





❝「泛函的范」是记录和分享作者在(腾讯)搬砖过程中对业务问题的思考和解决方案,以及积累在推荐领域的知识。
关键词:推荐系统、机器学习、记录&分享
感兴趣的同学可以顺便点个「关注」
❞
在上一篇《数据之上模型之下是特征构造》中介绍了在做推荐业务时如何构造特征,本篇将介绍在推荐系统中被广泛应用的“「特征交叉」”技术,希望能帮大家进一步理解“交叉”的思想。
「预告」:下一篇将从面试官角度来解答在面试中经常遇到的开放性问题:
❝现在有一个xxx应用场景,需要在其中的feeds推荐图文和视频。如果交给你来做,你会怎么做?
❞
感兴趣的同学别忘了点「关注」哦!
一、什么是特征交叉
特征交叉(Feature Crosses)也叫特征组合,是指通过将两个或多个特征相乘,实现对样本空间的非线性变换,来增加模型的非线性能力。
从本质上讲:特征交叉是利用非线性映射函数f(x)将样本从原始空间映射至特征空间的过程:
是不是非常像机器学习中的kernel trick?
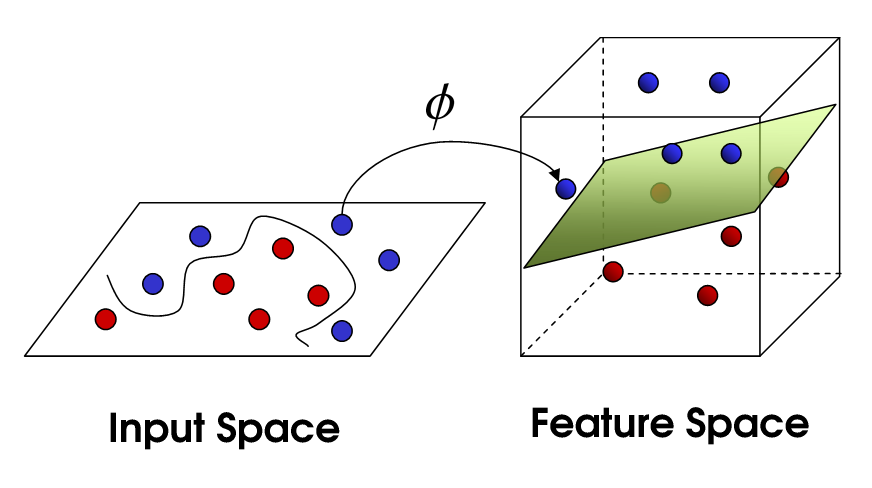
其实,特征交叉可以认为是kernel trick的一种:显性指明kernel的规则,来将样本从原始空间映射到高维特征空间中。以二阶交叉为例:
原始样本空间: 二阶交叉: 最终特征空间:
假设有两个样本:和,经过上述交叉之后得到新的特征分别是和,则有:
这个正好是二阶多项式核。
既然特征交叉是kernel trick的一个特例,那直接使用kernel trick不是更方便么?
