1. 概览
前面都是假设单个线程对索引操作,为了充分利用现代处理器多个核心以及弥补I/O延迟,讨论多线程对索引操作的相关话题. 包括Latch,Hash Table Latching,B+ Tree Latching,乐观并发,处理叶节点死锁问题,父节点延迟更新.

2. Latch
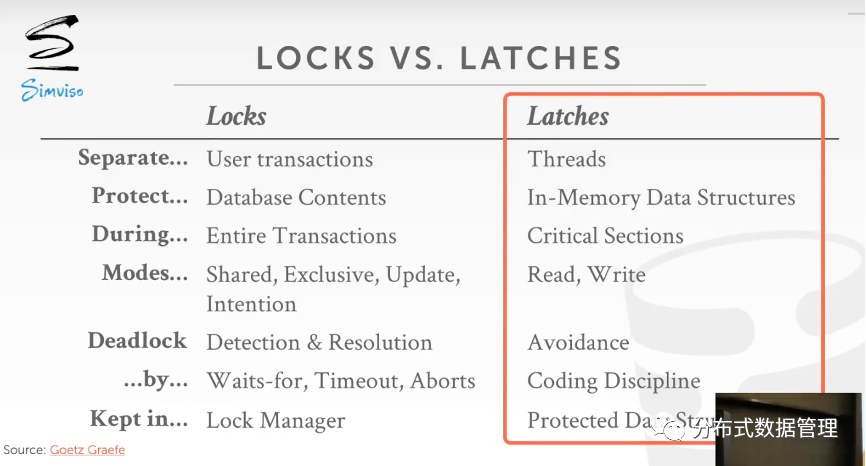
Lock针对数据库事务的一种逻辑上的锁,表示整个事务执行阶段对数据的占用,需要支持数据回滚. Latch指线程级别的锁,指一个线程执行阶段对数据的占用,不需要支持数据回滚. 具体区别如下:

事务并发中的死锁一般可以有特殊的处理机制,而多线程下latch由于线程之间相互不了解操作内容,尽可能代码层面避免死锁的发生.
Latch有两种锁:读锁和写锁

一个数据最多能被加上一种类型的latch锁,多个线程可以同时对数据加上读锁. 写锁只能加在没有上任何锁的数据上,一个数据只能被加一个写锁.
实现Latch的三种方式:
通过操作系统提供的Mutex

通过CPU提供的API,对某段内存实现独占

基于Latch原语实现的 Reader-Writer Latch,处理多线程的读写.

