




在《RocketMQ源码分析之消息写入》中提到RocketMQ中引入consumequeue和index的原因,本篇文章将围绕consumequeue和index中记录了什么信息以及如何构建consumequeue和index文件来展开。
首先我们先回顾下为什么要在RocketMQ中引入consumequeue和index。RocketMQ中所有topic的消息都存储在同一个文件中,这样虽然提高了消息发送及写入的性能及吞吐量,但是在RocketMQ中消息消费是基于topic消息订阅机制,这样便会给consumer消费和消息检索带来极大的不便,所以为提高消息消费的效率引入了consumequeue文件,为了提高消息检索的效率引入了index文件。
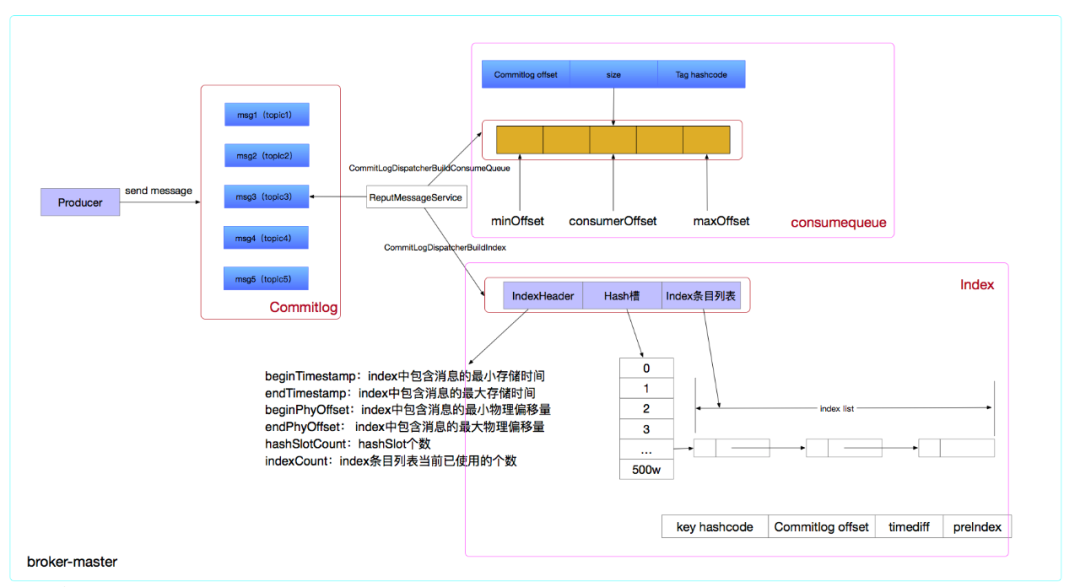
关于consumequeue,需要了解以下几点:
1.RocketMQ使用MappedFile和MappedFileQueue来封装consumequeue
2.consumequeue的文件组织形式是,在${ROCKET_HOME}/store/consumequeue/目录下第一级目录是topic名称,第二级目录是topic的queueid,最后一级是consumequeue文件(下图中每个consumequeue文件大小是260k)

3.consumequeue文件存储的不是全量的消息
4.consumequeue文件的命名方式和commitlog是一样的
5.默认情况下每个consumequeue包含30w个consumequeue条目,每个consumequeue条目占20个字节,所以每个consumequeue文件的大小是30w*20字节
consumequeue文件中都存储的信息如下:
消息在commitlog中的偏移量(8字节)
消息的大小(4字节)
消息tag的hashcode(8字节,存储tag的hashcode的原因是每个consumequeue条目都是定长的)
关于index文件,需要了解以下几点:
1.RocketMQ中是使用MappedFile来封装index文件
2.index的文件组织形式是${ROCKET_HOME}/store/index/,该目录下面是一个个的index文件,文件的名称是index文件创建时间戳

3.index文件大小是固定的
index文件分为三个部分,分别是IndexHeader(40个字节)、Hash槽(默认一个index文件包含500万个Hash槽,每个Hash槽占4个字节)和Index条目列表(默认一个index文件包含2000万个条目)。其中IndexHeader包含以下内容:
beginTimestamp:index中包含消息的最小存储时间
endTimestamp:index中包含消息的最大存储时间
beginPhyOffset:index中包含消息的最小物理偏移量
endPhyOffset:index中包含消息的最大物理偏移量
hashSlotCount:hashSlot个数
indexCount:index条目列表当前已使用的个数
每个Hash槽中存储的是落在该Hash槽最新的index条目。每个index条目记录以下信息:
key的hashcode
该消息对应的commitlog offset
该消息存储时间与第一条消息存储时间的差,如果差值小于0则表示该消息无效
index条目的前一条记录的index索引,当产生hash冲突时会构建链表结构,类似于Java中的HashMap
下面来看看如何构建consumequeue和index?