理论上是当然可以的:
以 SVM
为基础模型,使用kernel trick来做非线性变换,从效果上来说肯定会比当前主流的特征交叉+LR
好。
但在工业上还要考虑一个非常重要的问题——「效率」。在面对千万级别样本时,采用kernel trick不管是离线训练还是线上推理,其耗时都是不可接收的。虽然模型的理论效果很好,但终究无法解决实际问题。
那有人可能就会走到另一个极端:是不是可以借鉴RBF kernel
的思想(将样本映射到无穷维空间,总能找到分类面)疯狂构造交叉特征(就是传说中的「无脑交叉」)。
❝小插曲:为什么说
RBF kernel
能将样本映射到无穷维空间,看下面:❞
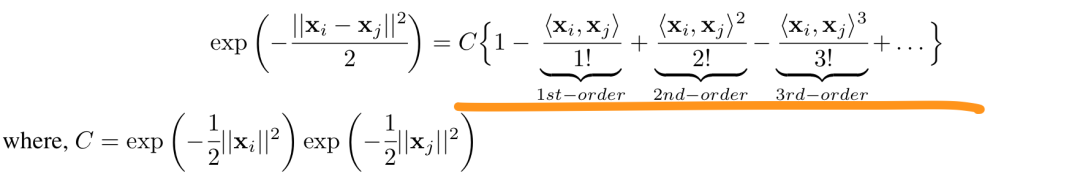
理论上也是可以的,但显性交叉会面临另一个问题「维度灾难」(Curse of dimensionality):
特征维度一旦多了就需要更多的样本来覆盖对应特征。比如使用 用户ID
和物品ID
做笛卡尔积就会导致特征维度瞬间爆炸至千万维,但此时并没有足够的样本能覆盖到对应的特征,最终导致特征极度稀疏,模型「过拟合」。特征维度增加还会进一步加重存储负担,以及模型线上的推理效率
因此,在推荐系统中选择用于交叉的特征是要依赖对当前业务的理解的,尽量构造具有可解释性且符合数据规律的交叉特征,如
用户类型与品类交叉,可以表示不同用户的品类偏好 用户年龄档与类别交叉,可以表示不同年龄段用户的品类偏好 用户职业与时间交叉,可以不同职业在不同时间上的分配特征 用户的价格偏好与物品的价格等级的交叉,可以表示物品价格与用户消费能力的匹配程度
二、为什么要特征交叉
现在我们再来说说为什么要做特征交叉(其实到这里,读者应该已经有答案了),特征交叉的目的是「提升模型的效果」:
通过特征交叉,将样本映射至高维空间,从而增加模型的非线性能力,提升模型的预测效果。
下面就以playground.tensorflow.org为例来看下交叉特征对效果的提升(感兴趣的可以点击链接去玩玩):
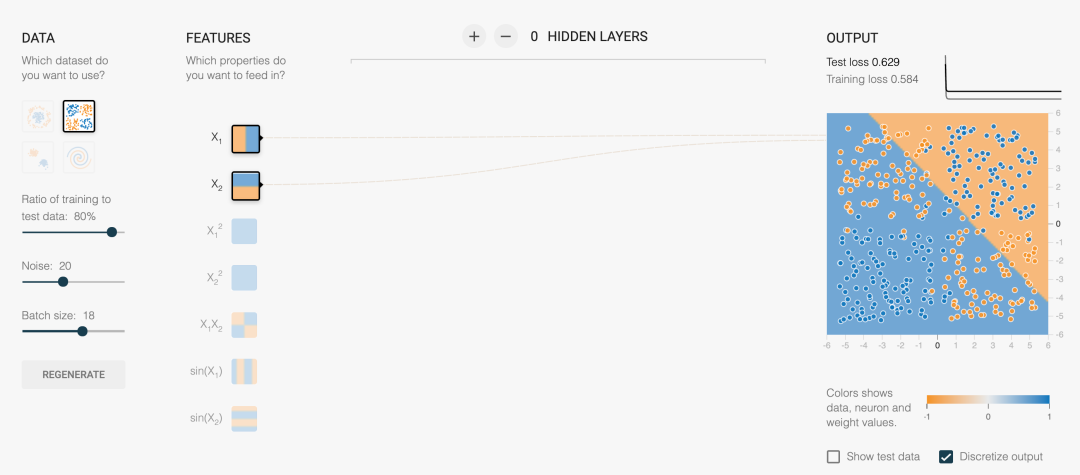
面对上面的数据集,采用LR
来无论如何调整参数都无法有效分开正负类:线性分类器无法有效解决非线性可分问题。