3. Hash Table Latching
哈希表latch可以有两种方法,一种是对整个Page上锁,一种是对Slot上锁. 对Page上锁处理简单但是并发度有限,对Slot上锁管理复杂但可以获得更高的并发度.

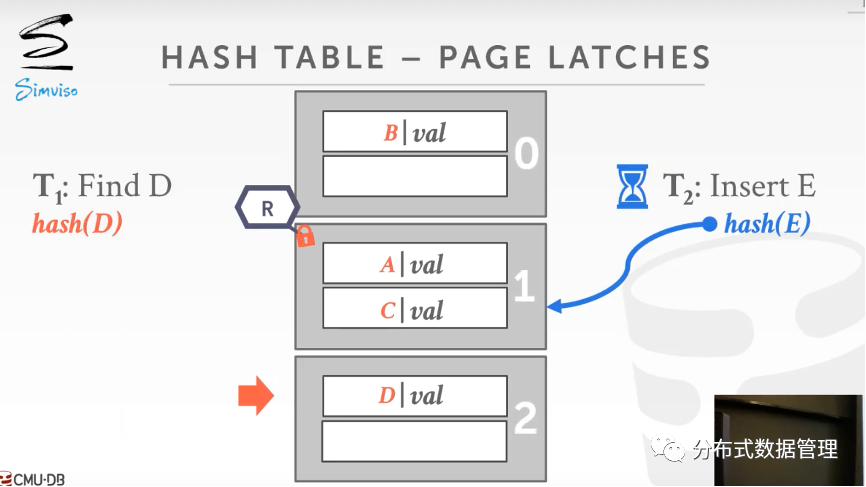
如下图 Page Latch 例子,线程T1和T2自上而下扫描,线程T1想要从哈希表中搜索D,它获取了Page 1 的读锁,这时候线程T2想要向哈希表中插入E,它需要先查看 Page 1 中的值,但是此时这个块已经被线程1上了读锁,因此线程T2只能等待. 当线程1扫描完Page 1后释放Page 1的读锁,线程T2可以开始访问(注意这和后面B+ 树的情况有所不同)
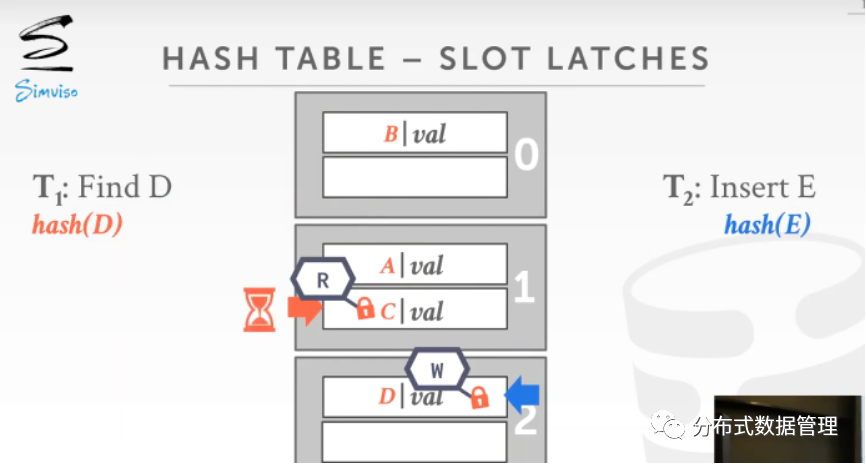
下图是采用 Slot Latch 的例子,线程T1和T2还是自上而下扫描,首先线程T1获取Page 1的第二个Slot的读锁,线程T2获得Page 2的第一个Slot写锁. 若T1释放读锁而T2没有释放写锁,T1只能等待T2释放写锁再继续扫描下一个Slot.
4. B+ Tree Latching
多线程操作B+树主要处理两种情况:
避免多个线程同时修改一个节点的值
一个线程遍历树,另一个线程写操作导致树中的某个节点合并/分裂. 合并/分裂导致原来父节点指向孩子的节点内容发生变化,或者指向一个无效地址,导致遍历数据的线程读数据发生错误.
Crabbing/Coupling技术:
B+树通过Crabbing/Coupling技术处理上述问题. 基本的想法是每个线程首先获取父节点的锁,随后获取子节点的锁,如果确保释放父节点锁是“安全的”,那么才释放父节点的锁,Andy形容这像螃蟹走路(形象!不过后面会发现有时候需要腿很长…).

具体策略如下:
对于Find操作,先获取父节点的读锁,获取子节点的读锁后立即释放父节点读锁.
对于Insert/Delete操作,先获取父节点的写锁,随后获取子节点的写锁,判断如果写操作不会引起子节点的分裂/合并,再释放父节点的写锁.(这样就保证了后面读数据的线程不会出错)