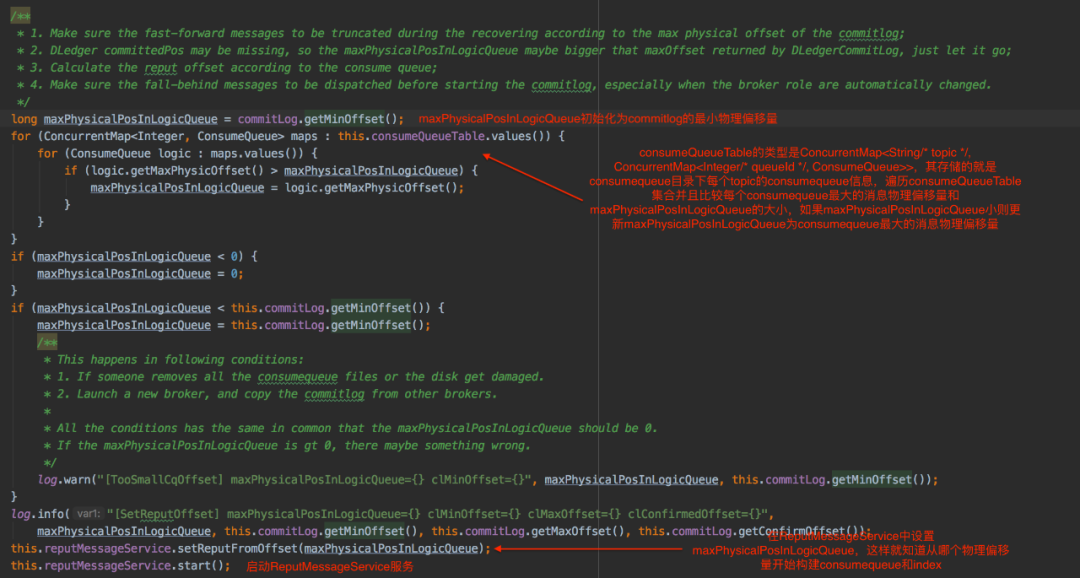
在RocketMQ broker启动的过程中会启动很多服务,其中就包含DefaultMessageStore,DefaultMessageStore启动的过程中会启动ReputMessageService,ReputMessageService的作用就是实时转发commitlog文件更新事件,然后会有对应的服务来构建consumequeue和index文件。在启动DefaultMessageStore过程中会初始化参数maxPhysicalPosInLogicQueue,参数maxPhysicalPosInLogicQueue表示从哪个commitlog offset开始构建consumequeue和index,maxPhysicalPosInLogicQueue初始化过程如下:
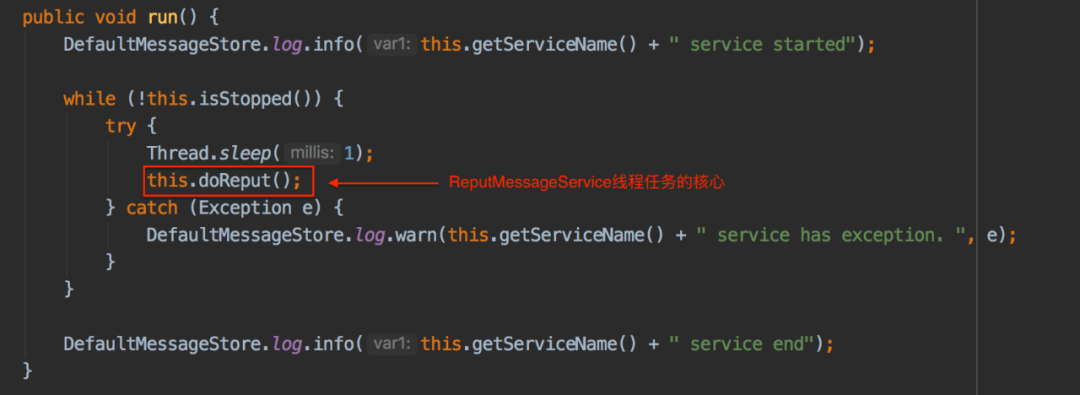
ReputMessageService线程执行任务的时间间隔是1毫秒:
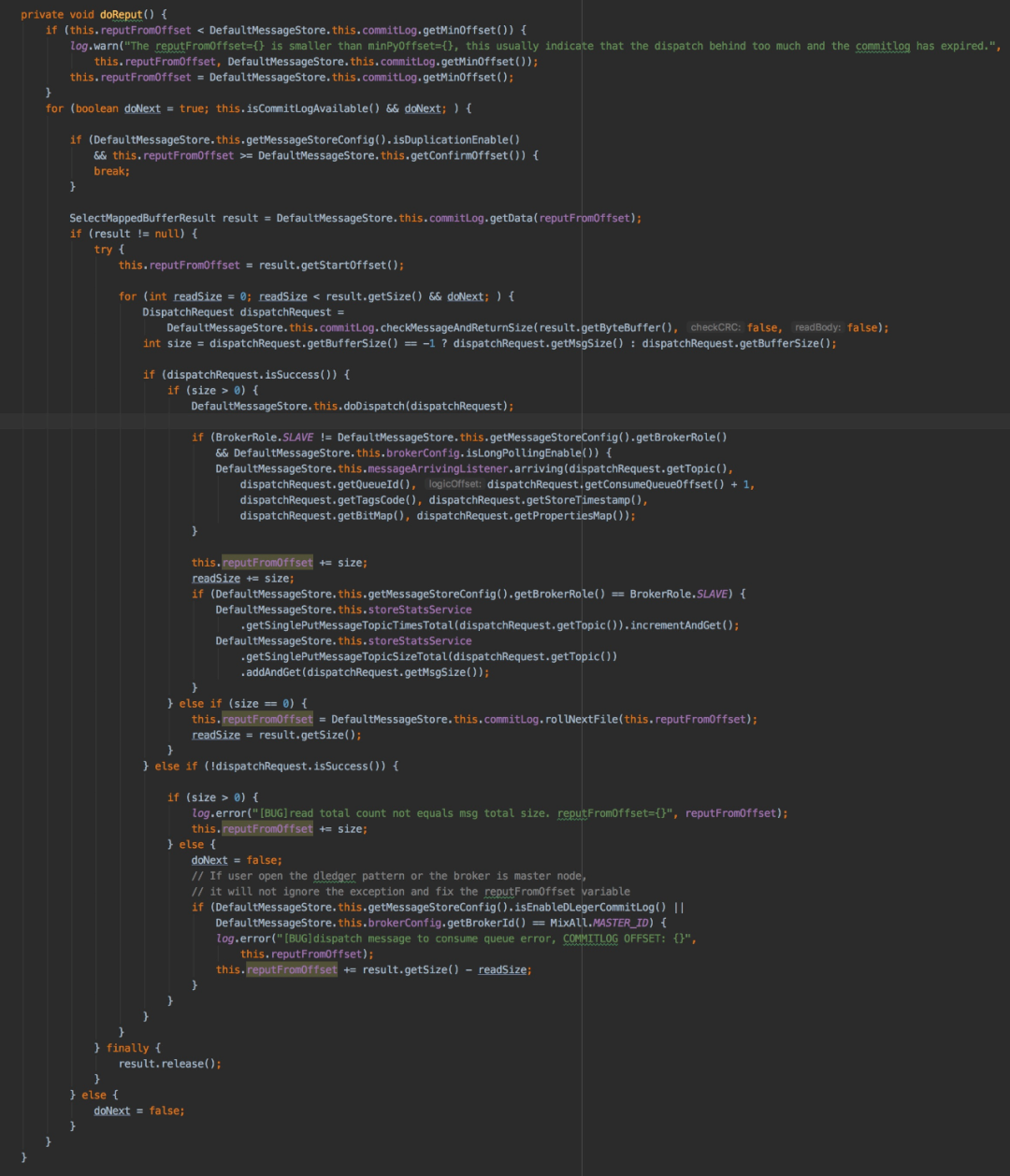
doReput()方法的实现逻辑是:
在commitlog中获取从reputFromOffset(maxPhysicalPosInLogicQueue)开始的数据
遍历从commitlog中获取到的数据并构建DispatchRequest对象,最后通过doDispatch方法来构建consumequeue和index文件
