





在上一篇《「「召回层」召回模型的样本挖掘》)中介绍了绍召回层模型的样本挖掘
方法。本文将介绍召回层常用的效果评估
方法。
预告:
下一篇我们将一起学习A/B Testing。感兴趣的同学别忘了点个关注哦!
在推荐系统中,经常需要在现有的召回体系下开发各种召回方法。在上线一种召回方法前,需要知道它会对系统造成怎样的影响(如正向收益还是负向收益),即需要评估召回方法对推荐系统的效果。通常可以从离线和在线两个方面进行评价。
一、离线评估
1、为什么要离线评估?
推荐系统最有效的方法就是采用线上A/B Testing来评估模型之间效果。但是由于线上AB的成本高、效率低等原因,通常在模型上线前会对其进行离线评估。在确定模型的离线效果足够(如离线指标相对提升x%)后才会对其进行线上评估。
推荐系统中离线评价指标主要分为如下三大类:
评分评估指标:用于对预测的评分进行评估,适用于评分推荐任务 集合评估指标:用于对推荐的item集合进行评估,适用于Top-N任务 排名评估指标:按排名列表对推荐效果进行加权评估,既适用于评分推荐任务也可用于Top-N任务
召回层通常返回的是item集合。而最终呈现给用户的item是经过精排、重排层处理后的最终结果。由于召回层不直接作用于用户,在对召回算法进行离线评估时一般采用集合评估指标。
2、主要评估指标
A) Recall、Precision、F1
召回层最常用的3个指标:Recall(用户全部点击中有多少item被召回了),Precision(召回的item中有多少被用户点击了)和F1-Measure(Recall和Precision的调和平均)。
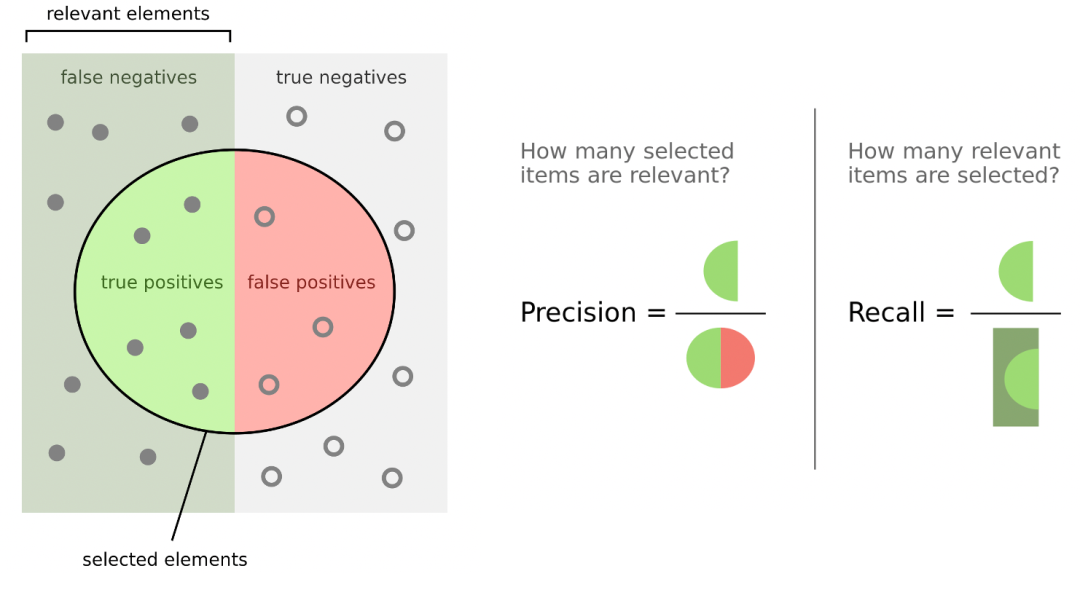
对于每个用户(全部用户集合为),令表示用户的召回列表,表示用户在测试集中的点击列表:
由于和对召回的Item数非常敏感,一般采用来综合评估算法的效果。此外,对于召回的Item数一般选择100、200、500。
B) NS-recall、NS-precision
NS(negative sampling)-recall和NS-precision为负采样的召回和准确率,用于衡量相对于随机,该算法能否发现用户感兴趣的Item。主要流程如下:

简单来讲就是如下图所示:
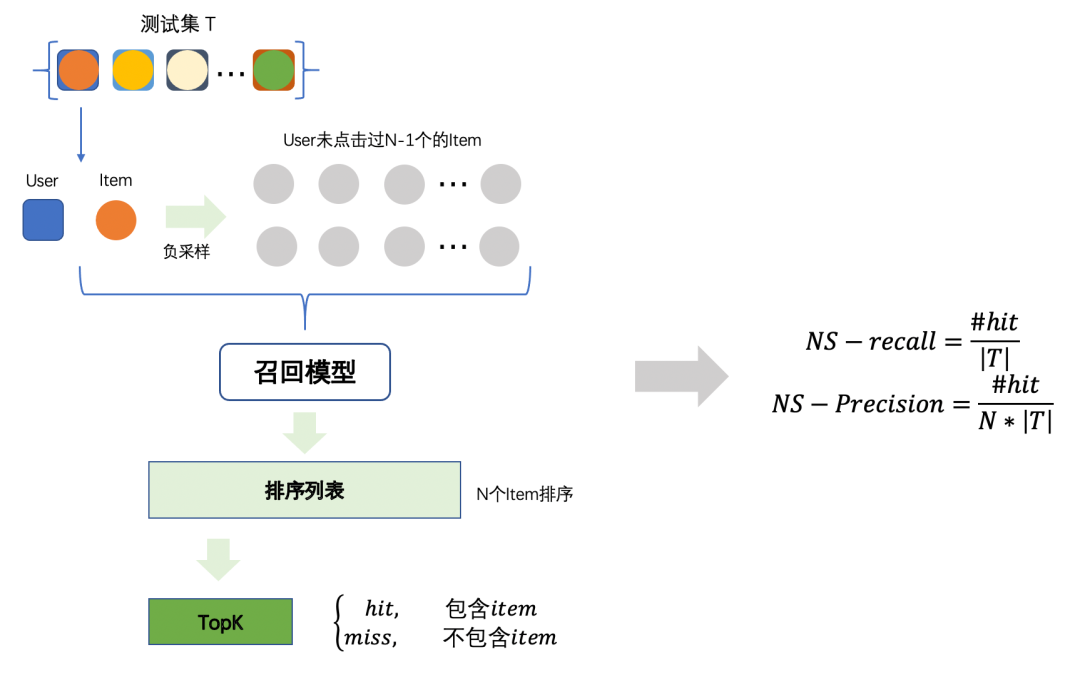
