





Pytest
在使用pytest做一些自动化测试的时候,我们经常需要一些测试报告来做测试统计,那么使用pytest如何生成测试报告呢?pytest给我们提供了很多的第三方的测试报告插件,常见的有:
pytest-html
allure-pytest
pytest-tmreport
那么本篇文章我们就介绍第一个最简单的测试报告(当然也是最丑的!)pytest-html。
01
pytest-html的安装
非常简单,我们直接使用pip安装即可:
pip install pytest-html
02
pytest-html生成测试报告
命令也是非常的简单:
pytest --html 报告名称(后缀为.html)
比如我们现在的项目结构是这个样子:
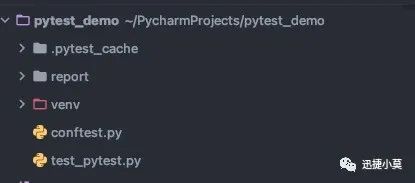
我们有一个report文件夹专门来存放测试报告,那么我们在命令行输入:
pytest --html report/report.html
执行完毕后,可以看到report下面已经生成了测试报告,如下:
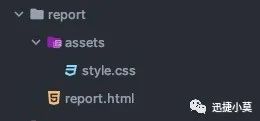
可以看到,生成的文件不止是一个report.html文件,并且还有一个css样式文件同步生成了,这个主要是报告的一些样式会放在这里。那我们打开这个报告看下
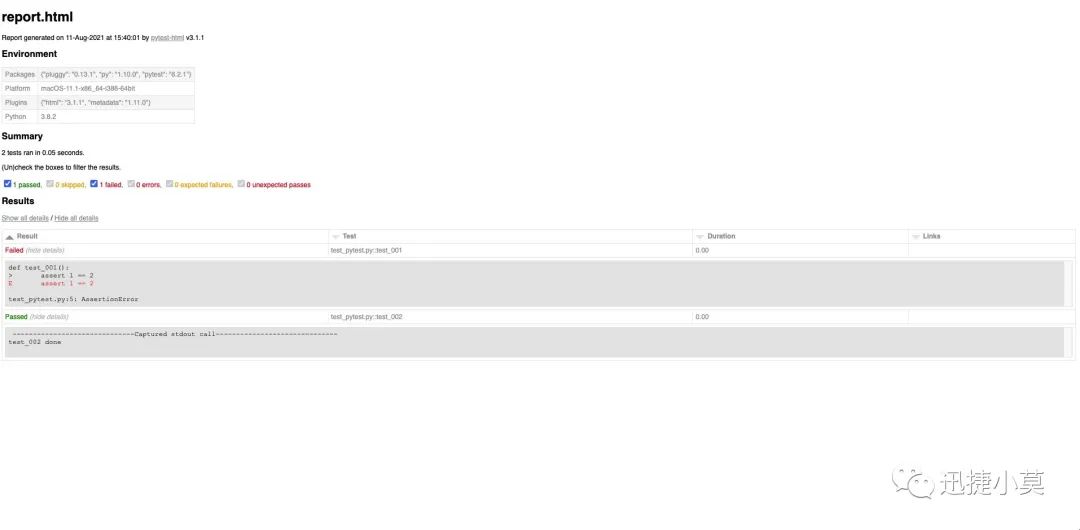
emm,虽然有点一言难尽,但是确实该有的都有了,可以看到最上面有环境的信息,有整体的测试汇总结果,详细的测试记录列表,日志等等,同时还有一些筛选项。但是,还是丑,哈哈再多的就不吐槽了,总结一下,还是能用的。
这里小提莫想提醒一下各位的,如果你想把这份测试报告发送邮件的话,一定要把这个样式文件和html一起发送出去,不然可能会变成下面这样(缺少样式文件):

