





08
table 瘦身
空洞:MySQL 执行 delete 命令其实只是把记录的位置,或者数据页标记为了可复用,但磁盘文件的大小是不会变的。通过 delete 命令是不能回收表空间的。这些可以复用,而没有被使用的空间,看起来就像是空洞。插入时候引发分裂同样会产生空洞。
重建表思路:
新建一个跟 A 表结构相同的表 B;按照主键 ID 将 A 数据一行行读取同步到表 B;用表 B 替换表 A 实现效果上的瘦身。重建表指令:
alter table A engine=InnoDB,慎重用,牛逼的 DBA 都用下面的开源工具。推荐 Github:gh-ost
01
SQL Joins、统计、 随机查询
7种 join 具体如下:
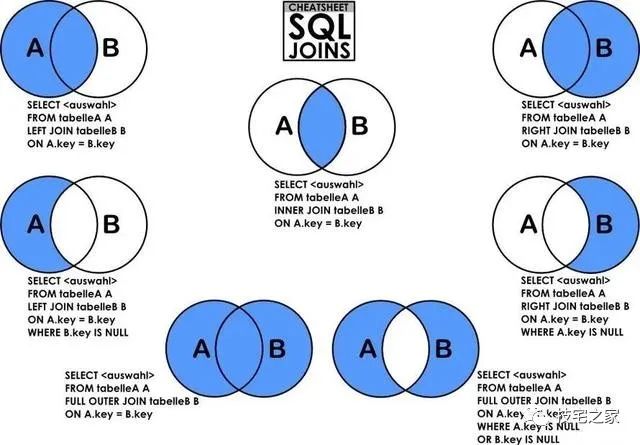
统计:
MyISAM 模式下把一个表的总行数存在了磁盘上,直接拿来用即可InnoDB 引擎由于 MVCC 的原因,需要把数据读出来然后累计求和性能来说,由好到坏:count(字段) < count(主键id) < count(1) ≈ count(*),尽量用 count(*)。随机查询:
mysql> select word from words order byrand() limit 3;
直接使用 order by rand(),explain 这个语句发现需要 Using temporary 和 Using filesort,查询的执行代价往往是比较大的。所以在设计的时要避开这种写法。
mysql> selectcount(*) into @C from t;set @Y1 = floor(@C * rand());set @Y2 = floor(@C * rand());set @Y3 = floor(@C * rand());select * fromtlimit @Y1,1; select * fromtlimit @Y2,1;select * fromtlimit @Y3,1;
这样可以避免临时表跟排序的产生,最终查询行数 = C + (Y1+1) + (Y2+1) + (Y3+1)
exist 和 in 对比:
in 查询时首先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选。子查询使用 exists,会先进行主查询,将查询到的每行数据循环带入子查询校验是否存在,过滤出整体的返回数据。两表大小相当,in 和 exists 差别不大。内表大,用 exists 效率较高;内表小,用 in 效率较高。查询用 not in 那么内外表都进行全表扫描,没有用到索引;而 not extsts 的子查询依然能用到表上的索引。not exists 都比 not in 要快。
10
MySQL 优化
SQL 优化主要分 4 个方向:SQL 语句跟索引、表结构、系统配置、硬件。
总优化思路就是最大化利用索引、尽可能避免全表扫描、减少无效数据的查询:
减少数据访问:设置合理的字段类型,启用压缩,通过索引访问等减少磁盘 IO。
返回更少的数据:只返回需要的字段和数据分页处理,减少磁盘 IO 及网络 IO。
减少交互次数:批量 DML 操作,函数存储等减少数据连接次数。
减少服务器 CPU 开销:尽量减少数据库排序操作以及全表查询,减少 CPU 内存占用 。
分表分区:使用表分区,可以增加并行操作,更大限度利用 CPU 资源。
SQL 语句优化大致举例:
1、合理建立覆盖索引:可以有效减少回表。2、union,or,in都能命中索引,建议使用 in 3、负向条件(!=、<>、not in、not exists、not like 等) 索引不会使用索引,建议用in。4、在列上进行运算或使用函数会使索引失效,从而进行全表扫描 5、小心隐式类型转换,原字符串用整型会触发 CAST 函数导致索引失效。原 int 用字符串则会走索引。6、不建议使用%前缀模糊查询。7、多表关联查询时,小表在前,大表在后。在 MySQL 中,执行 from 后的表关联查询是从左往右执行的(Oracle 相反),第一张表会涉及到全表扫描。8、调整 Where 字句中的连接顺序,MySQL 采用从左往右,自上而下的顺序解析 where 子句。根据这个原理,应将过滤数据多的条件往前放,最快速度缩小结果集。
