




直方图(Histogram)即对表中一列或几列数据的数值分布的统计信息,以相对索引开销更小的方式获取某些字段的数据分布情况,使得优化器能够选择更加合理的执行计划。MySQL 8.0 开始提供对直方图的支持,从8.0.19开始对InnoDB表使用更加高效的方式采用数据,避免全表扫描。
MySQL提供等高直方图和等宽直方图两种。MySQL会自动分配使用哪种类型的直方图,无需干预。
-
等宽/单例直方图(singleton)一桶代表列中的一个单一值。 当列中不同值的数量小于或等于生成直方图的 ANALYZE TABLE 语句中指定的桶数时,将创建此直方图类型。
-
等高直方图(equi-height)一个桶代表一系列值。 当列中不同值的数量大于生成直方图的 ANALYZE TABLE 语句中指定的桶数时,将创建此直方图类型。
-
桶(bucket)将数据分组后存储数值分布统计信息。在等宽/单例直方图中桶包含列值以及该值累积频率的值这两部分,累积频率是指该列中小于等于该值的数据比例。 在等高直方图中桶存储四个值,分别是上、下限值,上限值的累积频率以及上下限间数值的distinct values。
1、创建和删除直方图的命令如下
ANALYZE [NO_WRITE_TO_BINLOG | LOCAL] TABLE tbl_name UPDATE HISTOGRAM ON col_name [, col_name] ... [WITH N BUCKETS] ANALYZE [NO_WRITE_TO_BINLOG | LOCAL] TABLE tbl_name DROP HISTOGRAM ON col_name [, col_name] ... #创建示例 mysql> analyze table t_histogram update histogram on name with 2 buckets; +------------------+-----------+----------+-------------------------------------------------+ | Table | Op | Msg_type | Msg_text | +------------------+-----------+----------+-------------------------------------------------+ | test.t_histogram | histogram | status | Histogram statistics created for column 'name'. | +------------------+-----------+----------+-------------------------------------------------+ 1 row in set (0.03 sec) mysql> analyze table t_histogram update histogram on name,age with 3 buckets; +------------------+-----------+----------+-------------------------------------------------+ | Table | Op | Msg_type | Msg_text | +------------------+-----------+----------+-------------------------------------------------+ | test.t_histogram | histogram | status | Histogram statistics created for column 'age'. | | test.t_histogram | histogram | status | Histogram statistics created for column 'name'. | +------------------+-----------+----------+-------------------------------------------------+ 2 rows in set (0.01 sec) #删除示例(直方图以列为单位存储) mysql> analyze table t_histogram drop histogram on name ; +------------------+-----------+----------+-------------------------------------------------+ | Table | Op | Msg_type | Msg_text | +------------------+-----------+----------+-------------------------------------------------+ | test.t_histogram | histogram | status | Histogram