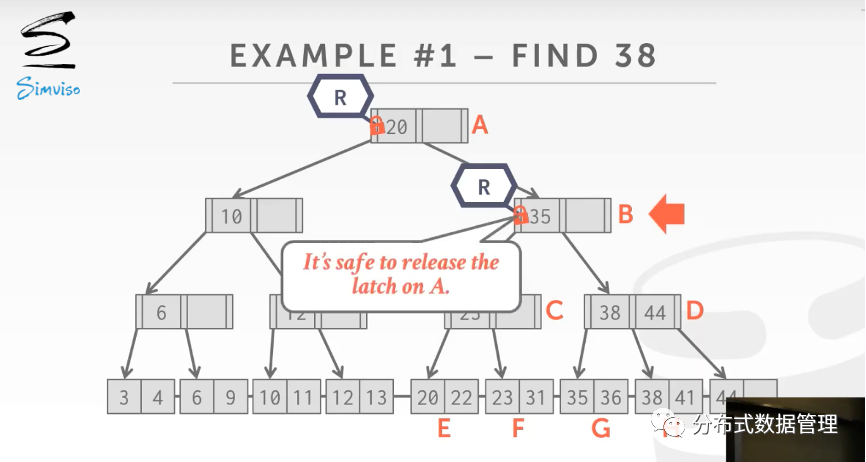
下图是从B+树中查找Key为38的数据,当线程获取了子节点的读锁后直接释放父节点上的读锁.
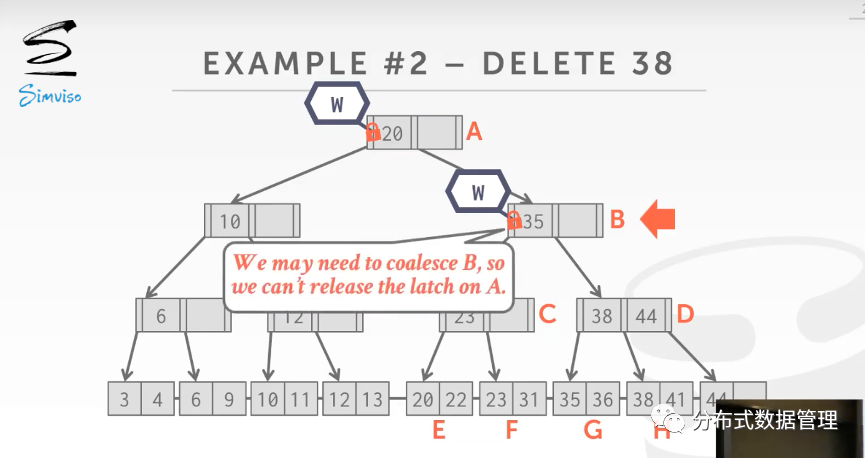
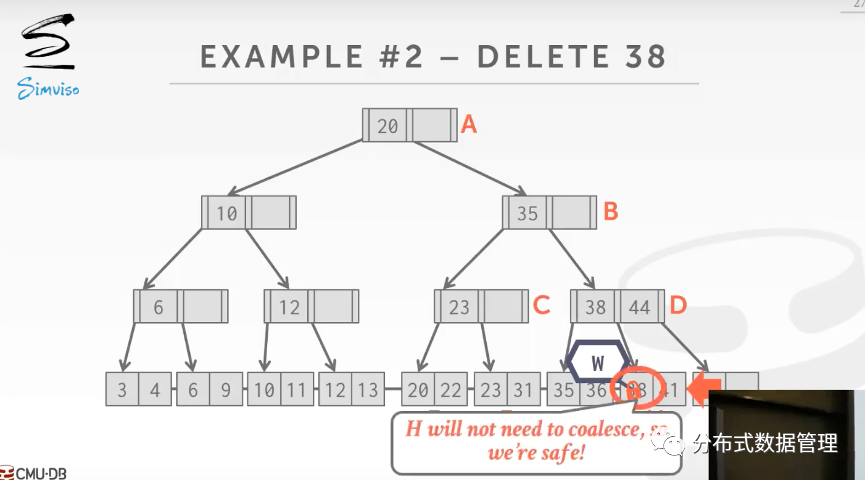
下图是从B+树中删除Key为38的数据,由于节点的删除可能导致节点的合并,继而影响父节点发生. 由于线程获取节点B的写锁之后不能确保删除操作不会导致节点B发生变化,因此B上的写锁暂不释放.
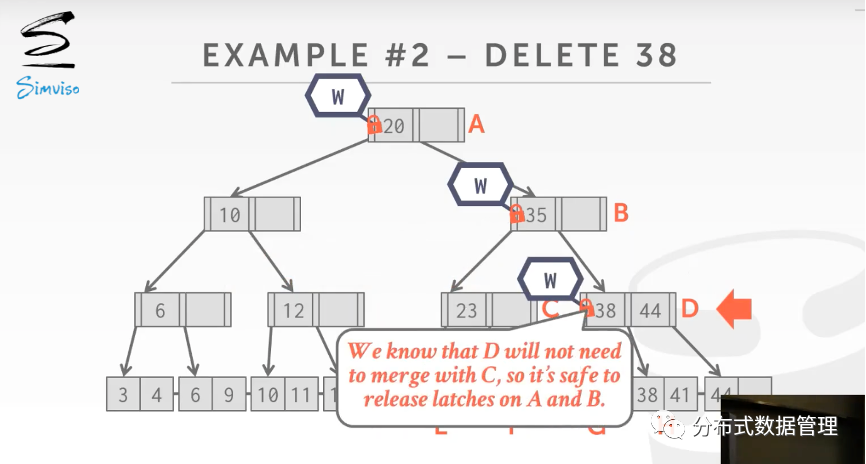