SQL调优大致思路:
先用慢查询日志定位具体需要优化的 sql;使用 explain 执行计划查看索引使用情况 ;重点关注(一般情况下根据这 4 列就能找到索引问题):key(查看有没有使用索引)、key_len(查看索引使用是否充分)、type(查看索引类型)、Extra(查看附加信息:排序、临时表、where 条件为 false 等);根据上 1 步找出的索引问题优化 sql5、再回到第 2 步。
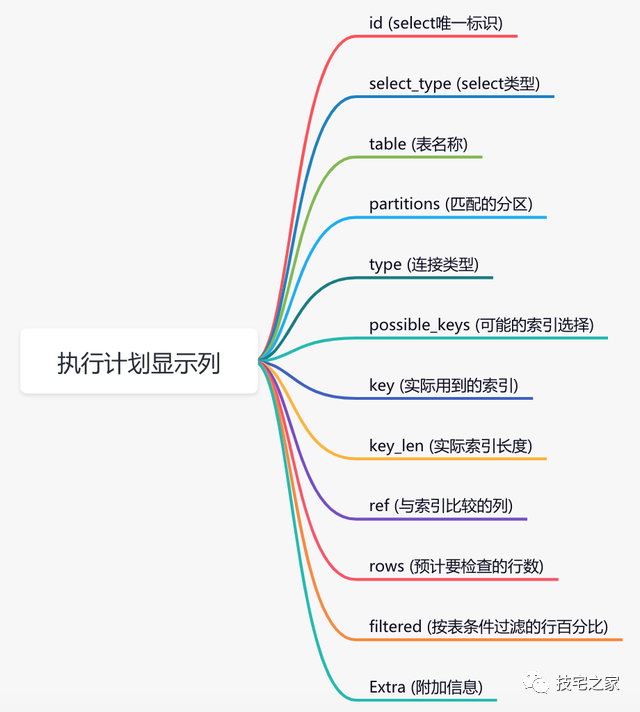
表结构优化:
尽量使用 TINYINT、SMALLINT、MEDIUM_INT 作为整数类型而非 INT,如果非负则加上 UNSIGNED 。VARCHAR 的长度只分配真正需要的空间 。尽量使用 TIMESTAMP 而非 DATETIME 。单表不要有太多字段,建议在 20 以内。避免使用 NULL 字段,很难查询优化且占用额外索引空间。字符串默认为''。读写分离:
只在主服务器上写,只在从服务器上读。对应到数据库集群一般都是一主一从、一主多从。业务服务器把需要写的操作都写到主数据库中,读的操作都去从库查询。主库会同步数据到从库保证数据的一致性。一般 读写分离 的实现方式有两种:代码封装跟数据库中间件。
分库分表:分库分表分为垂直和水平两个方式,一般是先垂直后水平。
垂直分库:将应用分为若干模块,比如订单模块、用户模块、商品模块、支付模块等等。其实就是微服务的理念。垂直分表:一般将不常用字段跟数据较大的字段做拆分。水平分表:根据场景选择什么字段作分表字段,比如淘宝日订单 1000 万,用 userId 作分表字段,数据查询支持到最近 6 个月的订单,超过 6 个月的做归档处理,那么 6 个月的数据量就是 18 亿,分 1024 张表,每个表存 200W 数据,hash(userId)%100 找到对应表格。ID生成器:分布式ID 需要跨库全局唯一方便查询存储-检索数据,确保唯一性跟数字递增性。目前主要流行的分库分表工具 就是 Mycat 和 sharding-sphere。
TiDB:开源分布式数据库,结合了传统的 RDBMS 和NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的目标是为 OLTP(Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案。TiDB 具备如下核心特点
支持 MySQL 协议(开发接入成本低)。100% 支持事务(数据一致性实现简单、可靠)。无限水平拓展(不必考虑分库分表),不停服务。TiDB 支持和 MySQL 的互备。遵循 jdbc 原则,学习成本低,强关系型,强一致性,不用担心主从配置,不用考虑分库分表,还可以无缝动态扩展。适合:
原业务的 MySQL 的业务遇到单机容量或者性能瓶颈时,可以考虑使用 TiDB 无缝替换 MySQL。大数据量下,MySQL 复杂查询很慢。大数据量下,数据增长很快,接近单机处理的极限,不想分库分表或者使用数据库中间件等对业务侵入性较大、对业务有约束的 Sharding 方案。大数据量下,有高并发实时写入、实时查询、实时统计分析的需求。有分布式事务、多数据中心的数据 100% 强一致性、auto-failover 的高可用的需求。不适合:
单机 MySQL 能满足的场景也用不到 TiDB。数据条数少于 5000w 的场景下通常用不到 TiDB,TiDB 是为大规模的数据场景设计的。如果你的应用数据量小(所有数据千万级别行以下),且没有高可用、强一致性或者多数据中心复制等要求,那么就不适合使用 TiDB。

按二维码关注我们
