今天遇到一个SQL需求优化,30分钟没有跑出来,给大家分享下。
SQL如下:
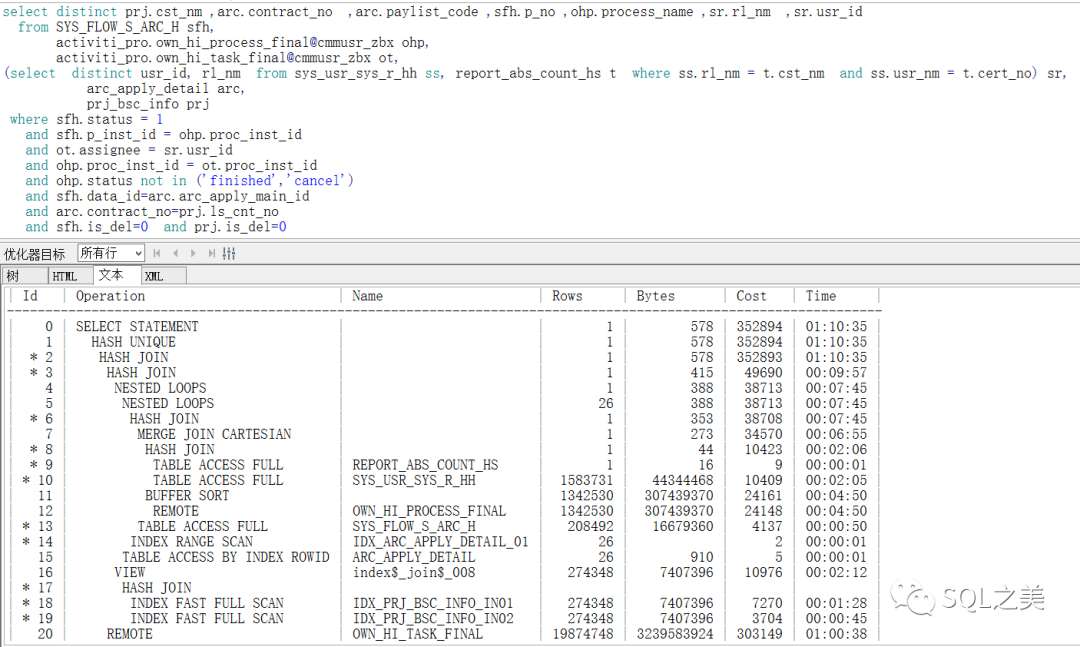
作为老司机,F5直接看执行计划是速度最快的方式(看个人习惯,新手千万别这么看执行计划,这里执行计划rows-cost等参数 经常是错误的),看过前文知道都知道啥原因, 原厂大佬都喜欢ALLSTATS LAST ,最为准确。
小技巧:执行计划使用dblink经常无法准确看到remote对应的table_name 到底是啥,但是如果你是用的dblink是主库拥有DBA权限的用户建立的,表名是可以显示的。
让我们开始分析思路,不要着急上来先看执行计划哈:
首先了解表量级:


这里我们在观察到 千万级大表有两张,百万级有一张,值得庆幸的是我们的主驱动表仅有7989条数据。执行计划只有arc_apply_detail ARC表的数据量估算出现了很大的误差!数据情况我们大概了解了,再看执行计划,老司机基本一眼看出笛卡尔积出问题概率最大,让我们验证下:

1条与52条 跟一个百万级表关联,那么效果是几乎一样的,cost估算出来的估计确实是当前几百个执行计划里面最优的了。4.这时候 我们就需要尝试 让ORACLE按照我们自己的想法来关联!按照数据量最小的驱动顺序 我们想要的应该是 :SR->OT->OHP->SFH->ARC->PRJ稍有经验的DBA,这里脑海已经构建出各种hint了,让我们来体验下最终版:

GG。。并没有改变,我们有时候优化SQL经常会遇到这种无法改变执行计划的问题,这种SQL收集100%统计信息也是没用的(敢开启动态采样5级以上当我没说。。)这时候我们就需要另辟蹊径,毕竟CBO的智能化也是有限的:将SR表使用with挂上去 并no_merge防止胡乱展开:
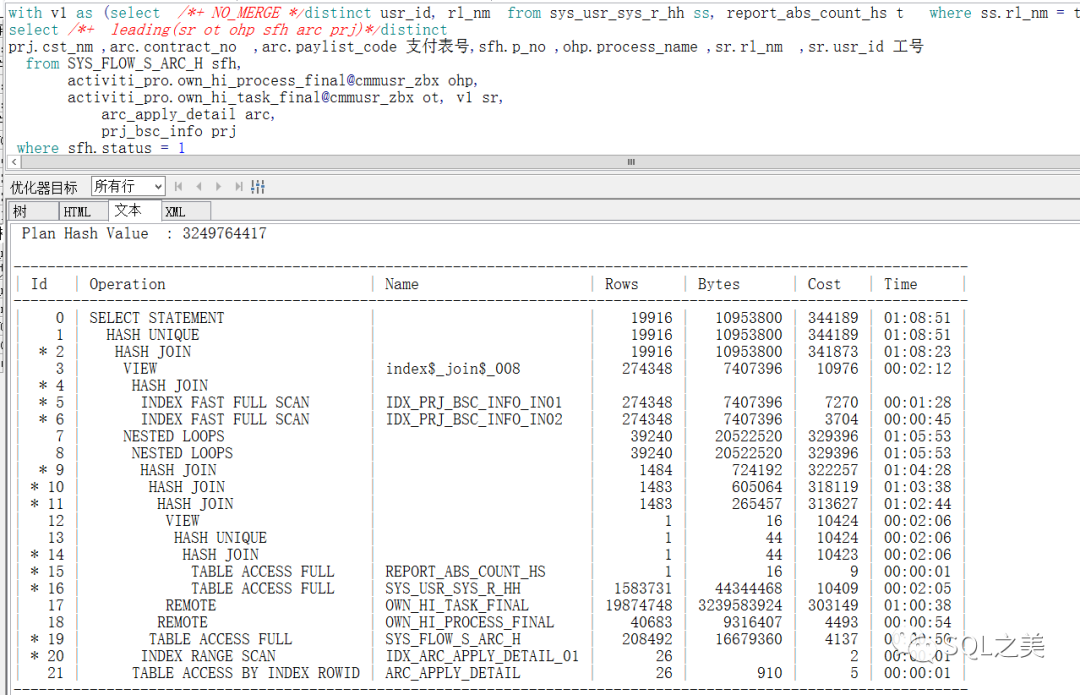
果然,执行计划变了!可以看到这里估算的cost也比之前的少了1W(虽然这里大部分情况是假的,但不妨碍我们作为问题参考),最终,52S执行完毕。同时,执行完成以后 你会发现 你原来的hint生效了!这是因为有了一次更优的SQL执行计划,CBO会自动记录并取代之前的,类似于ACS的概念。