




1. 介绍
时序数据指存储、索引以时间为基准的数据点序列。通常情况下,时序数据都是基于稳定频率产生的,比如监测气象条件时,按照固定时间间隔采集的风力数据就是一条时间序列。
时序数据具有以下基本属性:
metric(指标):采集的数据指标。如城市的风力,类似关系数据库中的 table;
tag(标签):维度列,表示数据的归属。如城市名、地区名,一般不随时间变化,供查询使用;
field(字段):指标列,表示数据的测量值。如风力、风速,一般存放的是随时间变化的值,一个指标可以有多个字段;
timestamp(时间戳):数据测量值产生的时间点;
data point(数据点):针对检测对象的某项指标按特定时间间隔采集的每个指标值就是一个数据点,类似关系表中的一行。
借个栗子,如下表所示,风力指标这个 metric 包含了 3 个数据点。从这里可以看出如果按照关系型数据库的组织方式来存放时序数据可能会造成大量的数据冗余。
| timestamp | city | region | direction | speed |
| 1626935722 | hangzhou | xihu | E | 3-4 |
| 1626935737 | hangzhou | xihu | W | 4-5 |
| 1626935752 | hangzhou | xihu | EW | 2-3 |
时序数据的需求涉及到写入、读取和存储三个部分,一个明显的特点就是读多写少:
写入:在工业环境中每秒钟产生的数据点众多,需要支撑每秒钟上千万甚至上亿的写入能力;
读取:时序数据通常需要进行聚合采样,需要较低的读取时延;
存储:对于采集到的海量时序数据,高效稳定的存储也非常重要。

对于指标序列的读写,可以简单概括为“垂直写,水平读”,意思是指标采集系统通常会“垂直地”写入多个指标在最近时刻的样本点,而在读取时,只会“水平地”读取某个或某几个时间序列在某一段时间内的样本值。


2. 技术背景
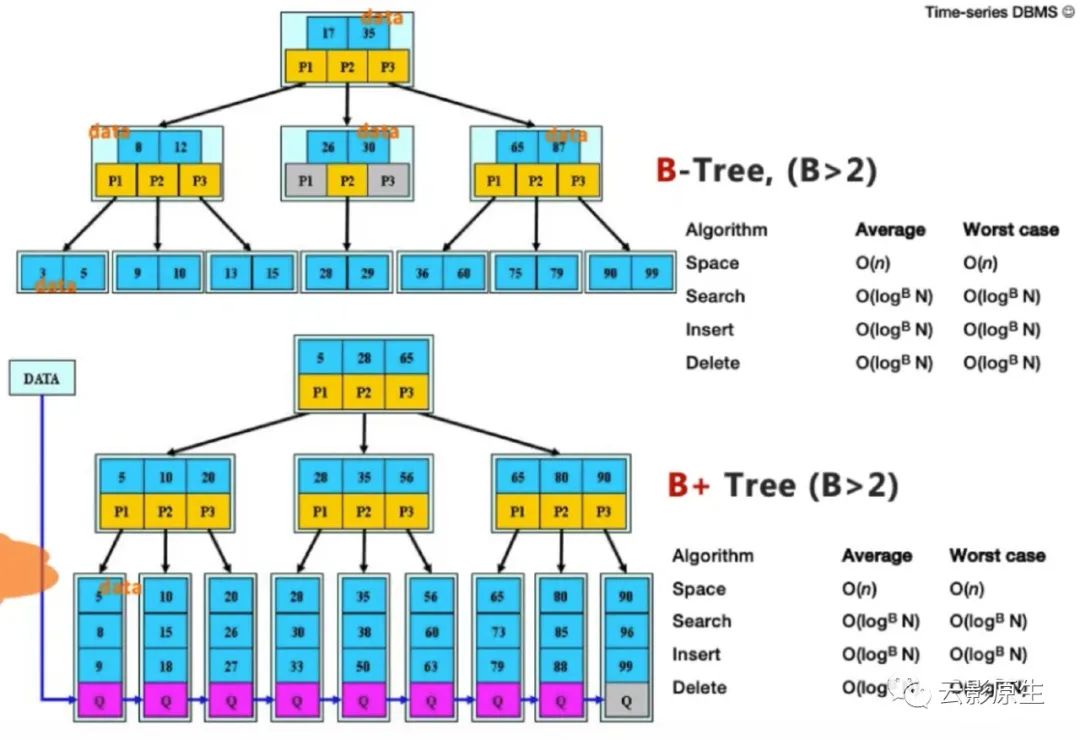
2.1 B/B+ Tree
B 树是一种多叉多路平衡树,相比于红黑树、跳跃表等数据结构,它的一个特点就是面向磁盘或者文件系统友好,树的高度很低,查询过程中的 IO 次数减少,同时能够利用局部性访问原理,使得其更适合存储在磁盘。
B+ 树在 B 树的基础上更进一步,将树上节点的存储对象从数据与指针全部变成了指针,提供了比 B 树更高的存储效率。同时数据全部位于叶子节点,再添加上叶子间的双向指针,就可以支持范围检索。
大多传统关系型数据库的数据存储与索引的基本结构都是 B 树和 B+ 树。
2.2 LSM Tree
回到时序存储场景中来,时序数据存储特点为读多写少,因此写入性能至关重要。
如果使用关系型数据库的方案 B 树来组织数据,会发生什么呢?我们知道在 B 树的构建过程中会涉及到节点的分裂与合并,将会产生随机 IO。当写入次数变多时,随机 IO 带来的时延将影响存储系统的平均写入时延。
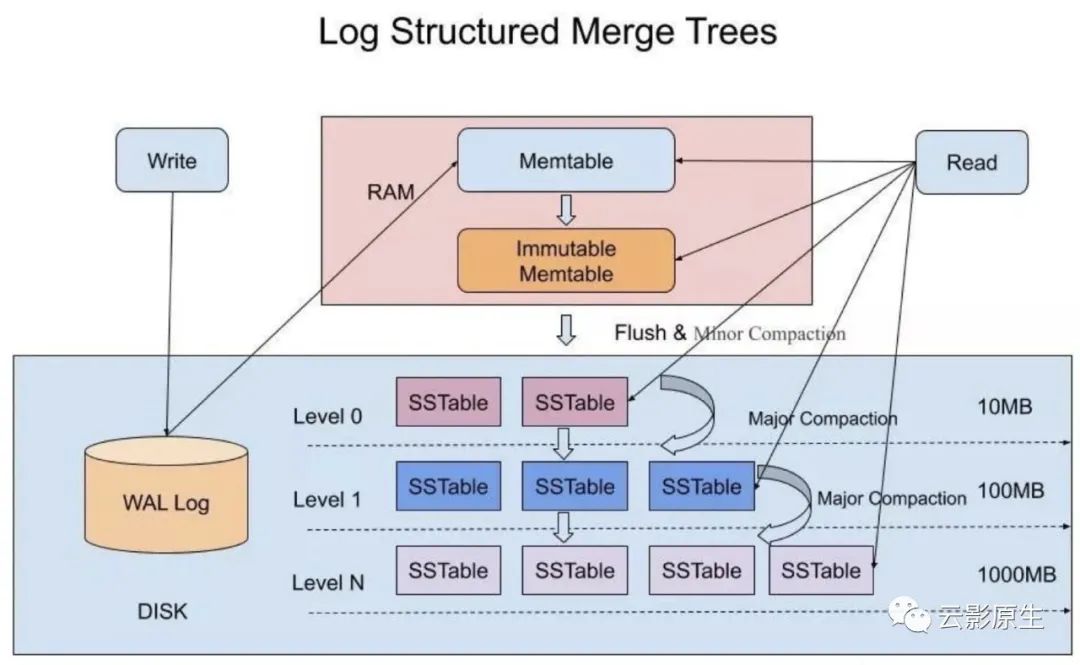
LSM Tree(Log-structured Merge Tree,日志结构合并树)是一种解决方案。