当线程获得节点D的写锁,读取D的数据后可以确认删除38不会导致树的合并(假设此时树中节点允许的最小Key个数是1),这时候释放A和B上的写锁.
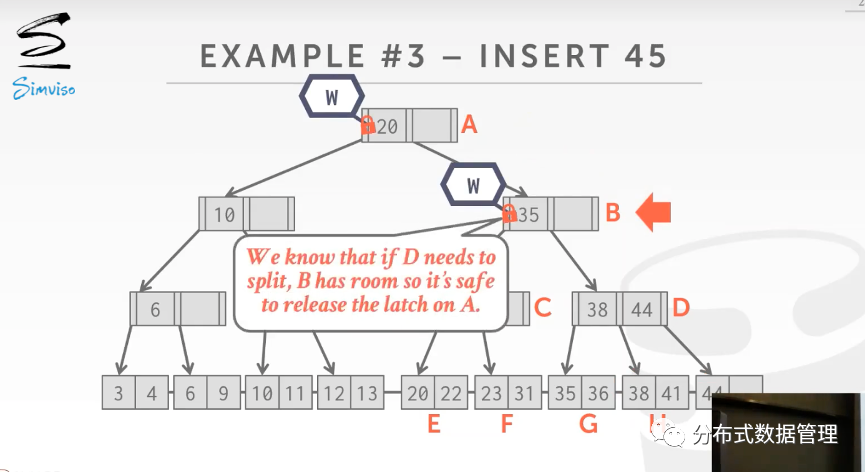
插入操作也是类似的处理方法,线程只有能够确保新节点的插入不会导致节点的分裂才会释放父节点上的写锁.下面是向B+树种插入Key等于45的例子. 当线程拿到节点B的写锁时发现B中有预留空间,因此插入新数据不会导致节点B的分裂,线程释放A上的写锁.
当线程到达右下角叶节点时发现叶节点中也有预留空间,随后也可以释放B和D上的写锁. 数据库倾向于先释放上层的锁,因为上层的锁关联的节点数目更多,优先释放这里的写锁可以允许更多的线程参与并发.

