




这篇文章研究了一个常见的数据库设计决策,涉及选择使用BIGINT与INT数据类型。您可能已经知道,与BIGINT数据类型(每个值INT4 个字节)相比,数据类型使用了两倍的磁盘存储空间(每个值 8 个字节)。知道这一点,一个常见的决定是尽可能使用INT,仅BIGINT在很明显*列将存储大于 21.47 亿(最大值INT)的值 时才使用 。
我也是这样做的,直到 2-3 年前!我开始改变我的默认心态,使用BIGINTover INT,扭转我长期以来的习惯。这篇文章解释了为什么我默认使用BIGINT 并检查决策对性能的影响。
TLDR;
正如我最后总结的那样:
我在这里运行的测试表明,具有适当大小的硬件的生产规模数据库可以毫无问题地处理这种轻微的开销。
为什么默认为BIGINT?
主要原因默认为BIGINT是为了避免 INT对BIGINT迁移。需要在最不合适的时候INT 进行BIGINT迁移,而且任务很耗时。这种类型的迁移通常涉及至少一个用作 a 的列PRIMARY KEY,并且通常FOREIGN KEY 在其他地方用作 a也必须迁移的其他表。
本着防御性数据库设计的精神,BIGINT 是最安全的选择。还记得上面提到的*明显的部分吗?计划和估算是一个困难的话题,人们(包括我自己)总是会出错!是的, using 有开销BIGINT,但我相信与额外 4 个字节相关的开销对于大多数生产数据库来说是微不足道的。
如果您在 2021 年拥有生产数据库,我将假设:
- 快速固态硬盘
- 足够的内存
- 足够的CPU
设置测试
这篇文章中的测试使用了具有 8 个 AMD CPU 和 16 GB RAM 的 Digital Ocean Droplet。Ubuntu 20.04 和 Postgres 13。
我使用功率为一半的服务器和功率为两倍的服务器执行了额外的测试。相应地调整了数据规模,并且在每组测试中都观察到了类似的结果。
我创建了两个数据库,INT一个用于BIGINT. 数据库的名称有助于跟踪哪个结果与哪个测试相关,并且数据库名称通过htop和显示在命令中iotop。
CREATE DATABASE testint;
CREATE DATABASE testbigint;
在数据库中设置pgbench结构。使用 100 作为比例会导致最大表 ( )中有 1000 万行。–scale=100testintpgbench_accounts
pgbench -i -s 100 testint
...
done in 14.31 s (drop tables 0.00 s, create tables 0.00 s, client-side generate 9.48 s, vacuum 1.74 s, primary keys 3.09 s).
14秒,不算太寒酸。pgbench使用这些表,int4 因此该数据库已准备好测试INT数据类型的性能 。
现在用于pgbench准备testbigint相同规模的数据库。
pgbench -i -s 100 testbigint
该testbigint需求有INT转换成列BIGINT进行测试。我使用dd.columns PgDD 扩展中的视图 来构建将所有int4( INT) 列更改为int8( BIGINT) 数据类型所需的查询。
SELECT 'ALTER TABLE ' || s_name || '.' || t_name || ' ALTER COLUMN ' || column_name || ' TYPE BIGINT;'
FROM dd.columns
WHERE s_name = 'public'
AND t_name LIKE 'pgbench%'
AND data_type = 'int4'
;
上述查询返回以下ALTER TABLE命令。
ALTER TABLE public.pgbench_accounts ALTER COLUMN aid TYPE BIGINT;
ALTER TABLE public.pgbench_accounts ALTER COLUMN bid TYPE BIGINT;
ALTER TABLE public.pgbench_accounts ALTER COLUMN abalance TYPE BIGINT;
ALTER TABLE public.pgbench_branches ALTER COLUMN bid TYPE BIGINT;
ALTER TABLE public.pgbench_branches ALTER COLUMN bbalance TYPE BIGINT;
ALTER TABLE public.pgbench_history ALTER COLUMN tid TYPE BIGINT;
ALTER TABLE public.pgbench_history ALTER COLUMN bid TYPE BIGINT;
ALTER TABLE public.pgbench_history ALTER COLUMN aid TYPE BIGINT;
ALTER TABLE public.pgbench_history ALTER COLUMN delta TYPE BIGINT;
ALTER TABLE public.pgbench_tellers ALTER COLUMN tid TYPE BIGINT;
ALTER TABLE public.pgbench_tellers ALTER COLUMN bid TYPE BIGINT;
ALTER TABLE public.pgbench_tellers ALTER COLUMN tbalance TYPE BIGINT;
该ALTER TABLE查询被保存到一个.sql文件,可以很容易地与总的时间运行。
nano pgbench_int_to_bigint.sql
该ALTER TABLE查询耗时1分8秒。这意味着更改数据类型所用的时间 比从一pgbench 开始创建整个数据库所用的时间长54 秒!
time psql -d testbigint -f pgbench_int_to_bigint.sql real 1m7.863s user 0m0.032s sys 0m0.013s
这里最大的表只有 1000 万行。随着数据增长到 20 亿行,等待时间会变长!