statistics removed for column 'name'. | +------------------+-----------+----------+-------------------------------------------------+ 1 row in set (0.01 sec) mysql> analyze table t_histogram drop histogram on name,age ; +------------------+-----------+----------+--------------------------------------------------+ | Table | Op | Msg_type | Msg_text | +------------------+-----------+----------+--------------------------------------------------+ | test.t_histogram | histogram | status | Histogram statistics removed for column 'age'. | | test.t_histogram | histogram | Error | No histogram statistics found for column 'name'. | +------------------+-----------+----------+--------------------------------------------------+ 2 rows in set (0.01 sec)复制
2、MySQL新增参数histogram_generation_max_mem_size用来控制可用于直方图生成的最大内存量默认20000000,可以全局或session级别动态设置。如预估读入内存的数据量超过 histogram_generation_max_mem_size 时,MySQL 会使用page-level的SYSTEM采样,均匀的采样数据。
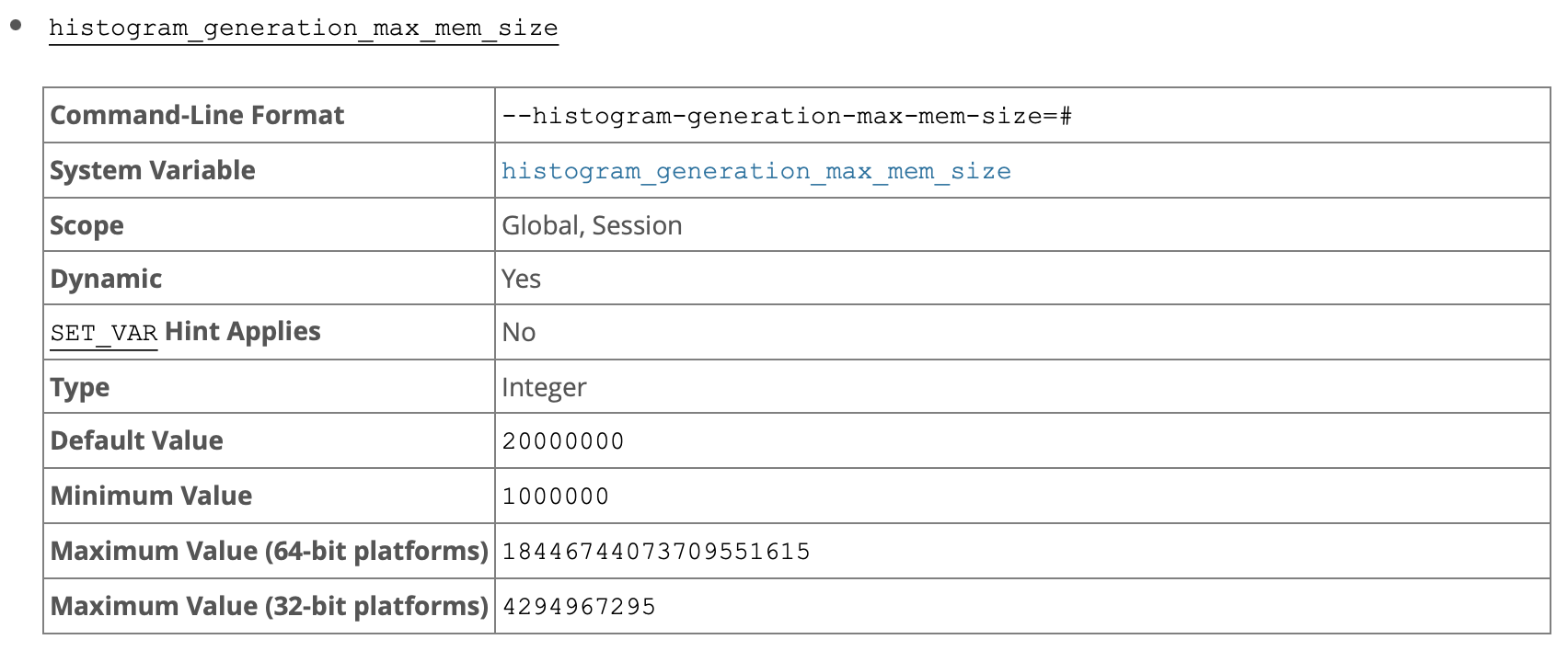
可以通过 INFORMATION_SCHEMA.INNODB_METRICS 视图查看innodb data page扫描统计
mysql> SET GLOBAL innodb_monitor_enable = 'sampled%'; ---- 重置InnoDB Metric计数器 Query OK, 0 rows affected (0.00 sec) mysql> analyze table sbtest2 update histogram on k with 200 buckets; ---- 创建直方图 +-------------------------+-----------+----------+----------------------------------------------+ | Table | Op | Msg_type | Msg_text | +-------------------------+-----------+----------+----------------------------------------------+ | test_recovery_1.sbtest2 | histogram | status | Histogram statistics created for column 'k'. | +-------------------------+-----------+----------+----------------------------------------------+ 1 row in set (11.76 sec) mysql> SELECT HISTOGRAM->>'$."sampling-rate"' FROM INFORMATION_SCHEMA.COLUMN_STATISTICS where table_name='sbtest2'; ----- 直方图中采样率为100% +---------------------------------+ | HISTOGRAM->>'$."sampling-rate"' | +---------------------------------+ | 1.0 | +---------------------------------+ 1 row in set (0.00 sec) mysql> SELECT NAME, COUNT FROM information_schema.innodb_metrics WHERE NAME LIKE 'sampled%'; +-----------------------+-------+ | NAME | COUNT | +-----------------------+-------+ | sampled_pages_read | 1887 | ---- 