下图是处理叶节点需要分裂的例子,线程获取F的写锁后发现需要分裂,暂时不释放C上的写锁.
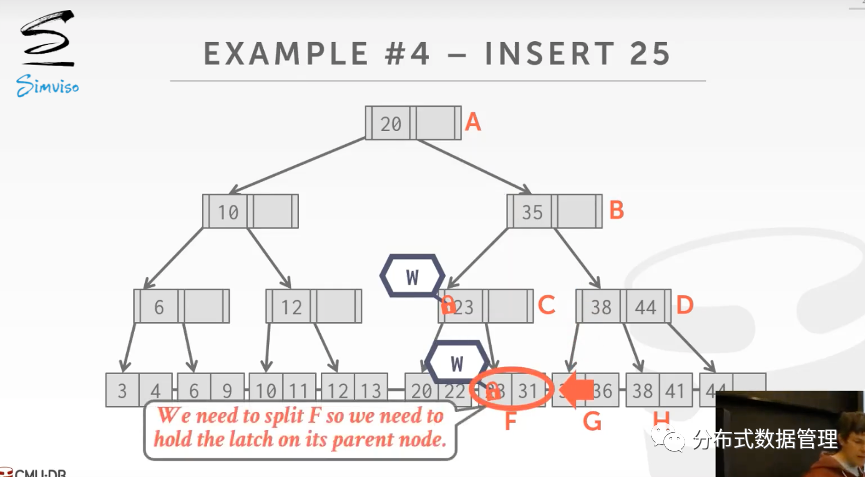
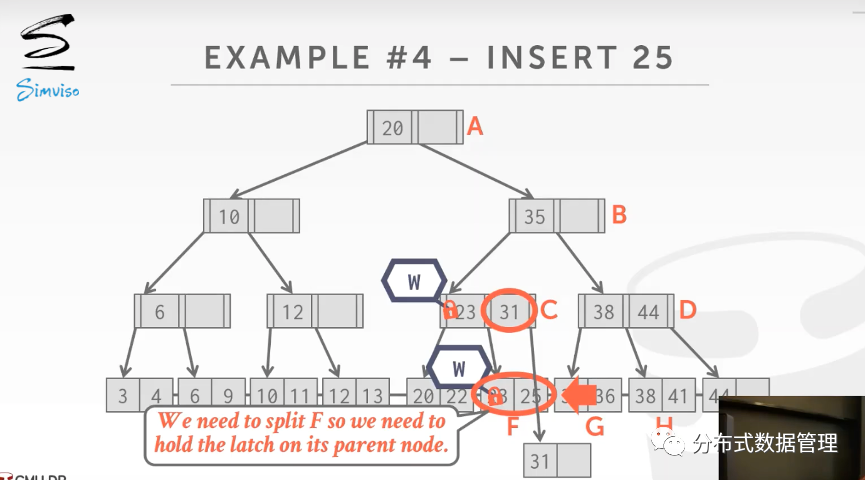
将F节点分裂完成后继续修改父节点.
5. 乐观并发
前面多线程下的写线程从根节点获取的都是写锁,当确认子节点安全才会释放父节点的写锁. 当节点被上了写锁之后,其他线程不能做任何事情,这一点成为了并发的性能瓶颈. 在真实的应用场景中,B+树的一个节点一般较大,预留空间也会比较多,一次删除或者插入操作引起节点的合并与分裂的概率往往较低.
写线程若假设此次写操作不会引起节点分裂/合并,对节点优先使用读锁处理,只在确定需要修改的节点上施加写锁,这样其他线程依然可以对路径上的节点施加读锁,增加了系统并发度. 若在此过程中线程确认节点数据的更新需要节点的分裂或者合并,再使用原先的方法重新从根节点处获取路径上的所有写锁. 这是一种乐观并发的想法,在真实的低竞争率的系统中被运用的非常广泛.

