




这篇我主要是针对分库分表、微服务和烟囱建设等说的。
我以前做公安行业的,人车管控。比如一辆车开过一个路口或者一个路段,被监控设备抓拍。那就是一条数据(含图片)。早期数据不多并发不高的时候我们图片是存数据库的。每秒100的并发写入问题不大。后期数据也多了平台也大了,为了缓解数据库压力,图片另外存,url连接存在数据库中。每秒上千写入问题也不大。连缓存都不用,单机稳稳的。每个项目数据10亿级别起,最大的项目单表100亿,数据库容量可大100TB。以前我一直觉得我这个可以了。但是有一次平安公司的说他们核心库,一级库,300TB。果然天外有天。以上主要为了说明单机数据库足以应付绝大多数应用场景。
那如果不是单机呢?烟囱建设不是不可以,大家井水不犯河水。不过一旦设计到各个数据库说要做汇总,或者数据做交互,这就麻烦了。假设ABCDE五个项目每个项目至少用了一个数据库。这些数据库所承载的业务有上下游或者前后关系。A要给B一些,也不知道B有没有,开发一个程序一股脑儿给几万数据到B,B系统要一个个核对。C要向A要数据(和之前A给B不一样),C怕少要了,就请求了更大范围的。 D要汇总数据,但是怎么知道ABC上的数据呢?用etl去select。
问题来了,怎么知道数据新增的呢?需要新增数据有时间戳。对于没有时间戳的系统就要进行改造。找得到人还有希望,找不到开发方或者这个是采购来的产品无法改造就麻烦了。如果数据只是增加还好说,更多的是数据修改,一个表的10个字段改了1个,D首先要知道哪些是改了的,然后要把这些数据拿过来再对比才能知道哪个变了。其实如果在原始数据库上其实不关心修改之前是什么样子,只关注当前状态。但是etl就不知道。而且etl不能实时(每秒一次)获取,必须定时,否则ABC系统受不了。最可怕的事情还没说,那就是有时候源端还有可能del。这etl根本找不到了。
如果说都是同构比如说Oracle,还有办法,最简单的是dblink+物化视图。定时刷新。优点: 缺点:
数据一致性可以保证; 不宜过多表