扫描了 1887个page | sampled_pages_skipped | 0 | ---- 跳过了0个page +-----------------------+-------+ 2 rows in set (0.00 sec) mysql> SET GLOBAL innodb_monitor_enable = 'sampled%'; ---- 重置InnoDB Metric计数器 Query OK, 0 rows affected (0.00 sec) mysql> set histogram_generation_max_mem_size=1000000;-----配置histogram_generation_max_mem_size为最小值 Query OK, 0 rows affected (0.00 sec) mysql> analyze table sbtest2 update histogram on k with 200 buckets; ----创建直方图 +-------------------------+-----------+----------+----------------------------------------------+ | Table | Op | Msg_type | Msg_text | +-------------------------+-----------+----------+----------------------------------------------+ | test_recovery_1.sbtest2 | histogram | status | Histogram statistics created for column 'k'. | +-------------------------+-----------+----------+----------------------------------------------+ 1 row in set (2.16 sec) mysql> SELECT HISTOGRAM->>'$."sampling-rate"' FROM INFORMATION_SCHEMA.COLUMN_STATISTICS where table_name='sbtest2'; ----- 直方图中采样率为18.19% +---------------------------------+ | HISTOGRAM->>'$."sampling-rate"' | +---------------------------------+ | 0.18198547610312318 | +---------------------------------+ 1 row in set (0.00 sec) mysql> SELECT NAME, COUNT FROM information_schema.innodb_metrics WHERE NAME LIKE 'sampled%'; +-----------------------+-------+ | NAME | COUNT | +-----------------------+-------+ | sampled_pages_read | 343 | ---- 扫描了 343个page | sampled_pages_skipped | 1544 | ---- 跳过了1544个page +-----------------------+-------+ 2 rows in set (0.00 sec)复制
3、数据字典表column_statistics用来存储各列值的直方图统计信息。该表存储除几何类型(空间数据)和 JSON 之外的所有数据类型的列统计信息,该表持久化存储由MySQL更新,用户不能直接读写,只能通过视图INFORMATION_SCHEMA.COLUMN_STATISTICS查询。

column_statistics视图中按行存储统计信息,直方图信息以JSON格式存放在HISTOGRAM列中;以上图两行HISTOGRAM数据为例分析下具体内容;
- 等宽/单例直方图
SCHEMA_NAME: test ---- 库名 TABLE_NAME: t_histogram ---- 表名 COLUMN_NAME: age ---- 列名 { "buckets":[ ----等宽直方图bucket存储两部分数据 1、列值 2、该值累积频率,即小于等于该值的数据占比 [ 20, ---- 列值为20 0.24358974358974358 ---- 该列约24.3%的数据小于等于20 ], [ 21, 0.47435897435897434 ], [ 22, 0.7564102564102564 ], [ 23, 1 ] ], "data-type":"int", ---- 数据类型是int "null-values":0, ----该列中NULL值的占比,0代表没有空值 "collation-id":8, ----直方图数据的排序规则 ID。 当数据类型值为字符串时,它最有意义。 值对应于 INFORMATION_SCHEMA.COLLATIONS 表中的 ID 列值。 "last-updated":"2021-09-02 07:03:06.383154", ----直方图最后更新时间 UTC value "sampling-rate":1, ----采样比例,1表示读取所有数据 "histogram-type":"singleton", ---- 直方图类型,singleton 等宽直方图,equi-height等高直方图 "number-of-buckets-specified":5 ---- 在生成直方图的 ANALYZE TABLE 语句中指定的桶数。 }复制