具体方法如下:

下图是此时删除操作的例子,在ABD节点上都是先拿读锁,到叶节点上时发现的确不需要合并节点,直接修改叶节点就可以.
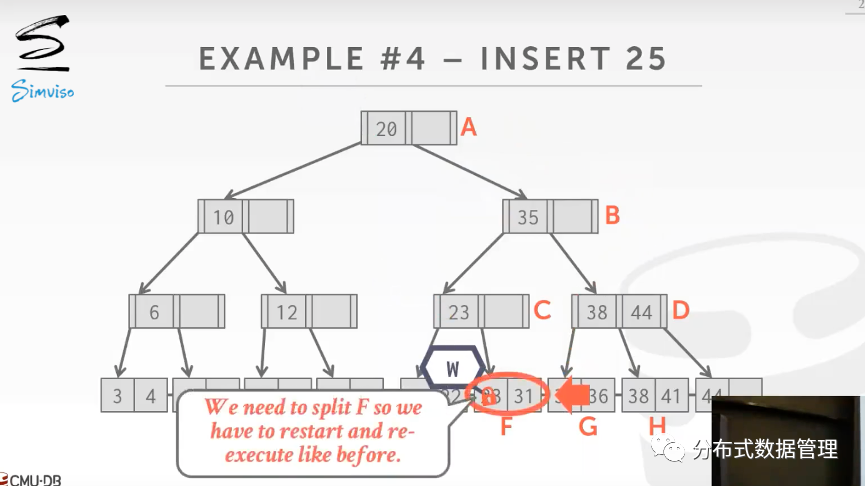
下图是插入操作的例子,在ABC节点上同样都是先拿读锁,到叶节点上时才发现叶节点需要分裂,这时候按照最开始悲观方法处理,从根节点开始获取每个节点的写锁.
6. 处理叶节点死锁
前面多线程对索引的操作都是单向的,当前一个线程释放写锁后一个线程就可以对其进行加锁,不存在出现出现死锁的情况. 但是B+树的叶子节点之间用双向指针相连(B+树的一个变种,想法来源于B Link 树),当两个线程从不同方向在叶节点组成的双向链表上操作时,容易发生死锁.
例如下图,线程1删除Key=4的数据,首先获得了节点c的写锁. 线程2搜索Key大于1的数据,首先获得了节点B的读锁. 此时线程2读完节点B的数据后无法获取节点c上的读锁,由于线程2并不知道线程1实际的操作内容,线程1此时可能想要获取B节点的写锁.
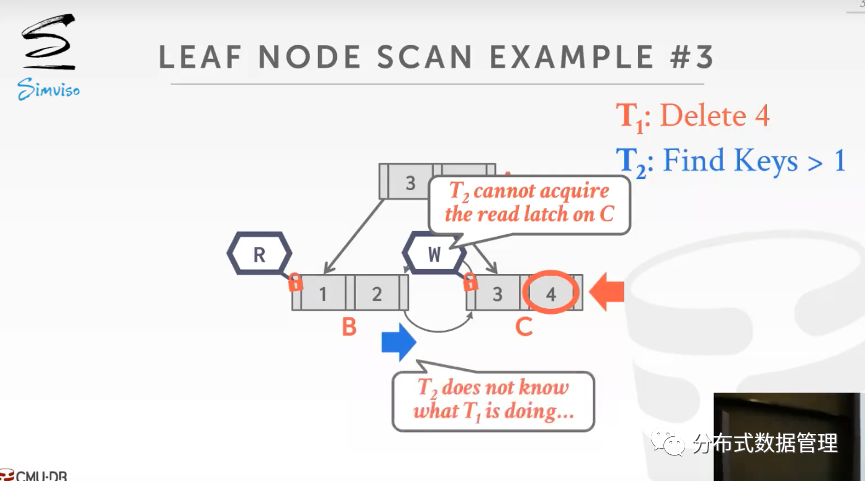
由于latch没有事务死锁检查机制,这时候选择在timeout之后将线程 2 kill掉.
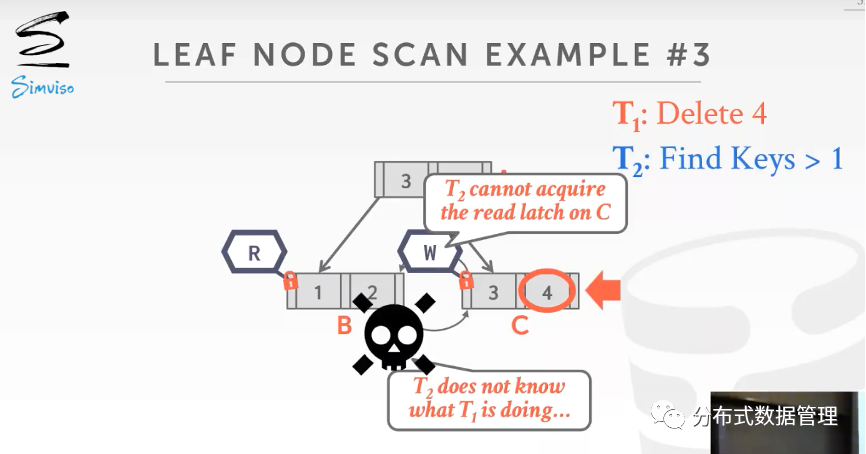
与事务不同,由于线程latch没有死锁检查方法(一个线程不知道另一个线程在做什么),只能尽可能在代码上避免死锁的发生.