被领导看到的话,就十分的尴尬了。
03
解决中文乱码问题
在使用的过程中,小提莫也发现了中文乱码的BUG, 比如我们的测试用例名称带有中文的时候(写UI自动化的时候经常会有):
import pytest # 导入pytestdef test_测试用例1():assert 1 == 2def test_测试用例2():print("test_002 done")if __name__ == '__main__': # 定义主函数pytest.main()
然后还是用一下我们生成报告的命令,可以看到现在生成的测试报告是这样:
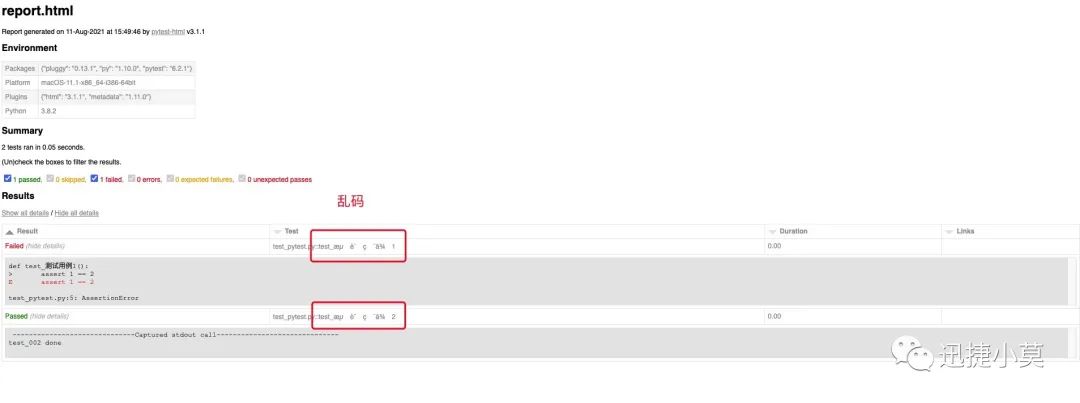
这个经小提莫查看源码后发现 ,pytest-html中报告对乱码的处理存在一点问题,在源码的这里可以发现问题:
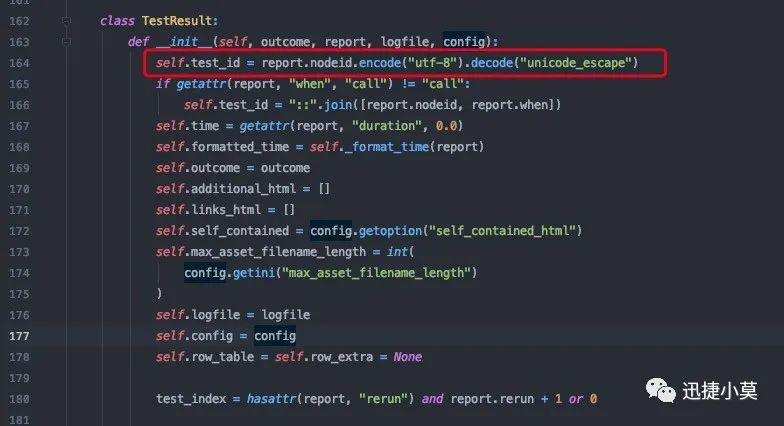
我们其实不需要进行转换,把他修改一下:
# self.test_id = report.nodeid.encode("utf-8").decode("unicode_escape") # 修改前self.test_id = report.nodeid # 修改后
然后我们再试一下,现在好了:
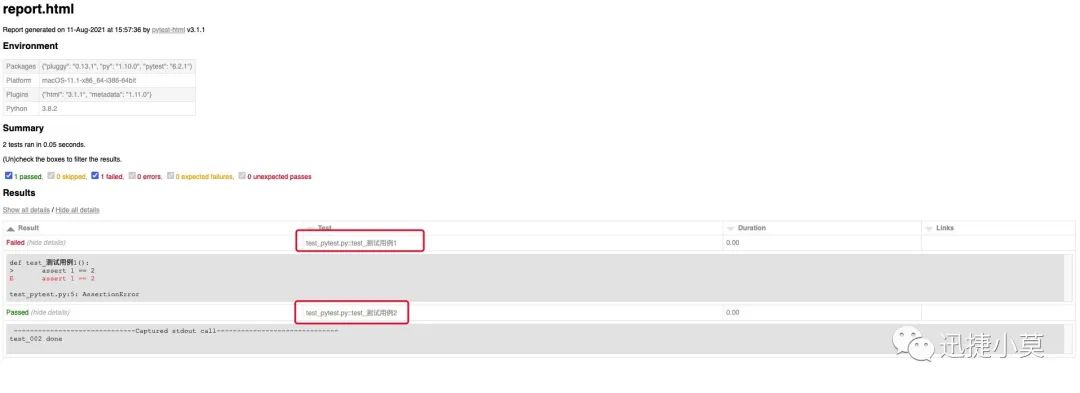
问题是解决了,但是可能有的小伙伴想问,哎呀,改源码多不优雅,多不好呀,有没有别的好办法呢?
在这里小提莫再给提供一种不需要改源码的方法,利用conftest.py做处理,我们在conftest.py里加上一段代码即可:
import pytestdef pytest_collection_modifyitems(items):"""修改用例名称中文乱码:param items::return:"""for item in items:item.name = item.name.encode('unicode_escape').decode('utf-8')item._nodeid = item.nodeid.encode('unicode_escape').decode('utf-8')
小提莫也是推荐使用这一种方法~比较优雅哦。
那么今天内容不多,快速掌握,后面的内容我们再看看其他好看的测试报告。
see you later.

扫码关注!
