





学习 探索 分享数据库知识 共建数据库技术交流圈
本篇我们开启第七章执行器解析中“7.1 执行器整体架构及代码概览”、“7.2 执行流程”及“7.3 执行算子”的相关精彩内容介绍。完整版内容请查看CSDN·Gauss松鼠会专栏博客,以下内容为章节试读:
执行器在数据库整个体系结构中起到承上启下的作用,对上承接优化器产生的最优执行计划,并按照执行计划进行流水线式的执行,对底层的存储引擎中的数据进行操作。openGauss数据库将执行的过程抽象成了不同类型的算子,同时结合编译执行、向量化执行、并行执行等方式,组成了全面、高效的执行引擎。本章着重介绍执行器的整体架构、执行模型、各类算子、表达式,以及编译执行和向量化引擎等全新的执行引擎。
7.1 执行器整体架构及代码概览
本节整体介绍执行器的架构和代码。
7.1.1 执行器整体结构
在SQL引擎将用户的查询解析优化成可执行的计划之后,数据库进入查询执行阶段。执行器基于执行计划对相关数据进行提取、运算、更新、删除等操作,以达到用户查询想要实现的目的。
openGauss在行计算引擎的基础上,增加了编译执行引擎和向量化执行引擎,执行器模块架构如图7-1所示。openGauss的执行器采用的是火山模型(volcano model),这是一种经典的流式迭代模型(pipeline iterator model),目前主流的关系型数据库大多采用这种执行模型。
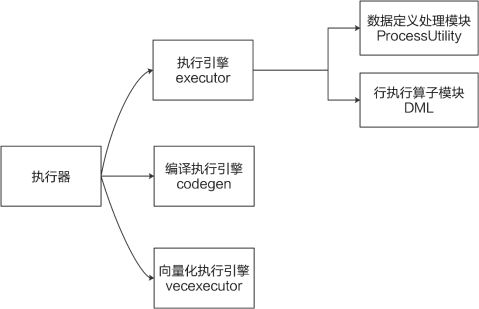
图7-1 执行器模块架构
执行器包括四个主要的子模块:Portal、ProcessUtility、executor和特定功能子模块。首先在Portal模块中根据优化器的解析结果,选择相应的处理策略和处理模块(ProcessUtility和executor)。其中executor主要处理用户的增删改查等DML(Data Manipulation Language,数据操作语言)操作。然后ProcessUtility处理增删改查之外的其他各种情况,例如各类DDL(data definition language,数据定义语言)语句、游标操作、事务相关操作、表空间操作等。
7.1.2 火山模型
执行器(executor)的输入是优化器产生的计划树(plan tree),计划树经过执行器转换成执行状态树。执行状态树的每一个节点对应一个独立算子,每个算子都完成一项单一功能,所有算子组合起来,实现了用户的查询目标。在火山模型中,多个算子组成了一个由一个根节点、多个叶子节点和多个中间节点组成的查询树。
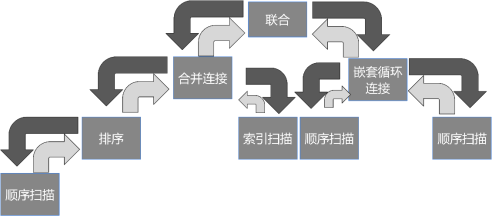
驱动流是指上层算子驱动下层算子执行的过程,这是一个从上至下、由根节点到叶节点的过程,如图7-2中的向下的箭头所示。从代码层面来看,即上层算子会根据需要调用下层算子的函数接口,去获取下层算子的输入。驱动流是从跟节点逐层传递到叶子节点。
7.1.3 代码概览
执行器在项目中的源代码路径为:src/gausskernel/runtime。下面是执行器的源码目录。
1) 执行器源码目录
表7-1 执行器源码目录
模块 | 功能 |
Makefile | 编译脚本 |
codegen | 计划编译,加速热点代码执行 |
executor | 执行器核心模块,包括表达式计算、数据定义处理以及行级执行算子 |
vecexecutor | 向量化执行引擎 |
2) 执行器源码文件
执行器源码目录为:src/gausskernel/runtime/模块名。文件如表7-2所示。
表7-2 执行器源码文件
……(本节内容未完)
为提升您的阅读体验,完整版内容已运用专业格式发布到CSDN·Gauss松鼠会专栏,请扫码下方二维码,“关注”后进行内容阅读或点击文末“阅读原文”进入博客进行学习~