LSM Tree 其实已经不能叫做数据结构了,它是一种存储架构,特点是分层、有序、磁盘友好。LSM Tree 起初是分布式键值存储系统 BigTable 的底层核心结构,现在是很多 NoSQL 数据库的核心结构,包括 Apache HBase、Apache Cassandra、LevelDB、RocksDB 等。LSM Tree 的总体思想就是以牺牲读性能为代价,将离散的随机写转换成批量的顺序写。
核心数据结构:
SSTable
SSTable (Sorter String Table)是一种持久、有序、不可变的键值存储结构。它将键值数据按照 key 的顺序存储,并且尾部还附加有 index,用于帮助快速查找特定的 key 和 value。

MemTable
内存中的数据结构,存储最近的数据。Memtable 中的数据也需要保持有序,可以借助红黑树或者跳跃表来实现。例如 Hbase 使跳跃表来保证内存中 key 的有序。由于是存储在易失性存储内存中,所以通常需要 WAL(预写日志)来辅助存储。
Immutable MemTable
Memtable 会根据条件按照规律(如占用内存大小或者时间)flush 到磁盘中,存储为 SSTable。Immutable MemTable 就是这个转换过程的中间状态,当 memtable 开始 flush 时就会变成 immutable memtable,其中的数据不再变化,并创建一个新的 memtable 用于保存新数据,不阻塞读写。
怎么写?
收到写请求,会先把该条数据记录在 WAL 里面,用作故障恢复;
数据写入内存中的 memtable;
memtable 到达一定大小或时间,会变成 immutable memtable,数据冻结,同时创建一个新的 memtable 用于写入;
将内存中的 immutable memtable 转换成 SSTable 写入磁盘,这一步叫做 Minor Compaction,生成的都是 Level 0 的 SSTable。这一层的 SSTable 可能存在重叠的 key,所以查询到 Level0 层时需要遍历所有的 SSTable。Level 大于 0 的 SSTable 不会出现重叠 key;
SSTable 体积过大时也会继续触发合并,这一步叫做 Major Compaction。由于 SSTable 是有序的,所以可以采用归并排序的思想合并加快合并速度。合并后,key 将不再重叠,value 将是最新,旧 SSTable 会被删除。
怎么读?
查询内存中的 memtable 和 immutable memtable 中是否存在 key,存在返回,不存在则开始查询 SSTable;
每次查询一层 SSTable,存在则返回,不存在则继续进入下一层,直到找到 key 或到达最后一层。
内存中的查询可以通过特定的数据结构高效进行,但是 SSTable 的查询涉及到磁盘 IO,比较耗时。如果不优化的话,最差情况下一次查询将会遍历查询所有的 SSTable。解决这个问题有比较多的方法,LevelDB 的做法是引入布隆过滤器,用来过滤不包含目标 key 的 SSTable(布隆过滤器判断为不存在则 key 一定不存在于 SSTable,反之则不一定)。
怎么删?