对测试集(只有用户点击的Item)的每一个<u,item>的pair对,随机从未点击的中采样个item作为负样本(如1000个),构成针对<u, item>的样本数为的测试集;然后用模型对其进行排序,利用Top-K召回,如果在召回的列表里,则记为。指标计算如下:
其中,表示被召回的<u, itme>数,NS-precision中的分母为,即每个点击事件<u, item>是从个人工构造(点击+负采样)的候选集中选择。
传统的recall和precision是将用户所有点过的看做一个大集合进行召回评估,但由于用户对item的点击天然是power-law分布,为所有用户都召回TopK的候选集,会造成用户间指标差异较大,使得指标评估不稳定。而NS-recall和NS-precision是针对每个<u,item>对进行评估,相当于单独评估每个点击事件在召回列表中的可能性,指标相对稳定。
C) HR, ARHR
HR(Hit Rate)是Top-N推荐常用的评价指标,公式如下:
其中,表示测试集中的item出现在Top-N列表中的用户数量,表示用户数。
ARHR(Average Reciprocal Hit Rank)是一种加权的HR,用来衡量一个item被推荐的强度:
其中表示在推荐列表的位置。
D) 长尾评估
在推荐系统中,一个十分常见的现象是长尾效应:流量集中在少数的头部Item中。
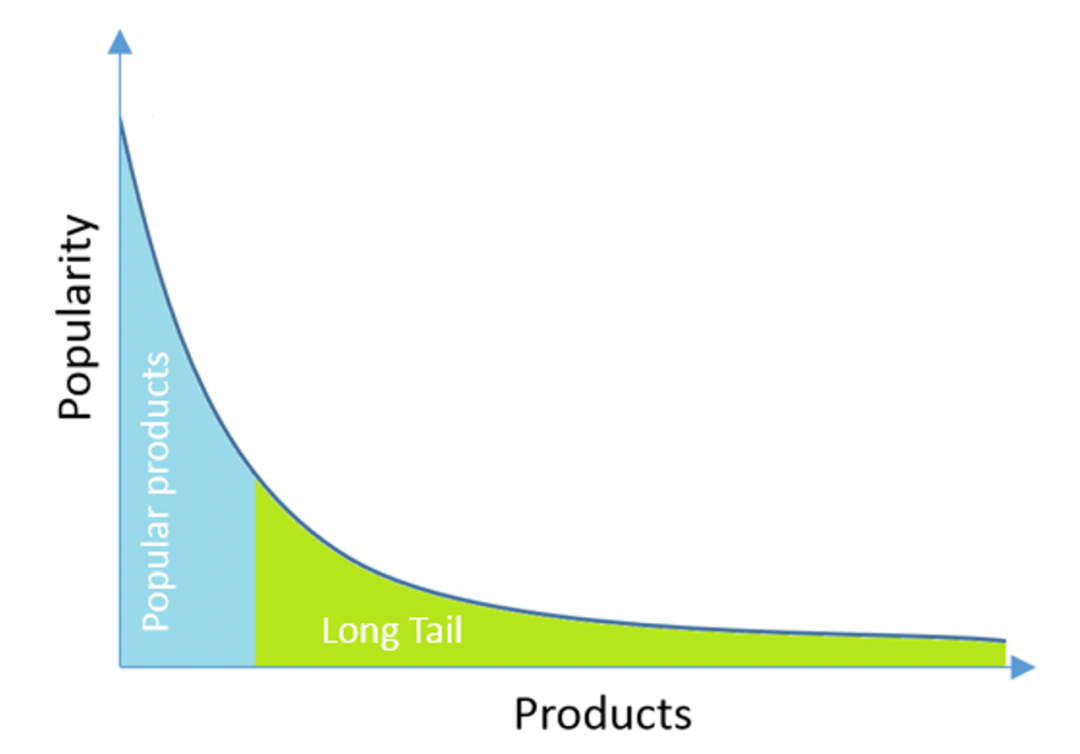
显然,上述指标容易受头部数据的干扰,此外大部分召回算法对长尾item的学习效果不如头部好。因此,为了评估召回方法对长尾Item的效果,可以单独增加长尾指标。
一个简单的做法是:将头部(如1%)的item剔除,仅保留剩下的(如99%)的item,然后上述指标进行评估评估。
3、离线评估存在的问题
虽然离线评估能有效的提升模型开发的效率,但离线评估同样存在一些问题,如:
评价结果的不够客观:由于用户行为的主观性,不管离线(在单次数据集上的)评估的结果如何,都不能得出用户是否喜欢某个推荐算法推的物品的结论,只是一个近似的评估。
离线评估效果不能代表线上效果:通常在上线模型是会遇到离线评估指标提升明显,但上线之后效果惨不忍睹。虽然大多数情况是由于模型目标设计、样本构造、特征选择过程中出现了问题导致的。但这些问题在离线评估时却很难被暴露出来。