既然原始特征不行,那我们可以构造二阶交叉特征来提升模型效果:

此时,我们可以看到通过引入交叉特征后,模型非线性能力提升了:模型的决策边界由原来的线性,变成非线性了,此时已经可以较好的区分正负类了。
三、特征怎么交叉
特征交叉主要有两大类:1) 显示交叉;2) 隐式交叉
1、显示交叉
显示交叉主要是基于先验知识通过人工来手动构造交叉特征,这里主要有三种类型的交叉:1)內积;2)哈达玛积;3)笛卡尔积。
在构造显性交叉特征时,一定要结合业务和数据分析来构造,切忌无脑交叉。
先假设有如下特征:
用户 U1
对游戏标签的偏好特征:{王者: 0.7, 和平: 0.2, 斗地主: 0.1}物品 I1
的受众对游戏标签的偏好特征:{王者: 0.4, 和平: 0.3, 斗地主: 0.3}
A) 內积 (Inner Product)
內积是两个特征对应位相乘之后求和,结果是一个标量(数值):
用户U1
和物品I1
在游戏偏好标签上的內积为:
內积的几何意义可以用来表征或计算两个向量之间的夹角。
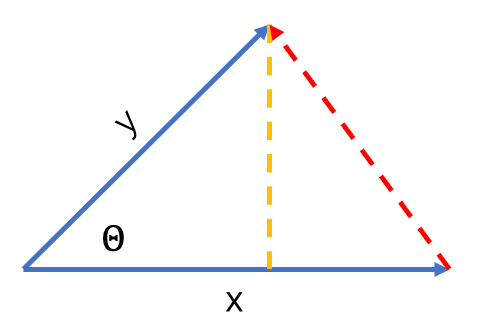
B) 哈达玛积 (Hadamard Product)
哈达玛积是特征对元素的乘积,最后结果还是对应维度的向量:
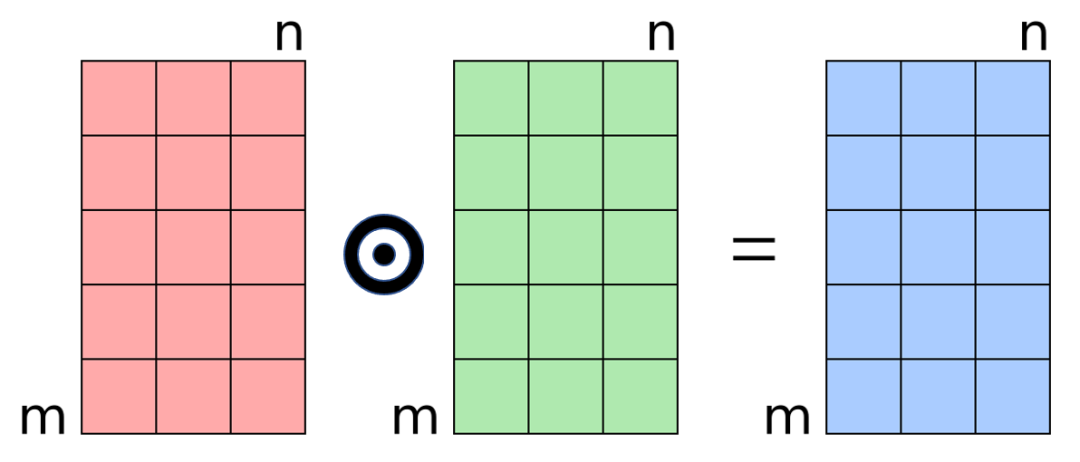
可以用来表示特征的对应维度的匹配程度,如王者
偏好的用户会在高王者
特征的物品上有更强的表现。
用户U1
和物品I1
在游戏偏好标签上的哈达玛积为:
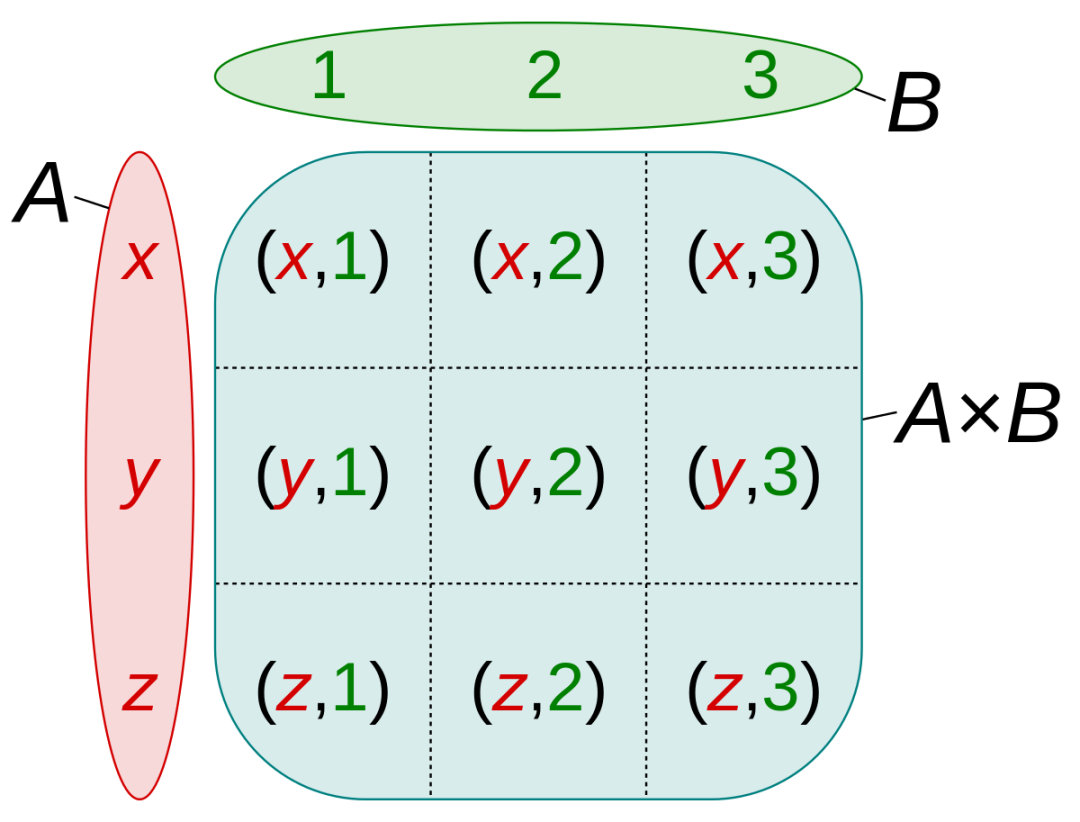
C) 笛卡尔积 (Cartesian Product)
笛卡尔积是用户各维特征分别与物品各维特征相乘,得到维度为的新特征。笛卡尔积是最常用的特征交叉方法,常用来挖掘特征间的关系(如牛奶和尿不湿的共现关系就可以用笛卡尔积来挖掘)
假设集合A={x, y, z}
,集合B={1, 2, 3}
,则两个集合的笛卡尔积为{(x, 1), (x, 2), (x, 3), (y, 1), (y, 2), (y, 3), (z, 1), (z, 2), (z, 3)}
,如下图所示:
通过笛卡尔积构造交叉特征后,模型就能通过样本学习到特征间的共现关系,从而提升模型的效果。对于连续特征,可以先对特征进行离散化(如分桶),然后再构造笛卡尔积。
笛卡尔积由于能充分对特征进行交叉,在推荐中表现比內积和哈达玛积要好。但它同时也面临着维度爆炸的风险,随意采用笛卡尔积很容易导致模型过拟合。建议基于业务或者数据分析结论为指导来构造笛卡尔积
2、隐式交叉
相较于显示交叉,隐式交叉省去了手动设计交叉的工作,直接通过模型来学习交叉。这样做的好处在于可以解决显示交叉需要依赖人工经验、特征交叉计算量大、维度爆炸等问题。主要有基于FM和MLP两大类隐式交叉方法。
FM交叉:通过的交叉项来实现指定阶数的特征交叉能力 MLP交叉:通过MLP实现高阶特征交叉能力
注:FM从形式上来说应该算显示交叉,但由于其具体交叉向量是在模型训练过程中不断优化的,本文暂且把它归属到隐式特征里面。
A) FM交叉
下面我们主要从FM和DeepFM这两个经典算法中来看FM交叉是如何实现的。
I) FM
FM算法的核心是在线性模型基础上增加了二阶因子分解项(还可以增加三阶及以上的因子分解项,但权衡效率和性能,采用二阶即可),用于表示特征间的交叉:
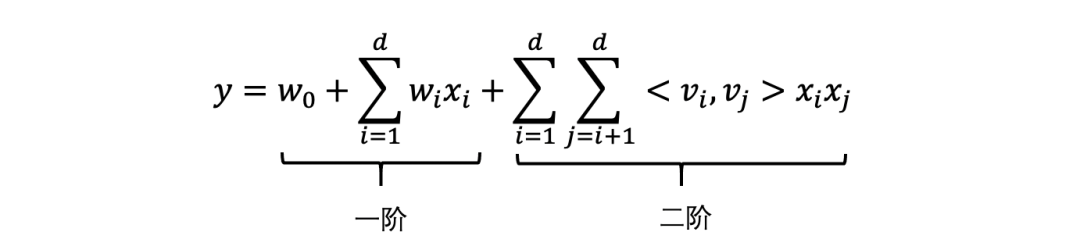
对每一维原始特征(),FM会学习一个隐向量(,为预设的隐向量维数),模型穷举所有特征对,来自动识别出有效的交叉特征。交叉特征的有效性是通过它们的隐向量的內积来计算的:
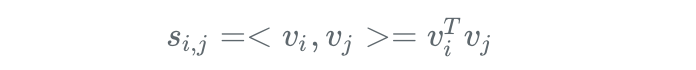
FM能同时兼顾特征交叉和特征维度维度,确保模型的性能和效果。首先通过对两两交叉,引入交叉特征,提高模型性能;其次通过隐向量,完成对交叉特征的参数估计,避免维度爆炸。
II) DeepFM
DeepFM模型是一个可以从原始特征中抽取到各种复杂的交叉特征的端到端模型。优势在于无需人工交叉特征,且能实现高阶特征交叉。DeepFM核心包含两个部分:FM和DNN。FM用于刻画低阶交叉特征,DNN用于刻画高阶交叉特征。
模型结构如下:

在DeepFM中FM和DNN共享Embedding层,然后FM负责低阶特征交叉(主要是一阶和二阶),而DNN负责高阶特征交叉,最后将低阶和高阶部分进行联合训练(Joint training)得到模型输出。