LSM Tree 中的删除操作是一种特殊的写入。写入的 key 为原 key,value 则为 tombstone 标记。在查询时,tombstone 标记会将原有的值覆盖,返回结果变更为 key 已删除。tombstone 会在合并时被从磁盘中删除。
3. Prometheus TSDB
3.1 背景
Prometheus 是一个指标采集存储系统。Prometheus 中的 TSDB 负责管理时序指标数据。TSDB 原先是一个独立的模块,后续被直接合并进 Prometheus 项目。Prometheus 也是一个时序数据库,在 db-engine 时序数据库分类下排名第三,具有相当高的热度。
Prometheus 最初是一个构建在 SoundCloud 上的监控系统,于 2016 年成为继 Kubernetes 之后的第二个 CNCF 孵化项目,并于 2018 年毕业。Prometheus 采用 Go 语言实现,目前Prometheus 最新版本为 2.28,使用的 TSDB 为 V3 版本。
以下分析基于 Prometheus 2.28。
3.2 特性
独立部署,无外部依赖;
存储高效,平均一个样本点只占用 1 到 2 字节;
生态丰富,Prometheus 指标格式近乎成为指标事实标准,各种 exporter 丰富;
查询语言 PromQL 功能强,支持多种聚合分析函数;
指标采集功能强,默认支持 pull,同时支持 push 模式,同时具有多种采集目标的动态发现功能;
自带告警功能丰富。
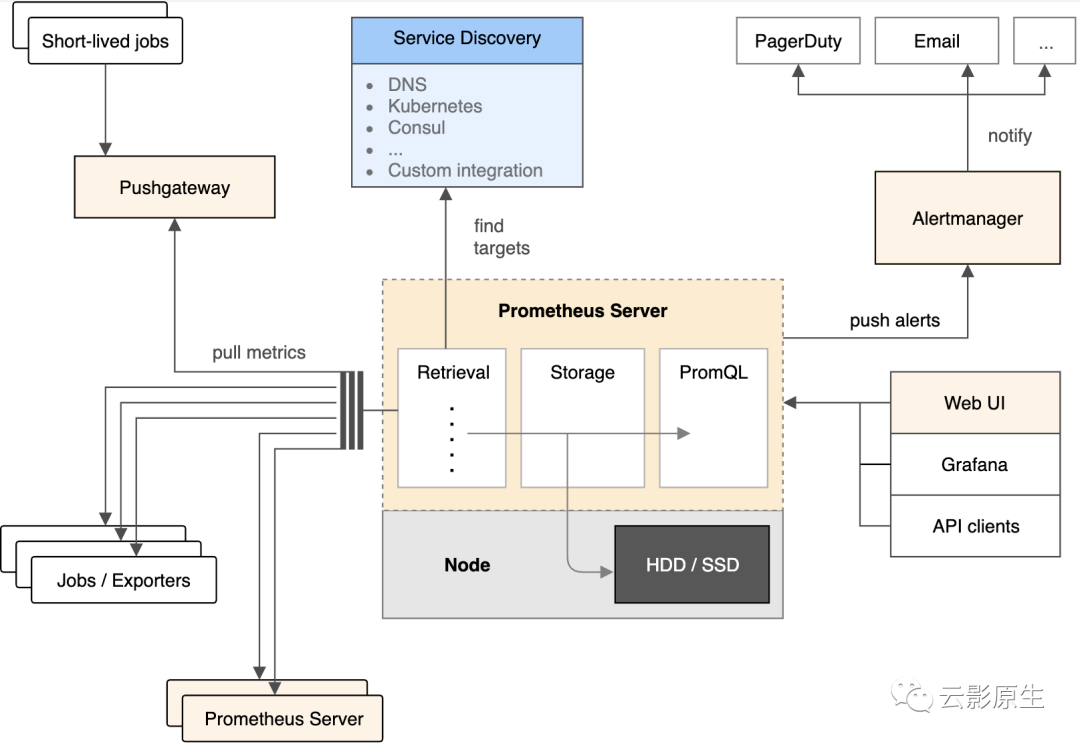
3.3 优势
生态丰富,exporter 种类多而且开发简单,remote read/write 接口提供了与外部数据对接的能力;
PromQL 灵活简便,同时功能强大;
服务发现功能强,支持 Kubernetes、Consul、DNS 等多种发现方式,非常适用于在动态环境中采集指标;
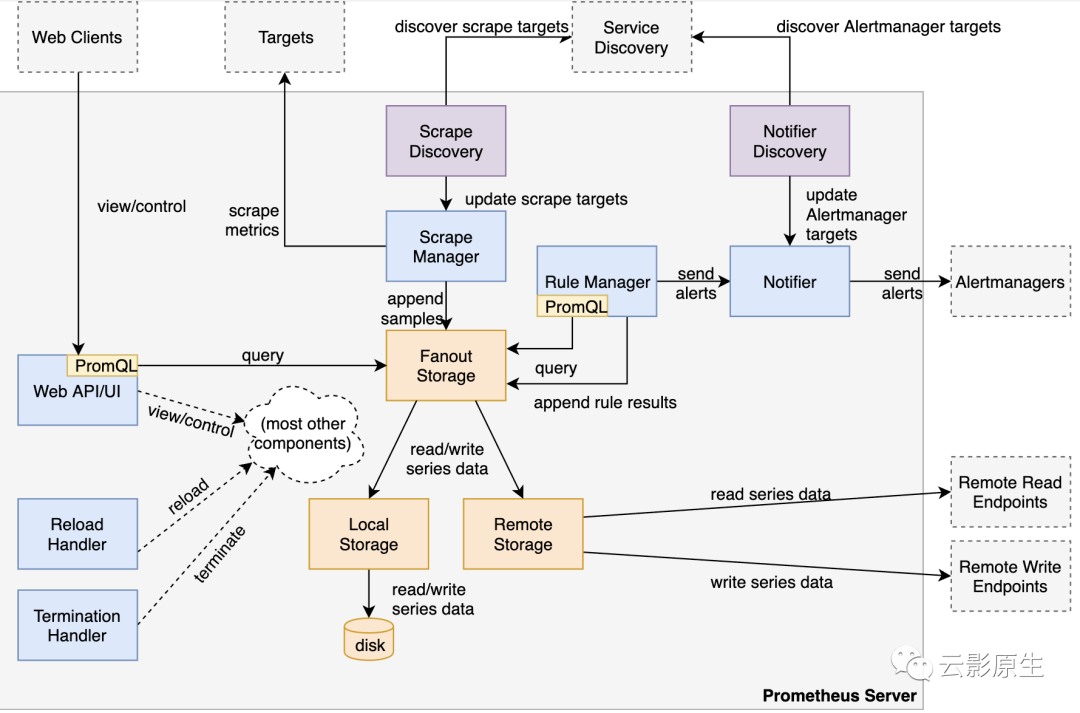
3.4 架构
(1)生态架构
(2)内部架构
3.5 集群模式
Prometheus 默认单机部署,且不适用于持久化保存指标。
Prometheus 的集群方案有:
联邦集群:Prometheus 可以嵌套采集指标。部署多个实例并进行任务分片,然后再通过顶层 Prometheus 进行指标聚合,可以达成 Prometheus 集群的效果;
Thanos:Prometheus 高可用集群解决方案;
VictoriaMetrics
3.6 数据格式
Prometheus 指标本质上是一个由指标名、标签、时间戳和指标值组成的组合。如果进一步抽象的话,时间戳和指标值组成了样本点,因此指标可以被视为由指标名、样本点组成的键值对。所以 Prometheus 中的 tsdb 是一个典型的时序数据库。