- 等高直方图
SCHEMA_NAME: test ---- 库名 TABLE_NAME: t_histogram ---- 表名 COLUMN_NAME: name ---- 列名 { "buckets":[ ----等高直方图bucket存储四部分数据 1、最小值 2、最大值 3、上限值的累积频率 4、上下限间数值的distinct values [ ---- 第一个桶 "base64:type254:amFt", ---- 最小值 "base64:type254:bGVlMjA=", ---- 最大值 0.16666666666666666, ---- 该列16.6%的数据小于等于该桶最大值 13 ---- 该桶含13个不同的值 ], [ "base64:type254:bGVlMjE=", "base64:type254:bGVlMzM=", 0.3333333333333333, 13 ], ………………, ………………, [ "base64:type254:bGVlNw==", "base64:type254:dGluYQ==", 1, 13 ] ], "data-type":"string", ----该列数据类型是字符串 "null-values":0, ----该列没有null值 "collation-id":255, ----直方图数据的排序规则 ID "last-updated":"2021-09-02 07:04:13.174101", ---- 直方图最后更新时间 UTC value "sampling-rate":1, ----读取全部数据生成直方图 "histogram-type":"equi-height", ---- 等高直方图 "number-of-buckets-specified":6 ---- 共6个桶 } #排序规则 mysql> select * from INFORMATION_SCHEMA.COLLATIONS where id=255; +--------------------+--------------------+-----+------------+-------------+---------+---------------+ | COLLATION_NAME | CHARACTER_SET_NAME | ID | IS_DEFAULT | IS_COMPILED | SORTLEN | PAD_ATTRIBUTE | +--------------------+--------------------+-----+------------+-------------+---------+---------------+ | utf8mb4_0900_ai_ci | utf8mb4 | 255 | Yes | Yes | 0 | NO PAD | +--------------------+--------------------+-----+------------+-------------+---------+---------------+ 1 row in set (0.01 sec)复制
4、在MySQL中直方图的使用有以下限制
1、不支持加密表或临时表
2、不支持几何类型(空间数据)和 JSON类型的列
3、单列唯一索引上不能创建直方图
4、可以为存储的和虚拟生成的列生成直方图
5、DDL对直方图的影响
1、drop table 删除相关表的直方图
2、drop database 删除相关库中的直方图
3、RENAME TABLE 不会删除直方图。 相反,它为重命名的表重命名直方图以与新表名称相关联。
4、删除或修改列的 ALTER TABLE 语句会删除该列的直方图。
5、ALTER TABLE … CONVERT TO CHARACTER SET 删除字符列的直方图,因为它们受字符集更改的影响。 非字符列的直方图不受影响。
6、MySQL优化器目前可以对以下查询谓词使用直方图,优化执行计划
col_name = constant col_name <> constant col_name != constant col_name > constant col_name < constant col_name >= constant col_name <= constant col_name IS NULL col_name IS NOT NULL col_name BETWEEN constant AND constant col_name NOT BETWEEN constant AND constant col_name IN (constant[, constant] ...) col_name NOT IN (constant[, constant] ...)复制