低阶交叉可以增强模型的记忆性,方便模型从历史数据中挖掘User、Item与特征之间的直接关系;而高阶特征可以增强模型的泛华性,使模型能挖掘User、Item与特征之间的间接关系,提升推荐的新颖性。
FM部分:负责构建1阶和2阶特征
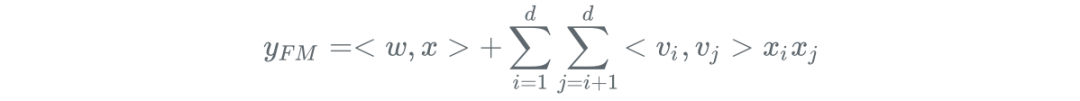
DNN部分:通过多层神经网络实现高阶特征交叉
其中,表示DNN部分的神经网络层数。
输出:
从FM到DeepFM最大的突破是将低阶特征交叉和高阶特征交叉组合起来,分别由浅层模型和深层模型来刻画,克服了对人工交叉的依赖,实现端到端的特征交叉,极大提升了模型对交叉特征的挖掘能力。
B) MLP交叉
下面主要从Deep Crossing、Wide&Deep和DCN三个算法来MLP是如何实现高阶特征交叉的。
I) Deep Crossing
与FM交叉不同,Deep Crossing采用多层网络来实现特征自动交叉,其网络结构如下:

需要说明的是,对于不同的特征(如Embedding
和Feature
特征),Deep Crossing在Stacking Layer
中将他们拼接(Concatenate)起来,得到包含全部特征的特征向量。
此外,与传统神经网络不同,Deep Crossing采用残差网络来实现MLP(这也是残差网络首次应用于推荐系统中):
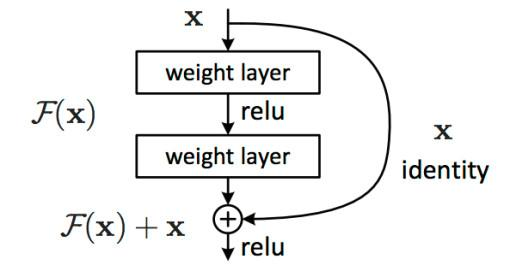
通过多层残差网络对特征各维度进行充分交叉,模型能够学到更多的交叉信息,使其在表达能力上较传统模型有较大提升。
虽然,目前看来Deep Crossing平平无奇(既没有序列模型、Attention机制,也没有引入特殊的模型结构),只是采用了非常常规的Embedding + MLP
的经典结构。但从推荐模型发展史来看,Deep Crossing是具有革命意义的:模型中没有任何人工交叉特征,全部通过多层神经网络实现,这也是Deep Crossing(深度交叉)名称的由来
。(那有人会说DeepFM不也是可以么?问题是在它之前可还没有DeepFM哦!)