在了解 Prometheus 的时序存储系统之前,最好先明确一下 Prometheus 中的一些概念:
label:标识性的键值。如
method="GET"
中的method
;series:label-value 集合,用于标识时间序列。如
{__name__=”requests_total”, path=”/status”, method=”GET”, instance=”10.0.0.1:80”}
;
下图就是典型的 Prometheus 指标。和我们平时用到的指标 metric{k="v"}
不同,但是在时序存储系统中,上述的指标就会被表示成 {__name__="metric",k="v"}
。可以看到 series 其实是用来标识由 timestamp 和 value 组成的序列的标识符。

3.7 数据压缩
Prometheus TSDB 从 v1 开始,就采用了和 Facebook 的 Gorilla 类似的压缩算法来优化样本的存储空间。Gorilla 是 Facebook 内部的一个纯内存的时序数据库,为了优化内存中的存储空间提出了比较多的优化之处。
一个样本包含一个整型时间戳和一个浮点型样本值,这二者都有不同的压缩算法。
除此之外,TSDB 中还采用了 varint 编码来优化整型数据的存储空间。
(1)整型压缩
Prometheus TSDB 在存储索引时使用和 protobuf 一致的 varint 来编码整型数据。varint 编码是一种变长编码方式,原始数据越小,编码后的字节数越少。
(2)时间戳压缩
指标通常是按照固定时间间隔采集,因此样本中的时间戳在理想情况下应该是一个连续的、公差为正的等差数列,如 [100, 115, 130...]。所以理想情况下,只需要一个时间戳的空间就可以计算出后续所有样本的时间戳。因此最低的空间占用量就是一个时间戳的存储使用量。
但是现实情况中,sample 的时间戳并不是严格的等差数列,时间间隔可能不固定,甚至会出现跳过某个时间戳的情况。所以 Gorilla 采用了 delta of delta 编码的方案,只记录时间戳的二阶差值。
| 原始时间戳 | delta | delta of delta |
| 100 | - | - |
| 115 | 15 | - |
| 131 | 16 | 1 |
| 150 | 14 | -2 |
| 165 | 15 | 0 |
记二阶差值为 D:
如果 D 为 0,那么存储一个bit ‘0’;
如果 D 位于区间 [-63, 64],存储 2 个 bits ’10’,后面跟着用 7 个 bits 表示的 D 值;
如果 D 位于区间 [-255, 256],存储 3 个 bits ‘110’,后面跟着 9 个 bits 表示的 D 值;