在这一点上,我VACUUM ANALYZE对两个数据库都做了一个并重新启动了实例。
简单的性能检查
我选择了一个帐号 ( aid) 并针对两个数据库测试了这个查询。
EXPLAIN (ANALYZE)
SELECT *
FROM public.pgbench_accounts
WHERE aid = 9582132
;
输出的重要部分是时序(以毫秒为单位),如下表所示。在任一数据库上重新运行查询会返回 0.040 - 0.100 毫秒范围内的结果,两者之间没有明显的赢家。查询计划(未显示)是相同的,包括估计成本。
| 查询 | 数据类型 | 执行时间(毫秒) |
|---|---|---|
| 简单选择 | 情报局 | 0.040 |
| 简单选择 | 大数据 | 0.044 |
以下查询是一个更复杂的查询,希望能更多地突出差异。过滤器 ( WHERE bid = 1) 在一个INT/BIGINT列上使用序列扫描, 同时将多个聚合应用于该abalance列,另一个INT/BIGINT列。此查询示出了用于轻微的性能优势INT超过BIGINT在2%的范围内,以3%。虽然性能上存在细微差别,但时间差异小于 20 毫秒,对于需要半秒的查询来说,这几乎不是主要问题。
EXPLAIN (ANALYZE, COSTS OFF)
SELECT COUNT(*) AS accounts,
MIN(abalance), AVG(abalance)::FLOAT8, MAX(abalance), SUM(abalance)
FROM public.pgbench_accounts
WHERE bid = 1
;
| 查询 | 数据类型 | 执行时间(毫秒) |
|---|---|---|
| 序列扫描和聚合 | 情报局 | 514 |
| 序列扫描和聚合 | 大数据 | 527 |
指标更重要
索引的快速切线。pgbench 初始化脚本不索引pgbench_accounts.bid列。上述查询过滤上bid并汇总余额说明了一个合适的索引策略会对性能大得多的影响则选择INT或BIGINT数据类型!
查看pgMustard 的查询计划工具中的聚合查询会突出显示缺失的索引。BIGINT 查询的计划 报告序列扫描耗时 460 毫秒(甚至在 3 个线程上!),占整个 500 毫秒执行时间的 92%!pgMustard 正确地建议为该建议添加bid 一个 5 星评级的索引到列。
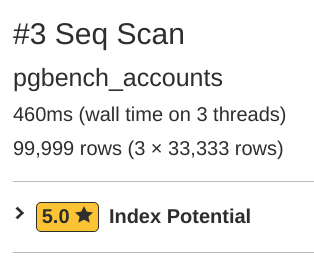
我添加了索引。
CREATE INDEX ix_pgbench_accounts_bid
ON public.pgbench_accounts (bid);
BIGINT通过使用索引,查询现在仅在 35 毫秒内运行!这是pgMustard的计划。有了适当的索引,INT 和之间的性能差异BIGINT就变得微不足道了。
更大规模的测试
上述测试着眼于单个查询级别的性能。此部分用于pgbench将数据库置于更重的查询负载下。
pgbench针对每个数据库使用的第一个命令旨在使服务器承受压力,但不会将其推到崩溃点。它使用–select-only选项跳过插入/更新查询。
pgbench -c 5 -j 1 -T 600 -P 60 --select-only <db_name>
这个-T 600针对testint数据库的10 分钟测试(以秒为单位)运行了 2500 万个事务,alatency average为 0.113 毫秒。在latency average由pgbench报告是花了执行查询和返回结果的时间。
number of transactions actually processed: 25009788 latency average = 0.113 ms latency stddev = 0.039 ms tps = 41682.966689 (including connections establishing) tps = 41683.153363 (excluding connections establishing)
针对testbigint数据库,pgbench 处理了 2530 万笔交易!这意味着BIGINT测试运行得稍微快一点,而不是更慢!🤔 平均延迟为 0.112 毫秒。
number of transactions actually processed: 25273848 latency average = 0.112 ms latency stddev = 0.033 ms tps = 42123.068142 (including connections establishing) tps = 42123.222043 (excluding connections establishing)
我重新运行了几次这些测试(就像我对所有测试所做的一样)并取得了一致的结果。我的预感是,这种意想不到的结果是我的快速测试方法的副作用。
更大的测试
对于给定的硬件大小,最后一组测试将数据库置于沉重的负载之下。这组测试着眼于在压力负载条件下会发生什么。这些测试打破了我之前关于数据库具有“足够 CPU”的假设。
以下pgbench命令将连接数从 5 增加到 20。第一个命令使用默认pgbench 测试,包括混合读/写查询。第二个使用–select-only上面使用的。
pgbench -c 20 -j 4 -T 600 -P 60 <db_name>
pgbench -c 20 -j 4 -T 600 -P 60 --select-only <db_name>
在这种较重的负载下,INT和之间的差异BIGINT 变得更加明显。TCP(类似)测试显示BIGINT每秒处理的事务数 (TPS) 比INT数据库少 8% 。Select Only 查询显示BIGINT处理的 TPS 减少了 6%。
| 台架试验 | INTTPS | BIGINT TPS | % 差异 |
|---|---|---|---|
| 读/写 | 7,538 | 6,959 | -7.7% |
| 仅选择 | 64,489 | 60,437 | -6.2% |
本节中模拟的负载太高,无法期望这种规模的服务器能够正常处理。有趣的是,它需要你的服务器正在为了看到性能明显下降,由使用严重的压力下BIGINT,而不是INT。
在针对testint 数据库运行读/写测试时,我从htop. 屏幕截图是在 10 分钟测试的 5 分钟标记处截取的,显示该服务器正在努力跟上查询。如果您的数据库服务器如此努力地工作,您应该制定一个扩大硬件规模的计划!
