,加上N*每个hash节点的大小就可以得到第N个节点的地址。
3、总的来说,链表搜索的算法复杂度是O(n),hash搜索的算法复杂度是O(1)。
2.3、hash算法的缺点与hash冲突
当然hash算法也并不是没有缺点,不然链表也没有存在的意义了。
其缺点在于,我们在构建hash表时需要先确定节点个数,这里我们称为hash bulket。根据hash bulker的数量和大小我们才能去预先分配内存。
而且一般来说hash算法需要的内存是不可变的,需要提前一次性分配,这便是hash算法的不足之处。
除此之外,我们再来说说hash冲突。因为无论我们预先分配的hash bulket数量有多少,仍然会出现不同的数据块计算出来的hash值是同样的,我们把这种情况称之为hash冲突。
我们前面也说了,hash bulket的数量和大小是需要提前确定的,所有碰到这种情况我们是没办法把这些hash值相同的数据块放到同一个hash bulket中,那么该如何处理呢?
首先,将这些hash值相同的bulket组织成一个链表,然后将这个链表的头部地址放入前面的hash表中,这样就不会出现hash bulket放不下多个数据块的问题了,因为我只需要存放链表头的地址即可。
所以可以看到,要解决hash冲突并不仅仅靠hash表,需要hash表加上链表才可以,将hash冲突的bulket放到同一个链表中。
3、PostgreSQL中的hash算法
首先我们先来看下在PG中如何在buffer中定位数据块的。
我们先来介绍下buffer_tag结构:
typedef struct buftag{RelFileNode rnode; /* physical relation identifier */ForkNumber forkNum;BlockNumber blockNum; /* blknum relative to begin of reln */} BufferTag;
我们通过buffer_tag(文件ID,block number,fork number)来定位buffer中具体的某个page,对buffer_tag计算hash值,但是因为hash冲突的存在,我们同样需要使用链表,将hash值相同的page存放到链表中。
当查找指定的 key 时,首先计算出它的哈希值,然后根据后面的几位数,计算出对应的 bucket 位置。之后遍历 bucket 的元素链表,查看是否有 key 元素。
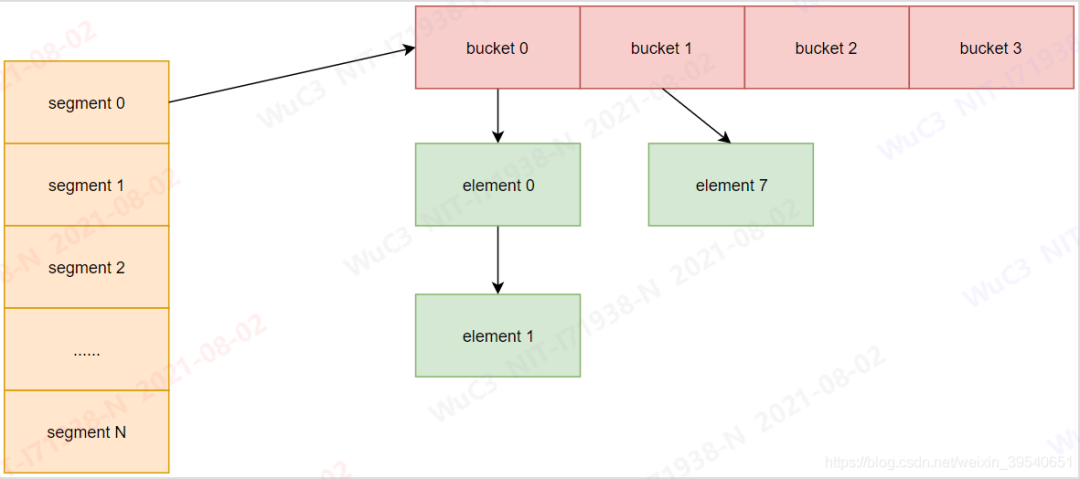
而我们前面也说了,hash表需要在初始化是分配内存,所以需要确定hash bulket的数量,而在PG中为固定的128:
/* Number of partitions of the shared buffer mapping hashtable */#define NUM_BUFFER_PARTITIONS 128
而在PG中读取buffer中page的过程大致为:
计算HASH值
根据HASH值,计算并得到HASH表锁
共享方式申请HASH表锁
搜索HASH表
如果找到目标Buffer
Pin住Buffer
释放HASH表锁
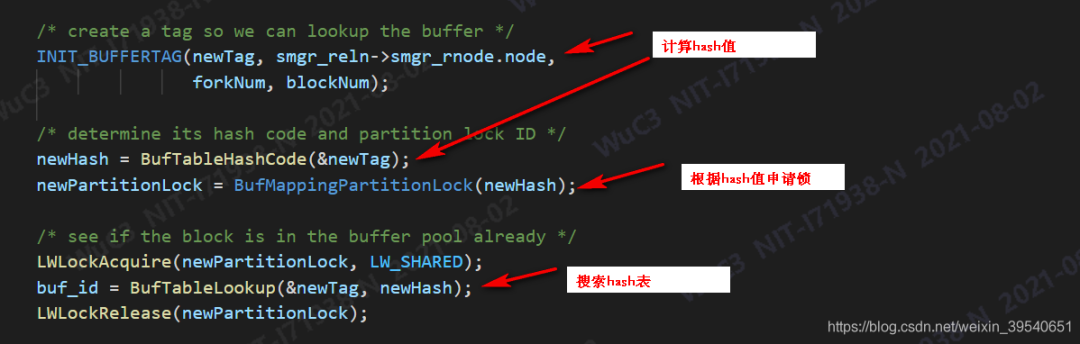
这也是为什么PG在大并发的情况下性能不高的原因之一,当数据库中并发量大时,逻辑读自然很高,那么这时对shared buffer的并发访问量就会很大,但是其hash表锁的数量只有128,相当于同一时刻有很多会话在等待。而Oracle中这个数量是buffer数量的两倍,这个差别是有点大的。
在以前机械硬盘磁盘io较差的时代128的hash bulket影响倒不会很大,因为这个并不是性能的瓶颈。而现在的硬件设备IO响应时间可以降低到20微秒,hash锁的竞争极有可能成为性能瓶颈。
参考链接:
https://www.interdb.jp/pg/pgsql08.html
https://www.modb.pro/doc/7952
往期回顾
01 |
02 |
03 |
04 |