如果 D 位于区间 [-2047, 2048],存储 4 个 bits ‘1110’,后面跟着 12 个 bits 表示的 D 值;
如果 D 位于其它区间则存储 4 个 bits ‘1111’,后面跟着 32 个 bits 表示的 D 值。
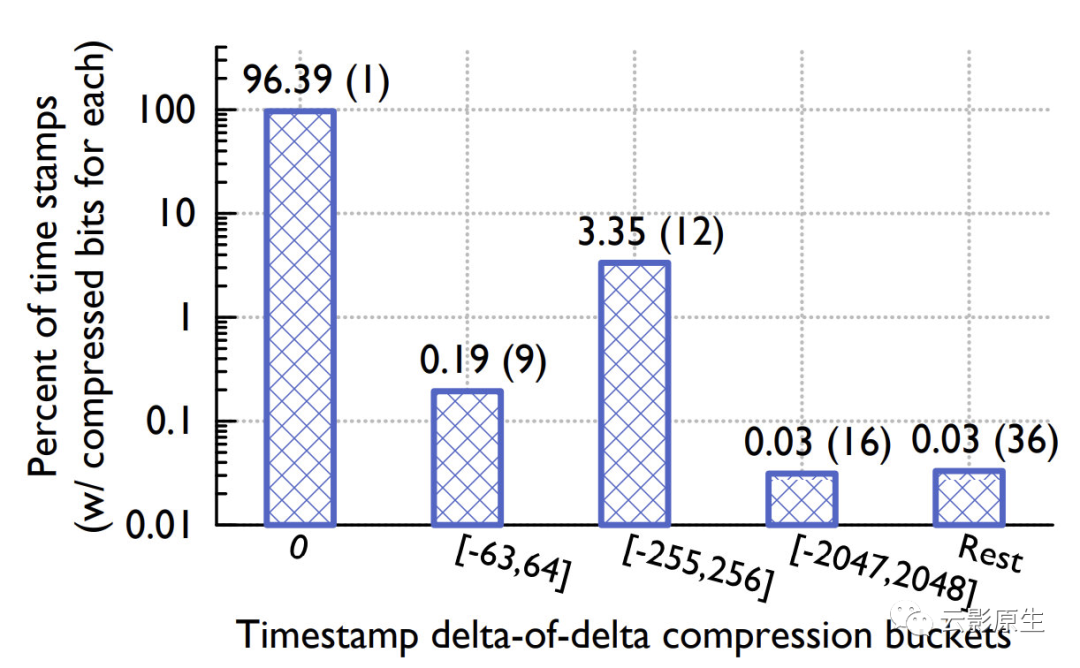
如上图所示,根据 Gorilla 论文统计,经过 delta of delta 编码的时间戳中有 96.39% 只占用 1 bit。
(3)浮点数压缩
delta of delta 编码针对时间戳的等差特征进行了特殊处理,XOR 编码则是针对浮点数变化轻微的情况进行了另一种特殊编码。
XOR编码详细原理如下:
第一个 Value 存储时不做任何压缩;
后面产生的每一个 Value 与前一个 Value 计算 XOR 值:
如果 XOR 值为 0,即两个 Value 相同,那么存为 '0',只占用一个 bit;
如果 XOR 为非 0,首先计算 XOR 中位于前端的和后端的 0 的个数,即 Leading Zeros 与 Trailing Zeros;
第一个 bit 值存为 '1';
如果 Leading Zeros 与 Trailing Zeros 与前一个 XOR 值相同,则第 2 个 bit 值存为 '0',而后,紧跟着去掉 Leading Zeros 与 Trailing Zeros 以后的有效 XOR 值部分;
如果 Leading Zeros 与 Trailing Zeros 与前一个 XOR 值不同,则第 2 个 bit 值存为 '1',而后,紧跟着 5 个 bits 用来描述 Leading Zeros 的值,再用 6 个 bits 来描述有效 XOR 值的长度,最后再存储有效 XOR 值部分(这种情形下,至少产生了 13 个 bits 的冗余信息)。
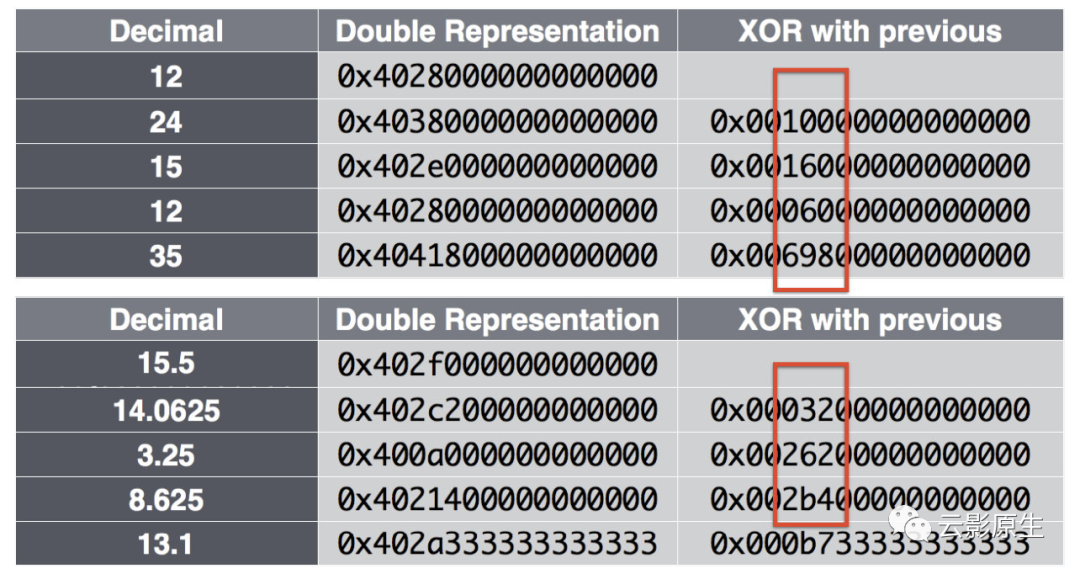
如上图所示,根据 Gorilla 论文统计,经过 XOR 编码的浮点数中有 59.06% 只占用 1 bit。
3.8 存储目录结构
TSDB 的存储路径由 Prometheus 进程的 --storage.tsdb.path
参数设置。该存储路径下的目录结构如下所示:
$ tree.├── 01F9YSXR4D6VTMX8Q4T3NT3Z24│ ├── chunks│ │ └── 000001│ ├── index│ ├── meta.json│ └── tombstones├── chunks_head│ ├── 000006│ └── 000007├── lock├── queries.active└── wal├── 00000004├── 00000005├── 00000006└── checkpoint.00000003└── 00000000复制