准实时; 不宜太频繁,不建议小于1min
免费; 建立好以后源端不能加字段,否则要重做
数据不用去做对比; 大表建立物化视图时间较长
相对etl压力较低 长时间中断物化视图,可能要重建
有些数据库没有dblink以上就没法做,但是可以通过其他方式比如mysql和pg都有归档日志,解析这些归档日志就可以做到。但是异构数据库太多了需要全部都去处理。还有SQLSERVER db2等等。
我最近尝试OGG的功能,最早OGG是只能oracle到oracle。现在的ogg的架构是:

实测了一下,源库MYSQL5.7 MySQL8 Oracle19C(PDB )模式。目标端Oracle19C(PDB)模式。
目标端使用Oracle的原因
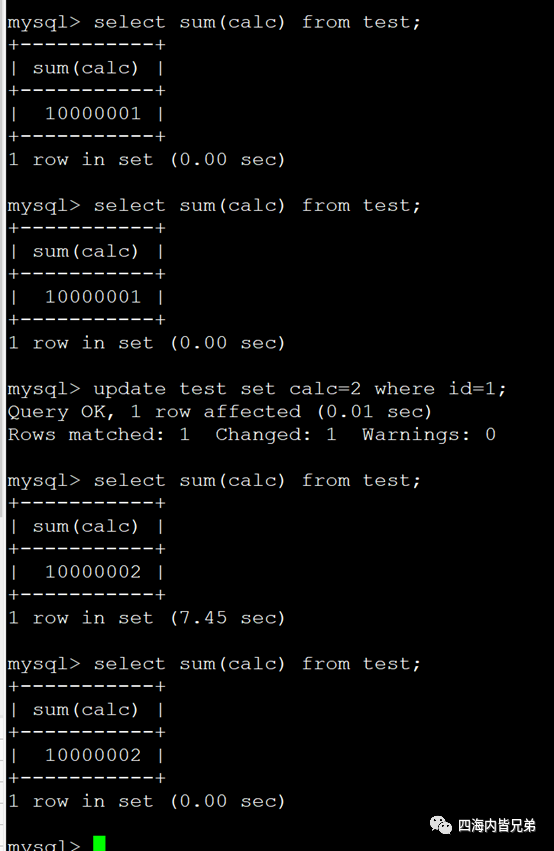
MySQL5.7虽然自带缓存,但是写操作后缓存失效.下图是5.7
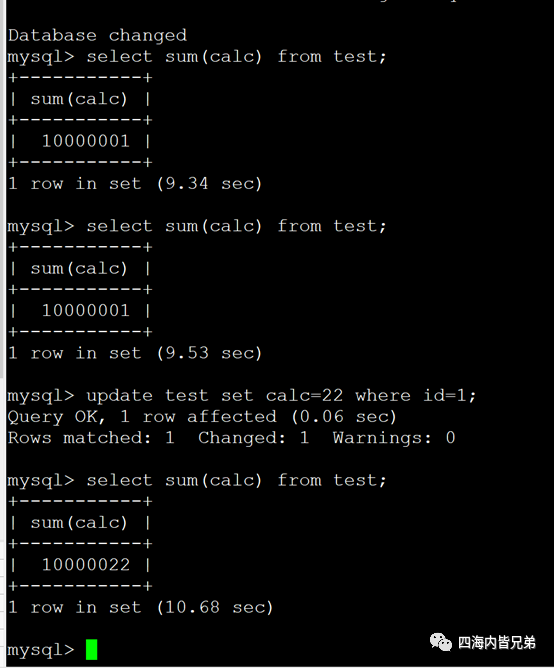
MySQL 8进一步定位MySQL作为OLTP系统,取消了缓存结果集。MySQL单机版基本放弃分析功能。只有云版支持OLAP。(大家可以去看看甲骨文云版的MYSQL最近一直在推)分析场景不推荐使用MySQL8。下图是8
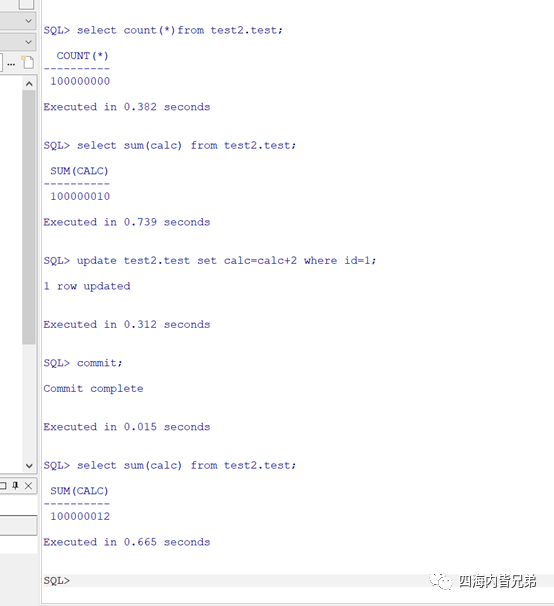
Oracle单表亿级别数据,分析在秒以下。实时计算,没有缓存。主要是因为她是行列混存。应用透明。
业内所有数据同步方案都存在瑕疵,OGG方案是所有方案中最透明(业内使用人最多,可以较好的获得支持和定位问题),中间过程一目了然。
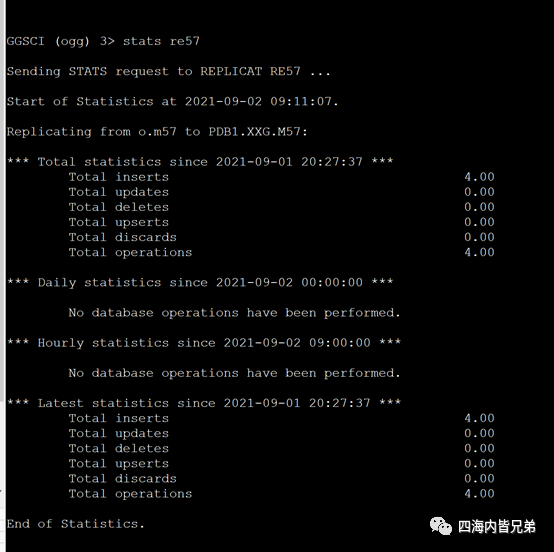
而且我觉得他是目前问题最少的解决方案(金融行业容灾的成熟方案)。
我上面说的是问题最少,也不能说一点也没有。如果要一点也没有,那就是不同步。一个数据库,这些问题就都解决了。
什么?库大了?想想我100TB的库以及平安300TB的库。我看还见过PB级别的关系型数据库。
