




方案一:时间轮算法
slot = (当前时间戳 - 时间轮启动时间) % slot总数;
round = (当前时间戳 - 时间轮启动时间) / slot总数;
延时消息链表:按round排序。
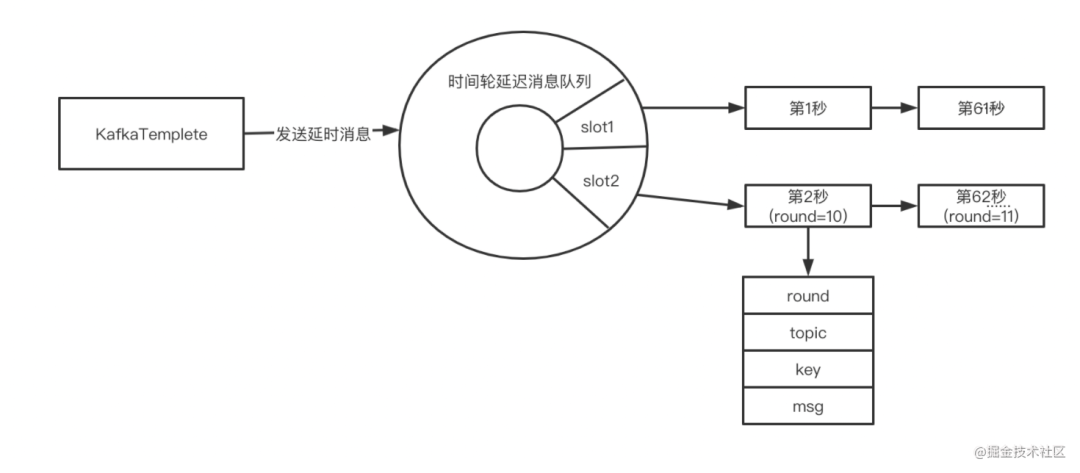
消耗内存资源严重,只适用于延迟时间短(如一分钟内)的场景;
容易丢失消息。
方案二:单轮时间轮算法+文件存储(方案一的改进版)
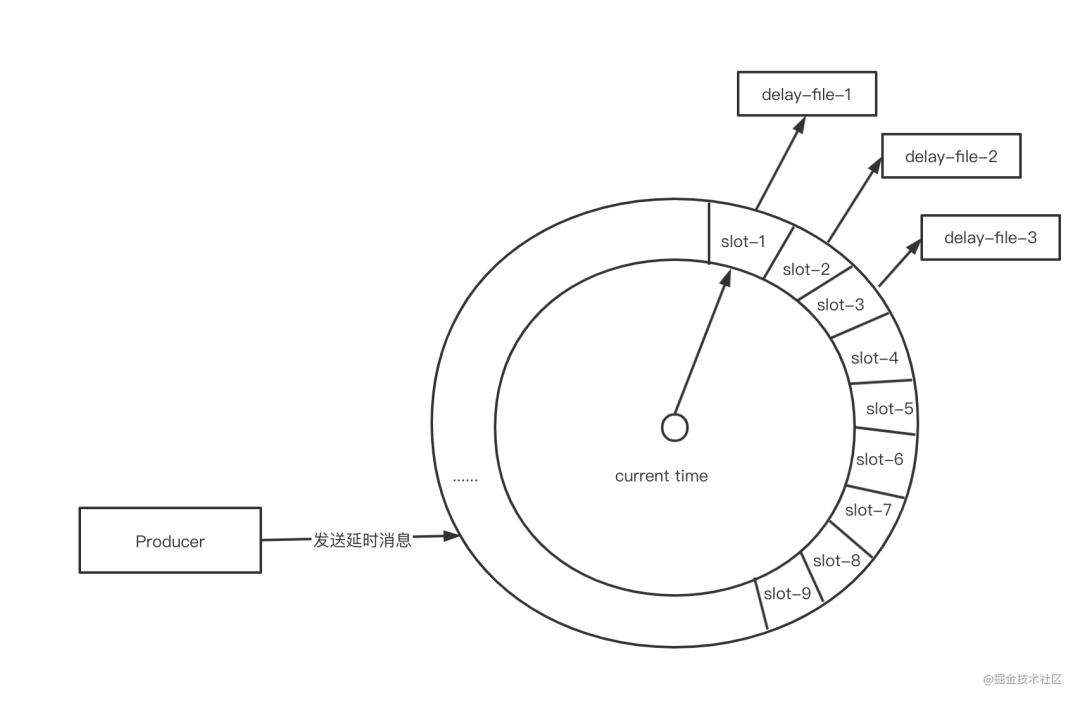
如果服务容器化部署,重新构建后也会导致时间轮文件丢失,无法保证消息一致性。
方案三:多级分区+自动降级
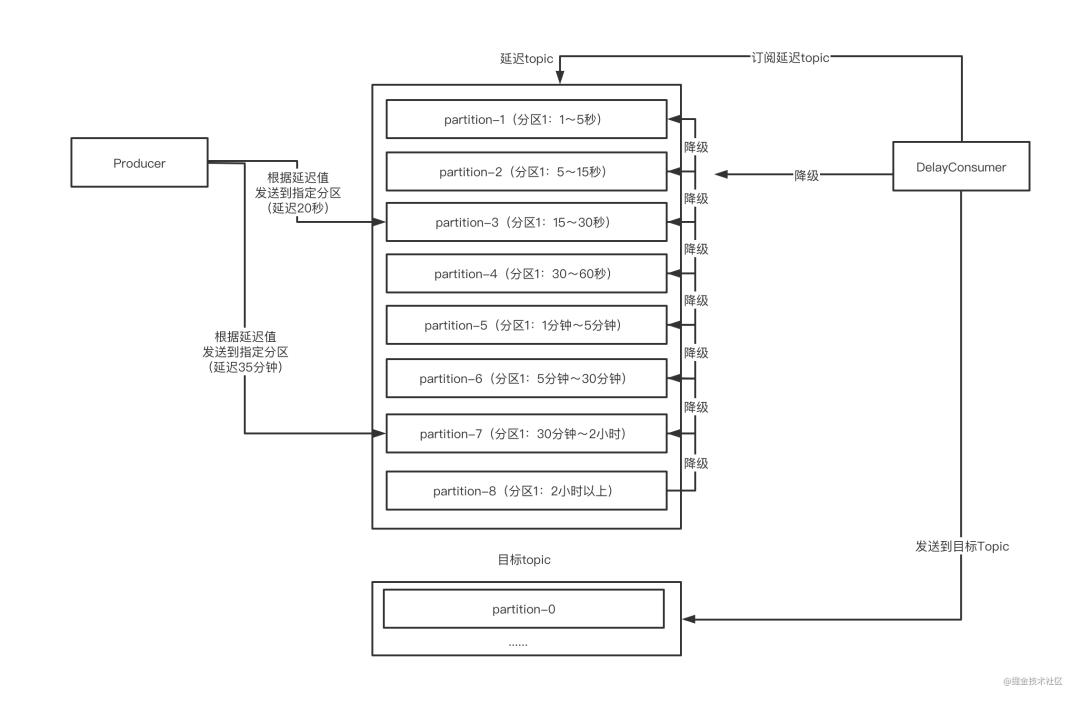
需要经过多次发送-订阅,如果按照图中的等级划分,那么一个延迟2小时的消息至少要经过8次订阅、9次发送才最终发送到目标topic;
由于同一个等级中每个消息的延时不同,如果要确保消息延迟准确,就可能导致一条消息不止需要经过8次订阅、9次发送才最终发送到目标topic,这次数可能会翻好几倍。