主要由以下部分:
block:某一时间段(默认为 2h)内的全部 sample。block 由 ULID 命名。包含以下部分:
chunks:数据文件,可能存在多个,每个 chunk 文件最大 512MiB;
index:索引文件,存储 label、series 以及 chunk 索引信息;
meta.json:block 的描述性信息,包含起始时间戳和其他统计信息,用于在查询时过滤;
tombstone:存储已删除的样本的信息。当删除样本时,tsdb 不会立即执行真正的删除操作,而是会将删除内容写入 tombstone 文件被暂时标记为删除。
chunks_head:
wal:预写日志。Prometheus 在采集当前 block 的样本时不会立即将数据落盘,而是会先将其保存在内存中。当 Prometheus 意外退出后可以通过重放预写日志来还原内存中的 sample。
TSDB 设计实现的基础就是 block,每一个 block 都存储了一个时间段内的全部指标。block 中最关键的就是 index 和 chunk 两部分 ,其中 index 为数据文件,chunk 为索引文件。
3.9 索引文件格式
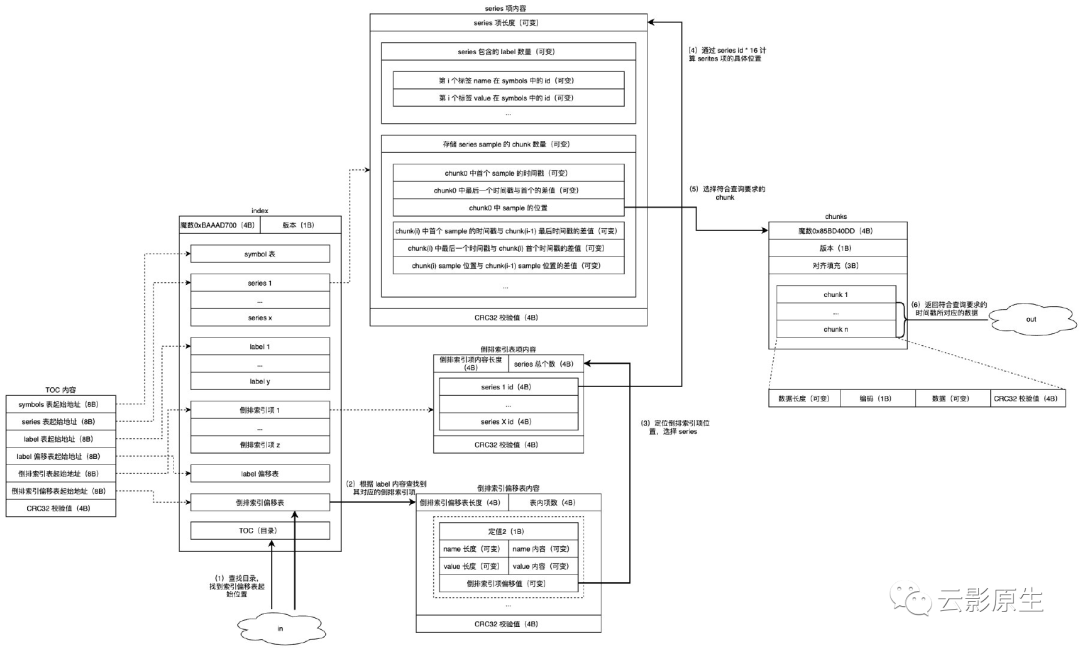
index 文件存储一个 block 内的所有索引。
index 文件按照顺序的主要组成部分(section)如下。这些部分大多数都以有效长度 len 起始,以校验值作为结尾,并会填充 0 以对齐。
symbol 表
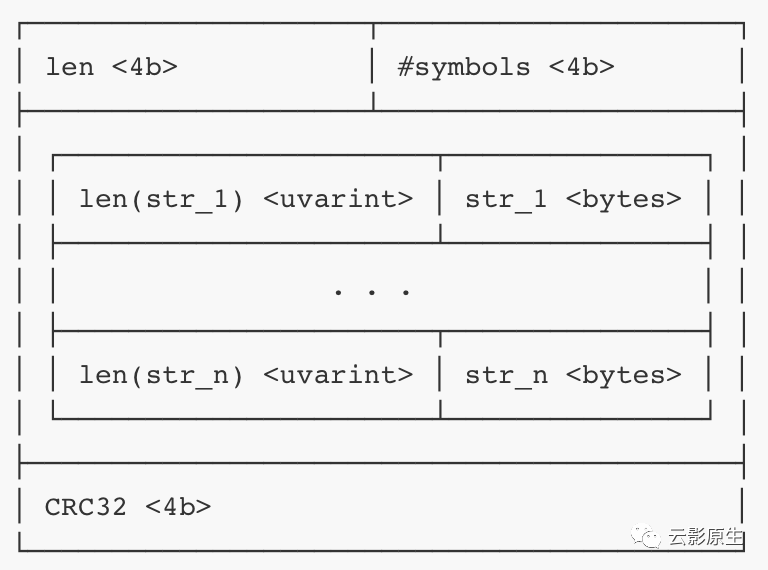
symbol 表用于存储本 block 内 series 的 label 用到的字符串,包括 label 名称和 label 值。在后续 section(除了label 和倒排索引偏移表 )中将不会直接存储字符串内容,而是转为存储字符串在 symbol 表内的序号。字符串按照字典序升序排列,并采用 UTF-8 编码。symbol 表长度不固定。
series 列表
series 列表存储了本 block 内的所有 series 的详细信息。具体来说,存储了每个 series 的 label 集合以及数据在 chunk 文件中的位置。通过 series 就可以找到数据的最终存储位置。

series 列表长度不固定。series 按照 label 集合的字典序排序。每个 series 项都按照 16 字节对齐,series 的 ID 为
文件内偏移/16
。所以可以通过 series ID 直接计算出 series 项的位置。如下图所示,每个 series 项都主要包含两个部分:
第一部分存储 label 相关内容。主要存储 label 数量,以及每个 label 的名称和值的 symbol 序号;