冷启动问题:对于冷启动,离线评估由于缺乏用户行为,无法有效评估
Exploration和Exploitation问题
因此,离线评估通常只作为一个参考指标,帮助我们提升模型迭代速度。模型最终效果还是要通过线上A/B Testing
来评估。
二、线上评估
推荐系统线上通常采用A/B Testing
来对比模型之间的效果。A/B Testing基本流程如下图所示:
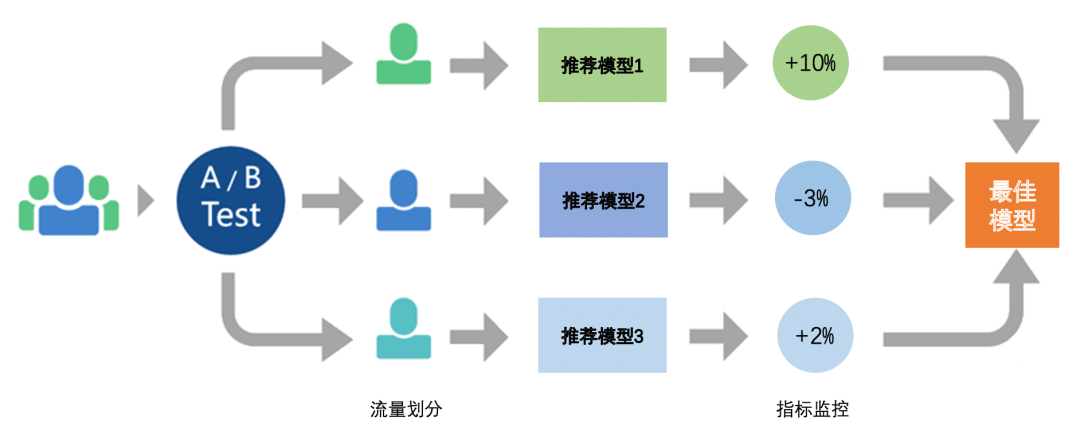
首先,在模型上线前,需要设定指标,设置核心指标来评估模型的优劣(如点击率、转化率、时长等),设置辅助指标来评估模型的其他影响(如留存、分享等);
然后,确定测试时长和分流方案,流量分配上要保证个实验组流量是同质的;
之后,线上数据采集和指标监控,根据线上行为数据,计算监控指标;
最后,基于监控指标,分析模型效果,并最终确定是否上线(替代线上版本)。
P.S. 对于A/B Testing
本文仅简单介绍其基本流程。会在下一篇详细介绍具体细节,感兴趣的可以关注下。
参考文献
[1] Cremonesi, Paolo, Yehuda Koren, and Roberto Turrin. "Performance of recommender algorithms on top-n recommendation tasks." Proceedings of the fourth ACM conference on Recommender systems. 2010.
[2] Ning, Xia, and George Karypis. "Slim: Sparse linear methods for top-n recommender systems." 2011 IEEE 11th International Conference on Data Mining. IEEE, 2011.
[3] Muffaddal Qutbuddin, An Exhaustive List of Methods to Evaluate Recommender Systems, 2020.
[4] Amy Gallo, A Refresher on A/B Testing, 2017.
[5] Wikipedia: Precision and recall