50、40、36、56,为了不影响后面的延时消息,前面每个消息都必须要消费,然后重新写回同等级分区。因此,最坏的情况下,延时高的消息可能需要经过上百次发送-订阅才能完成。
方案四:多级延迟,不支持任意时间精度的延迟消息(方案三的改进版)
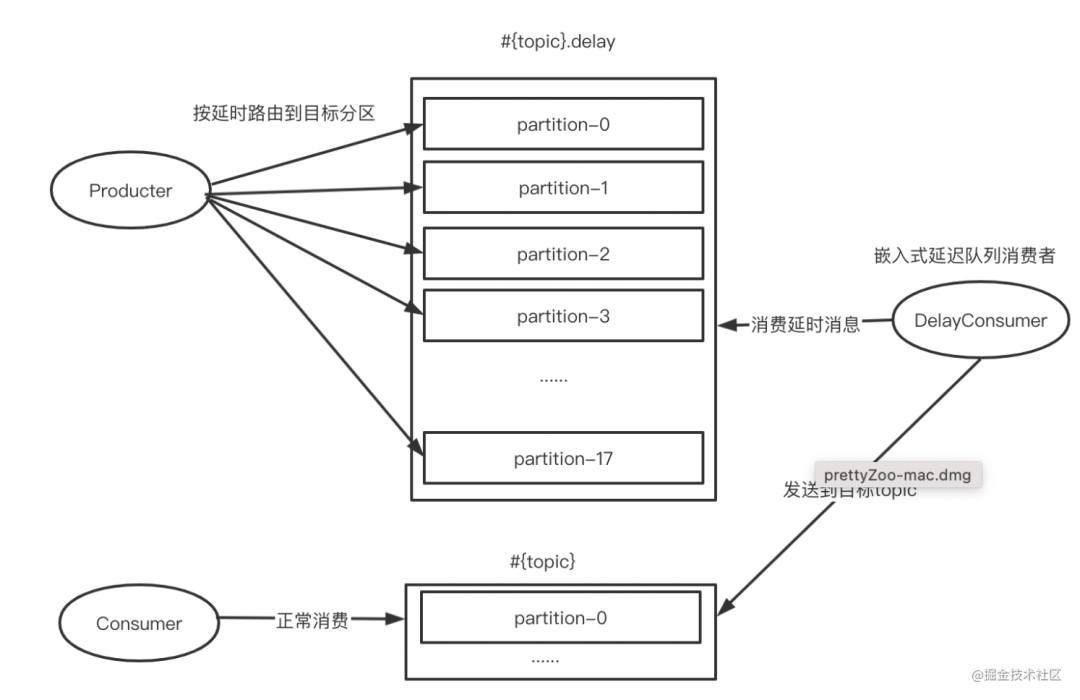
当发送延迟5秒消息时,将消息发送到order-topic.delay的第二个分区;
当发送延迟1分钟消息时,将消息发送到order-topic.delay的第五个分区;
当发送延迟1小时消息时,将消息发送到order-topic.delay的第17个分区;
保证了每个分区中的消息都是时间顺序的,只需要顺序消费每个分区,将已经达到发送时间的消息转发到真实topic即可;
如果消息未到达发送时间,则不需要提交offset,因为相同分区上的offset之后的消息也必定是未到发送时间的。

最后修改时间:2021-09-06 19:02:35
文章转载自Java艺术,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