7. 父节点延迟更新
根据前面的方法,若插入叶节点新数据需要分裂叶节点,线程不释放父节点的锁,这样其他访问该节点的线程必须等待. 为了提高多线程操作B+树的吞吐和延迟,还有一种常用的优化策略是推迟父节点更新操作. 叶节点插入数据后父节点不立即更新,而是等下一个获取到父节点的写锁的线程完成父节点更新操作.
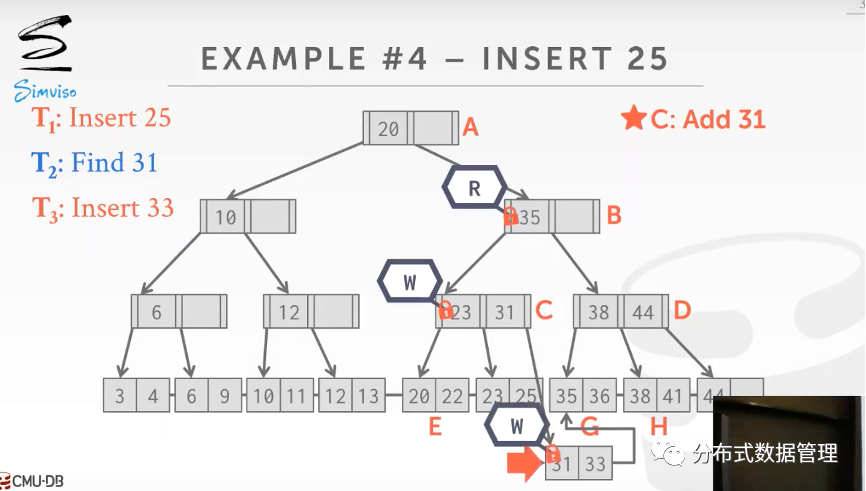
例如下图中的例子,线程1向B+树种插入Key=25的数据,更新完叶子节点后父节点留给下一个获取到写锁的线程去完成.
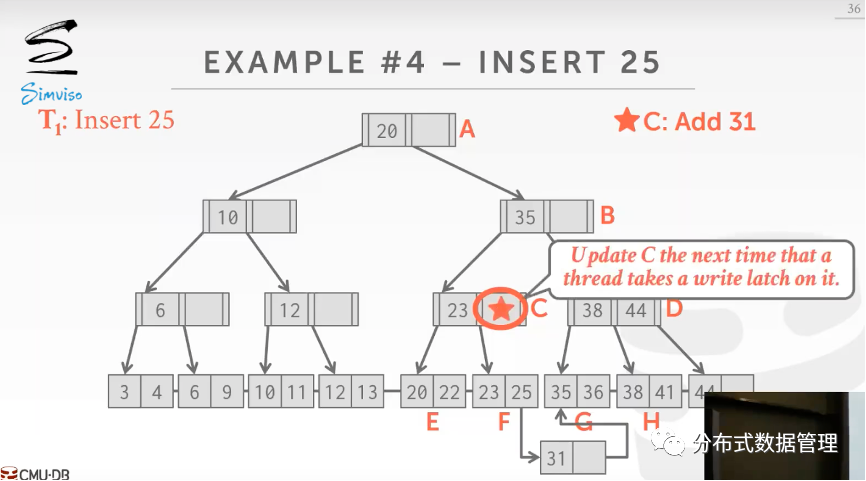
线程3获取了节点c的写锁后,发现c需要添加31,线程3顺手将其完成.