在遍历的过程中每当一条数据构建consumequeue和index完成的同时会更新reputFromOffset,当commitlog中一个mappedFile中的数据完成构建consumequeue和index的任务后会通过commitlog的rollNextFile方法来获取下一个mappedFile,然后再遍历数据并构建DispatchRequest对象通过doDispatch方法构建consumequeue和index
在初始化ReputMessageService时会在dispatcherList中添加构建consumequeue和index文件的服务,CommitLogDispatcherBuildConsumeQueue是用来构建consumequeue,CommitLogDispatcherBuildIndex是用来构建index:

doDispatch方法是通过遍历dispatcherList并根据DispatchRequest来分别构建consumequeue和index
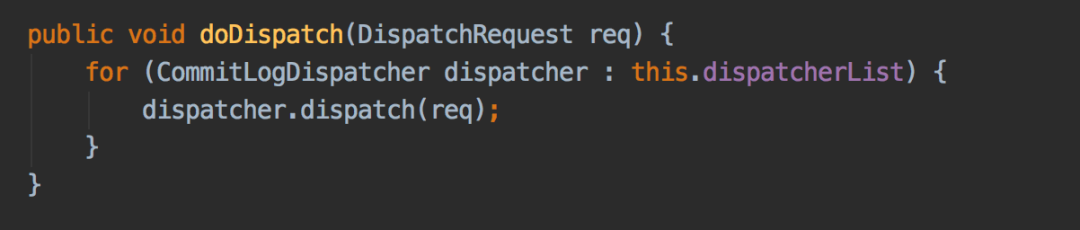
构建consumequeue的doDispatch方法如下,构建consumequeue的内部实现方法是putMessagePositionInfo(DispatchRequest dispatchRequest)