7、禁用直方图有两种方式
#1、删除直方图 ANALYZE [NO_WRITE_TO_BINLOG | LOCAL] TABLE tbl_name DROP HISTOGRAM ON col_name [, col_name] ... #2、禁用condition_fanout_filter SET optimizer_switch='condition_fanout_filter=off';复制
8、简单的栗子
测试表定义及数据量
mysql> show create table sbtest2\G *************************** 1. row *************************** Table: sbtest2 Create Table: CREATE TABLE `sbtest2` ( `id` int NOT NULL AUTO_INCREMENT, `k` int NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT '', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec) mysql> select count(*) from sbtest2; +----------+ | count(*) | +----------+ | 100000 | +----------+ 1 row in set (0.07 sec)复制
无直方图测试
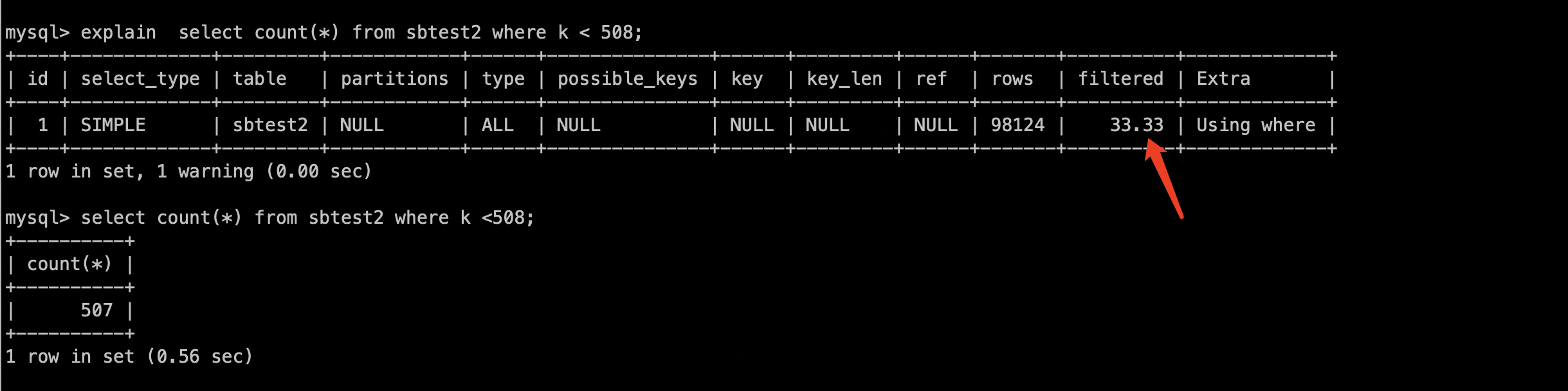
在k列上创建200个桶的直方图
mysql> analyze table sbtest2 update histogram on k with 200 buckets; +-------------------------+-----------+----------+----------------------------------------------+ | Table | Op | Msg_type | Msg_text | +-------------------------+-----------+----------+----------------------------------------------+ | test_recovery_1.sbtest2 | histogram | status | Histogram statistics created for column 'k'. | +-------------------------+-----------+----------+----------------------------------------------+ 1 row in set (14.12 sec) mysql> select * from information_schema.column_statistics where table_name='sbtest2'\G *************************** 1. row *************************** SCHEMA_NAME: test_recovery_1 TABLE_NAME: sbtest2 COLUMN_NAME: k HISTOGRAM: {"buckets": [[1, 500, 0.005, 500], [501, 1000, 0.01, 500], [1001, 1500, 0.015, 500], [1501, 2000, 0.02, 500], [2001, 2500, 0.025, 500], ,…………………………, ,[98001, 98500, 0.985, 500], [98501, 99000, 0.99, 500], [99001, 99500, 0.995, 500], [99501, 100000, 1.0, 500]], "data-type": "int", "null-values": 0.0, "collation-id": 8, "last-updated": "2021-09-02 09:51:04.780992", "sampling-rate": 1.0, "histogram-type": "equi-height", "number-of-buckets-specified": 200} 1 row in set (0.01 sec)复制
再次执行相同语句,可以看到filtered列的区别
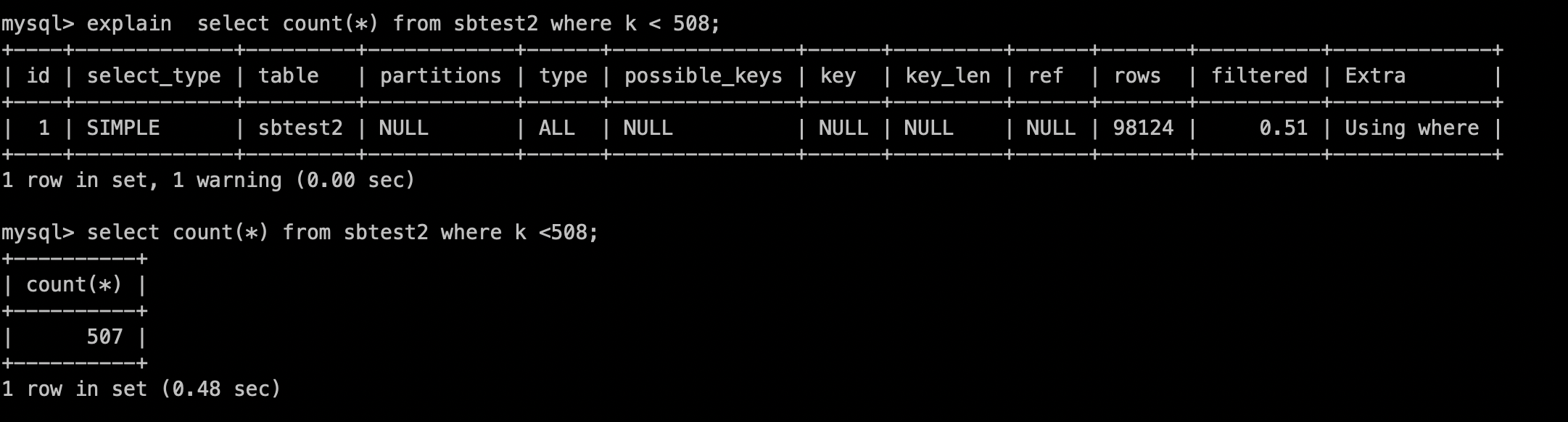
这里只是做了一个简单的介绍,有兴趣的朋友可以深入研究下。