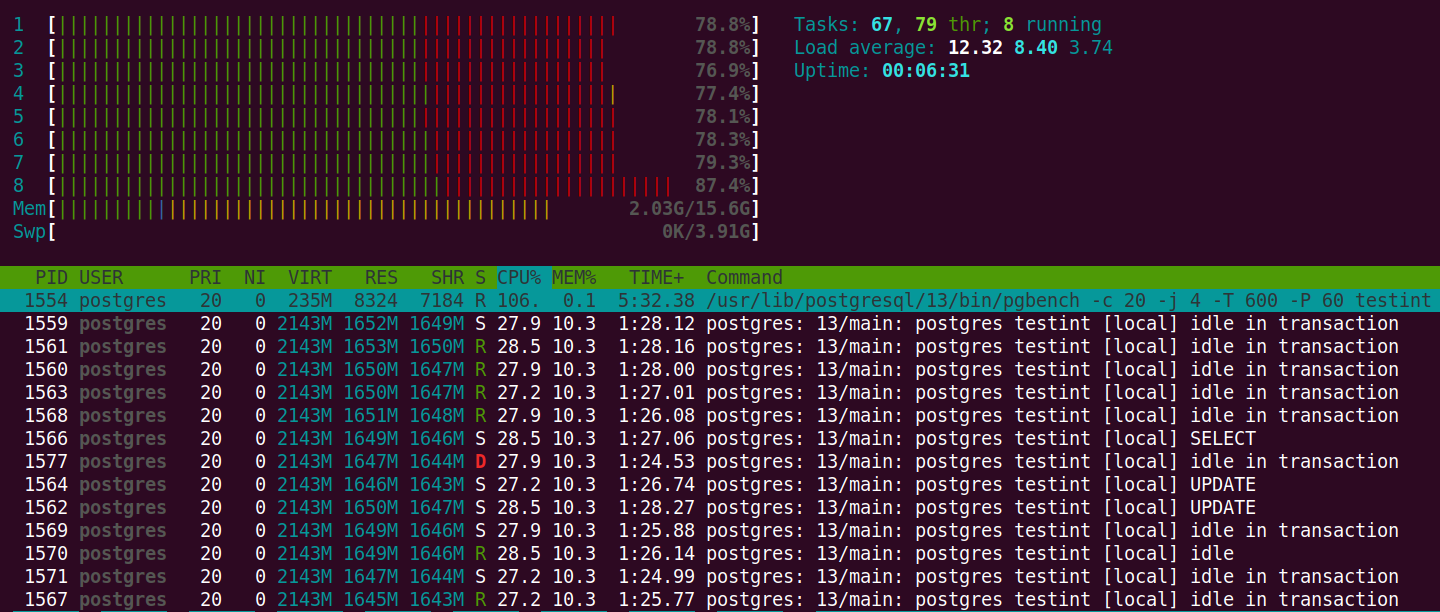
不使用 BIGINT
除非绝对必要,否则仍然有充分的理由选择避免BIGINT。不要将此概括性的建议作为列出非常具体的非标准用例的理由,这些用例受益于尽可能低的开销。你在向合唱团讲道……我知道!我喜欢在 Raspberry Pi 上运行 Postgres, 并且接受了不时出现的偶尔头痛。
下面是一些不完整的列表,其中使用INToverBIGINT 可能仍然是一个很好的默认值。
- 存储有限查找选项的表(例如是/否/可能)
- 低功耗、嵌入式传感、Raspberry Pi
- 有限网络带宽的限制
- 固执
我非常严肃地列出了顽固。毕竟,我在 2014 年发布的关于使用严重不足的服务器托管 Jira 的帖子 仍然定期访问!直到大约 2018 年左右,这些都是我最受欢迎的帖子。(很奇怪,对吧?)我顽固地让 Jira 工作,花了大量时间与它作斗争,我获得了大量经验,你只能通过艰苦的方式学习。正如我所写,我的固执让我痛苦:
“在第四次硬撞后(记住,我很固执)……”
总结
这篇文章介绍了为什么我将继续使用BIGINT作为默认值INT。最终,我选择全面采用轻微的开销,以避免不得不反复INT进行BIGINT迁移。我在这里运行的测试表明,具有适当大小的硬件的生产规模数据库可以毫无问题地处理这种轻微的开销。只有当服务器负载严重时,这些开销的细微差异才会转化为明显更慢的查询时间或吞吐量。