putMessagePositionInfo(DispatchRequest dispatchRequest) 的实现逻辑:
dispatchRequest中含有消息的topic及queueid,所以会根据topic和queueid获取consumequeue文件,findConsumeQueue(String topic, int queueId)方法获取consumequeue的实现逻辑是从consumeQueueTable中先根据topic获取目标topic的consumequeue集合(该集合是一个map,key是queueid,value是consumequeue),接下来根据queueid从consumequeue集合中直接获取consumequeue文件即可
通过调用putMessagePositionInfoWrapper方法将数据追加到consumequeue文件中

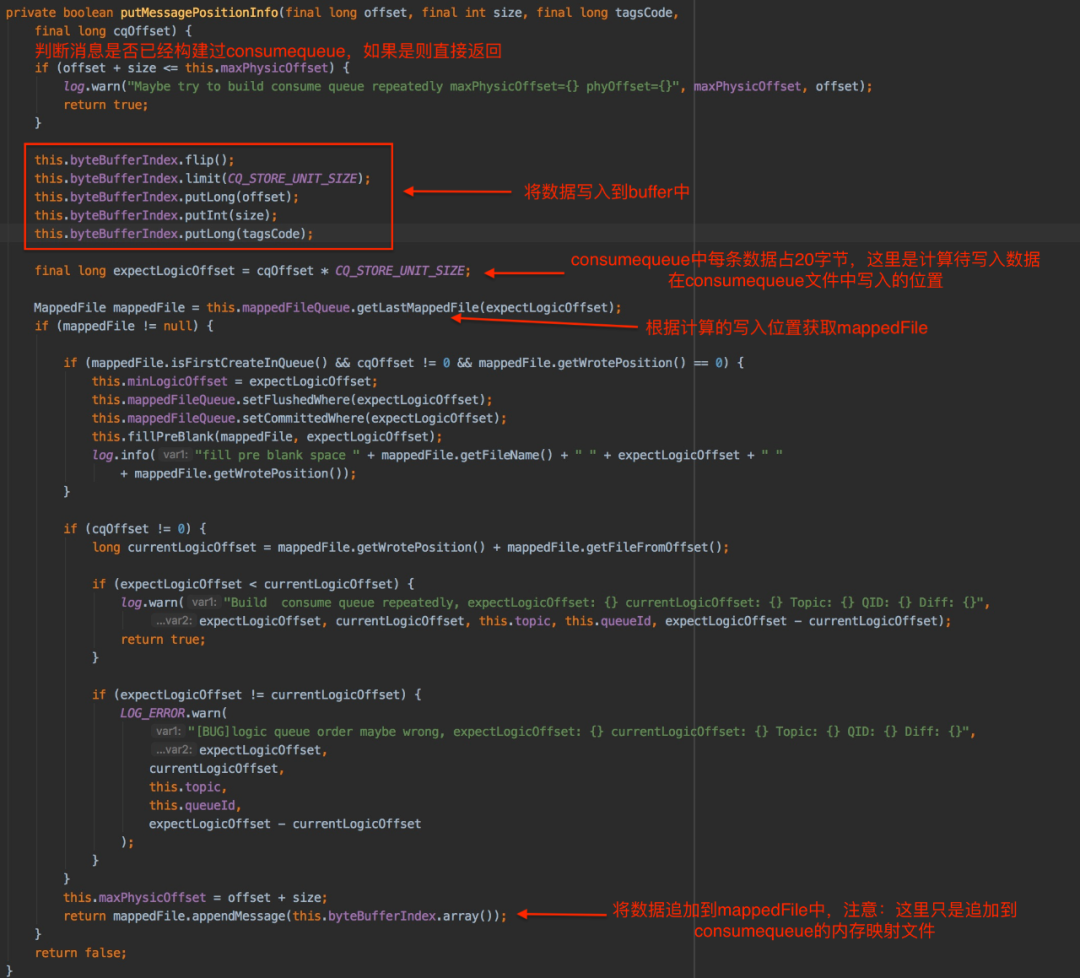
putMessagePositionInfoWrapper方法的实现中是通过putMessagePositionInfo(final long offset, final int size, final long tagsCode, final long cqOffset)方法实现追加数据到consumequeue文件的功能,具体如下:
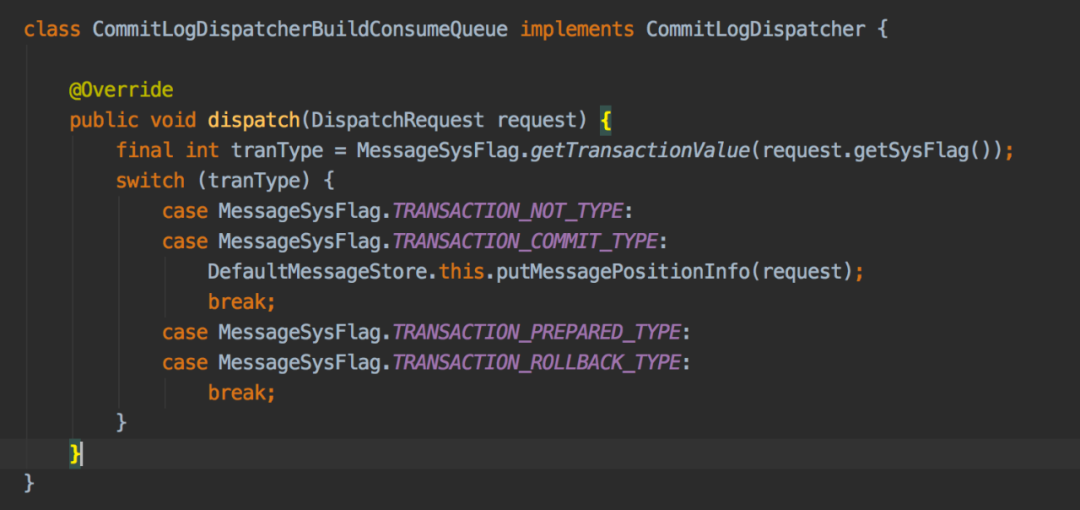