第二部分存储 chunk 相关内容。首先是 chunk 数量,然后是本 series 在每个 chunk 内的起始时间戳,以及数据在 chunk 内的位置。每个 series 在每个 chunk 内有且仅有一处引用位置,所以可以知道 series 在 chunk 内连续存储。
每一个 chunk 都会存储三部分内容:本 chunk 内存储的 series 内容的起始时间戳
mint
、结束时间戳maxt
、chunk 内位置。对于时间戳来说,只有第一个 chunk 项内的起始时间戳
mint(0)
会被存储为绝对时间戳,其他的时间戳都会被存储为和前一个时间戳的差值。所以第一个 chunk 的时间戳为mint(0),maxt(0)-mint(0)
,第二个 chunk 为mint(1)-maxt(0), maxt(1)-mint(1)
后续的以此类推。
label 列表
label 列表存储了本 block 内所有 label 的名称和对应的值集合。label 列表由多个 label 项连续排列组成。label 项主要记录了 label 的名称序号,label 值总数,每个 label 值的序号。其中 label 值按照字典序升序排序。

label 在调用
/api/v1/label/{name}/values
接口时会被查询,快速返回 label 对应的所有值。label 列表长度不固定,且 label 表项不存在序号,无法直接寻址。label 表项的寻址工作由 label 偏移表完成,通过查询该表就可以直接得到某个具体 label 的表项位置。
倒排索引(posting)列表
倒排索引列表保存了从 tag 到 series 的索引。tag 指 label 名称和 label 值。
以如下 3 个 series 为例
series series ID node_load1{job="node", instance="localhost"} 1 node_load1{job="node", instance="vm-x"} 2 up{job="node"} 3 会建立如下索引
tag posting job="node" 1,2,3 instance="localhost" 1 instance="vm-x" 2 __name__="node_load1" 1,2 __name__="up" 3 当查询
node_load1{job="node"}
时,会分别计算出两个 tag 的索引 {1,2} 和 {1,2,3},然后对结果取交集,就可以计算出包含所有 tag 的 series ID 为 {1,2}。倒排索引列表内的索引项格式如下。其中比较重要就是包含本 tag 的 series 数量,以及 series ID 了。series ID 按照升序排列,这样在计算多 tag 索引取交集的时候,可以将时间复杂度降低到 O(n*k) 。