II) Wide&Deep
Wide&Deep是推荐领域的又一神作,基本上后续大多数推荐模型都能看到它的思想:低阶交叉学习记忆能力
,高阶交叉学习泛化能力
,将二者结合起来模型就同时具备了记忆
和泛化
能力。
模型结构如下:
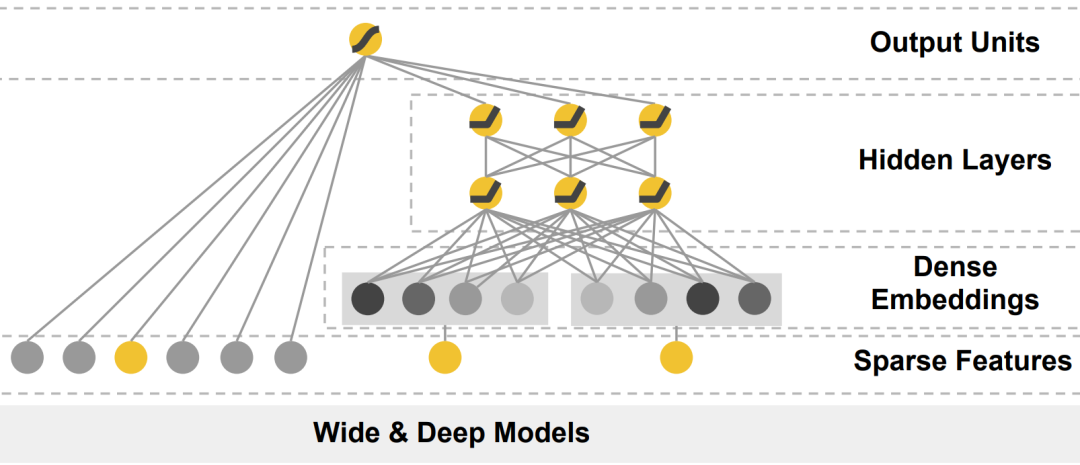
低阶交叉:通过人工手动构造交叉特征,然后由线性模型来构成 Wide
部分,增强模型的记忆能力高阶交叉:特征经过Embedding层之后,多层全连接神经网络来构成模型的 Deep
部分,增强模型的泛化能力
最后,模型采用joint training
模式来联合Wide
和Deep
部分特征。
哪些特征采用Wide?哪些特征采用Deep?需要有对业务和目标具有较强的理解和分析。例如:Wide部分可以对User最近消费的Item和要曝光的Item构造手动交叉特征进行学习;Deep部分可以对User和Item的属性的Embedding特征进行学习。
III) DCN(Deep&Cross Network)
DCN核心思想是使用Cross网络来代替Wide&Deep中的Wide部分,Deep部分沿用原来的结构,DCN可以任意交叉特征。Cross的目的是以一种显示、可控且高效的方式,自动构造有限高阶交叉特征。
模型结构如下:
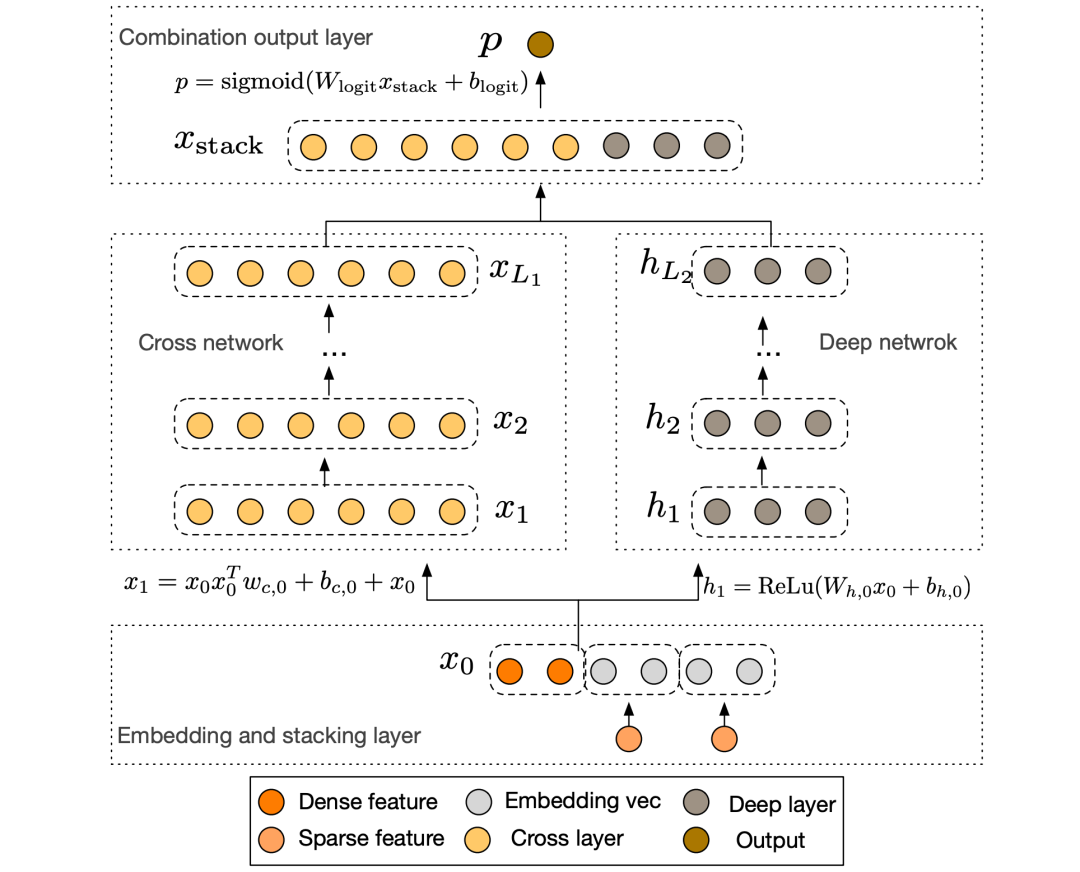
Cross层的目标是增加特征之间的交叉粒度,使用多个Cross层对输入向量进行交叉:
Cross层的实现如下图所示:

从图中可以看到,每层的特征交叉是通过 来实现,并通过 来学习各交叉特征的权重。通过叠加多个Cross层来实现特征的多阶交叉。此外,Cross层对参数相对比较克制,每层只增加一个 参数,且每层都保留了输入层特征 ,这使得每层的输入和输出之间的变化不会特别明显。与Wide&Deep一样,Deep&Cross的Deep部分比Cross部分的高阶交叉能力更强,是模型具备更好的非线性能力。
四、最后
在推荐系统中对模型优化基本都是围绕特征交叉进行的,要么手动显示的构造各种交叉特征,让模型根据历史数据学习交叉特征的有效性;要么是采用FM或MLP等方式实现隐式交叉,让模型从历史数据中自动学到有效的交叉特征。
从总体来看,当前主流的推荐模型大多是同时包含了手动交叉+FM交叉+MLP交叉
,始终是围绕对业务的分析和理解来选择特征和模型。
当前主流的推荐算法基本都是通过对Wide&Deep进行魔改优化的,总体都逃不过交叉
。感兴趣的同学可以参考下图进一步阅读:
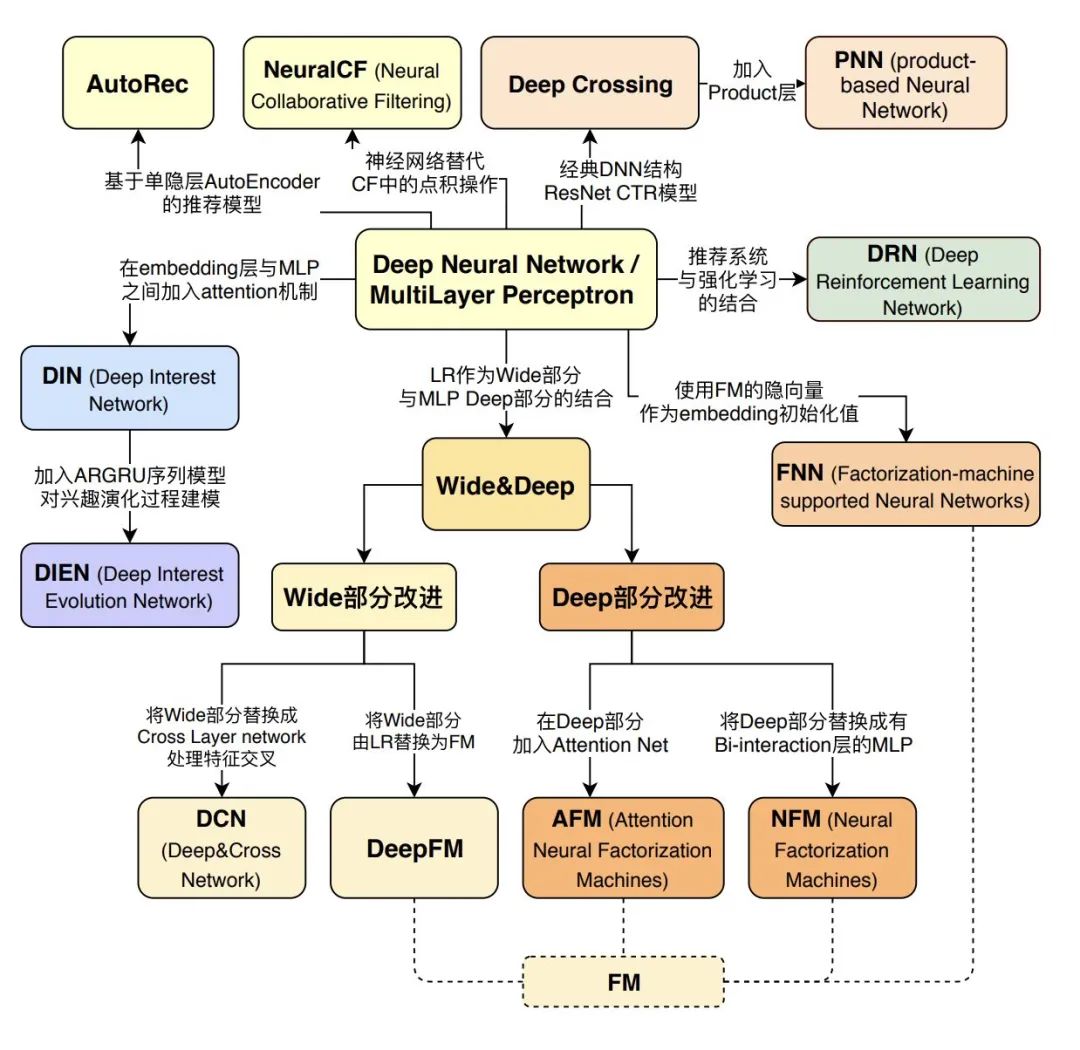
图片来源:王喆《深度学习推荐系统》
参考文献
[1] Drew Wilimitis. The Kernel Trick in Support Vector Classification
[2] Wikipedia. Polynomial kernel
[3] Wikipedia. Radial basis function kernel
[4] playground.tensorflow.org
[5] S. Rendle. Factorization machines. IEEE International Conference on Data Mining. 2010.
[6] H. Guo, et al. DeepFM: a factorization-machine based neural network for CTR prediction. arXiv preprint arXiv:1703.04247 (2017).
[7] Y. Shan, et al. Deep crossing: Web-scale modeling without manually crafted combinatorial features. Proceedings of ACM SIGKDD international conference on knowledge discovery and data mining. 2016.
[8] H. Cheng, et al. Wide & deep learning for recommender systems. Proceedings of the 1st workshop on deep learning for recommender systems. 2016.
[9] R. Wang, et al. Deep & cross network for ad click predictions. Proceedings of the ADKDD'17. 2017. 1-7.
[10] 王喆《深度学习推荐系统》. 电子工业出版社. 2020