构建index的doDispatch方法如下,isMessageIndexEnable()方法是判断messageIndexEnable是否为true,如果是则调用IndexService的buildIndex方法来构建index文件

buildIndex(DispatchRequest req)方法的实现逻辑如下:
获取最后一个index文件
获取index文件中包含消息的最大物理偏移量
从DispatchRequest中获取消息的topic和key
判断待构建index的消息的commitlog offset是否小于index文件中包含消息的最大物理偏移量,如果是则表示该消息已经构建了index直接返回即可
如果消息的UniqKey不为null,则先根据消息的topic和UniqKey构建出形如“topic # key”的index key,然后使用putKey方法构建index信息,该方法的核心实现是putKey(final String key, final long phyOffset, final long storeTimestamp)
RocketMQ中支持为同一条消息构建多个索引,所以如果该消息中包含多个key则会为该消息创建对应数量的索引

构建index key的方法如下:

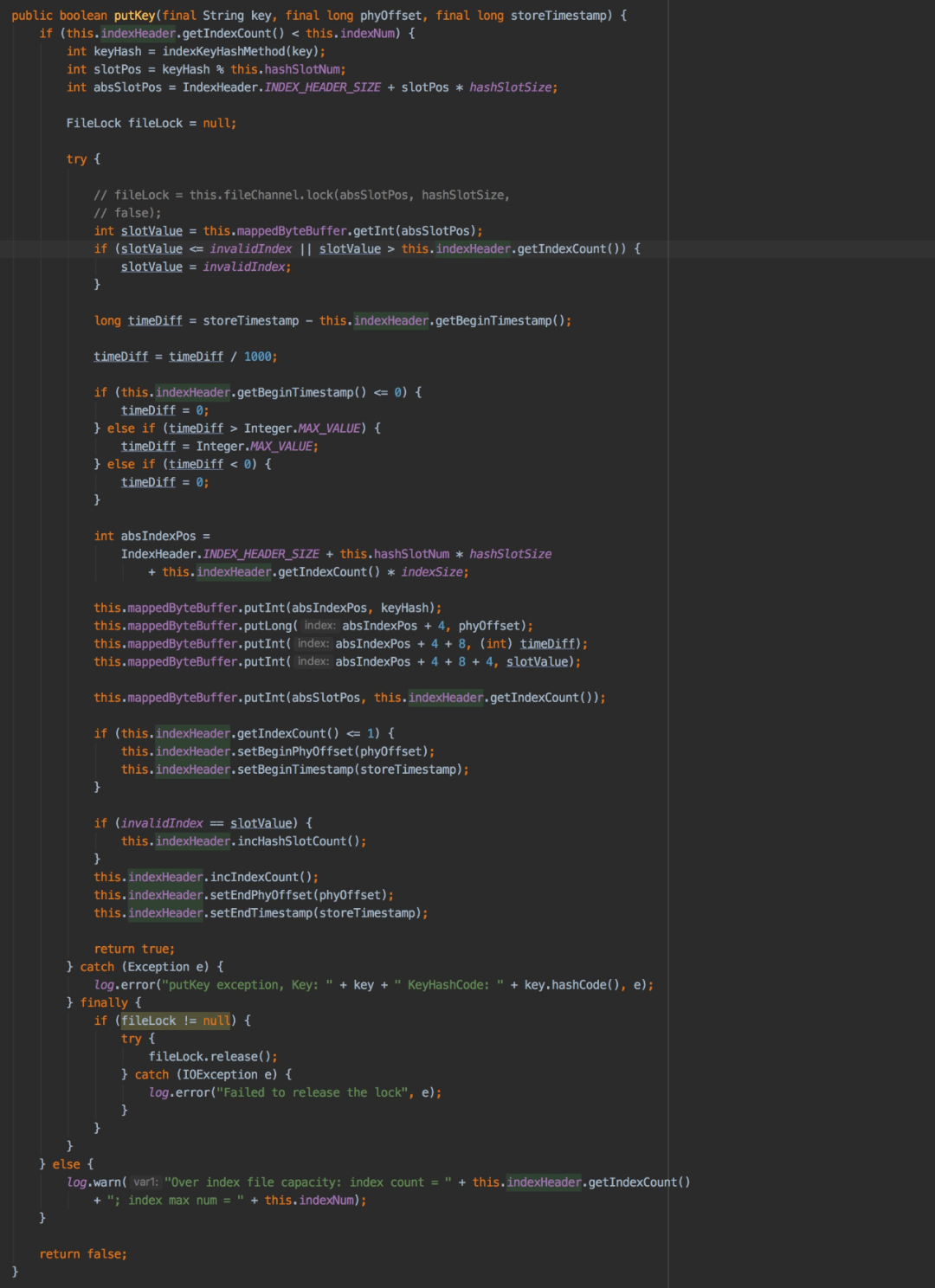
下面详细分析putKey(final String key, final long phyOffset, final long storeTimestamp) 的实现逻辑,也就是如何构建索引并写入index文件中:
根据消息topic和key构建出的index key来计算hashcode keyHash
通过“keyHash % index文件中hash槽的数量”来计算是第几个槽(slotPos)
通过“IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize”计算槽的物理位置absSlotPos
读取槽中的数据slotValue,如果slotValue小于等于0或者大于当前index文件中存储的索引条目数则将slotValue设置为0
计算消息的存储时间与index文件中第一条消息的存储时间的差值timeDiff
通过“IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize + this.indexHeader.getIndexCount() * indexSize”来计算待添加的索引在index文件中的存储位置absIndexPos
依次将hashcode、消息的commitlog offset、消息存储时间及当前hash槽的值slotValue写入mappedByteBuffer中
将当前index文件中包含索引信息的数量写入hash槽中
更新index文件的IndexHeader
作者简介
孙玺,中国民生银行信息科技部开源软件支持组工程师,目前主要负责RocketMQ源码研究和工具开发等相关工作。