通过 series ID 就可以直接计算出 series 的偏移地址,进而查询出 chunk 数据。
倒排索引列表长度不固定。和 label 类似,倒排索引表项也需要通过倒排索引偏移表来寻址。

label 偏移表
label 偏移表存储的是所有 label 项的偏移量。表项包括 label 名称长度与名称(这里不用 symbol ID)以及 label 表项偏移量。通过查询本表就可以获得 label 表项的位置。不过现已不再使用。
label 偏移表长度不固定。

倒排索引偏移表
倒排索引偏移表用于倒排索引表项的偏移量。表项包括 label 名称、label 值(这里使用的也是原始字符串而不是 symbol ID)以及倒排索引表项偏移量。偏移表会在 index 读取时部分读取到内存中。
通过比对 tag 就可以正确地获取到该 tag 对应的倒排索引项的偏移量,进而获取到包含该 tag 的 series ID,最终通过 series 读取出存放于 chunk 中的时序数据。
倒排索引偏移表长度不固定。
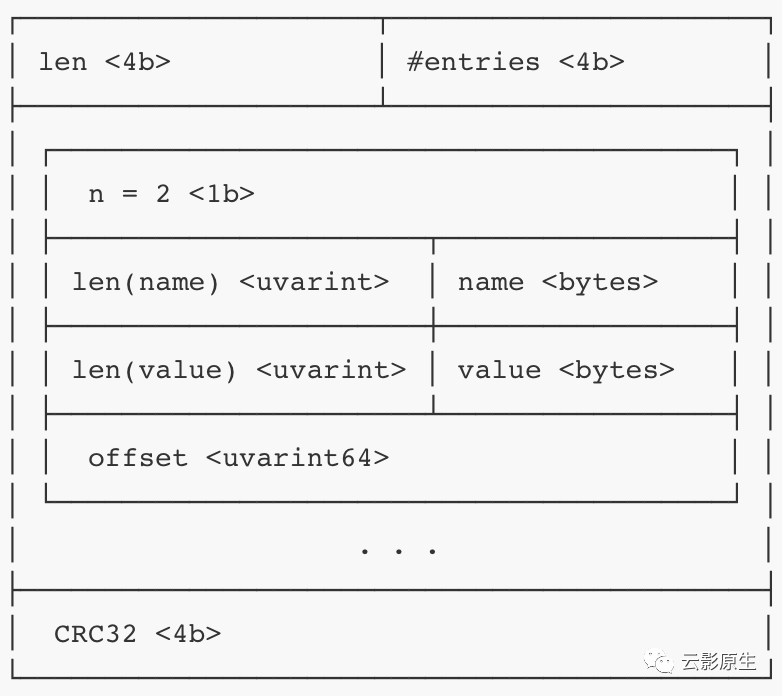
目录(TOC)
目录位于 index 文件尾部,存放的是前面各 section 的起始地址。
目录长度固定。因此在读取 index 时会首先读取目录,然后根据目录内容进一步计算各 section 起始地址。

综上所示,当进行基于 tag 的指标检索时,读取 section 顺序如下:
首先读取目录,获取倒排索引偏移表位置;
读取倒排索引偏移表,获得 tag 对应的倒排索引项的位置;
读取倒排索引列表中的索引项,获得包含该 tag 的 series ID。并对多 tag 的 series ID 集合取交集,计算同时包含所有目标 tag 的 series ID,然后根据 series ID 直接计算出 series 的地址;
读取 series 列表,获得 series 在 chunk 中的时间与位置信息;
最后读取 chunk 数据文件,获得时间范围内的样本值。
3.10 数据文件格式
其中,chunk 文件的格式如下所示。
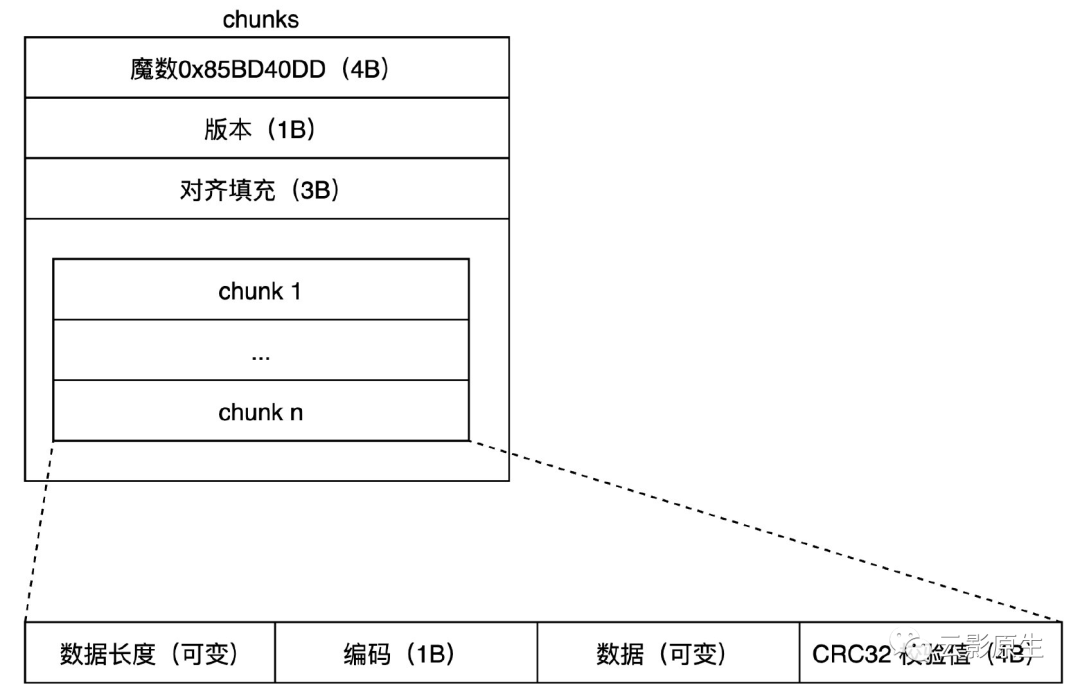
其中,魔数、版本、填充的内容是固定的。后续将会有若干 chunk 结构。
每个 chunk 对应一个 series,chunk 由长度、编码、数据和校验值组成,其中的数据就是 <timestamp, value> 也就是样本序列。当需要读取 series 对应的样本时,存储系统可以通过外部索引(index 文件)先找到样本起始位置,再通过比较样本的 timestamp 来判断是否为需要返回的数据。
同一个 block 的 chunk 会被分段存储为段文件,每段最大 512 MiB。Chunk 可以被 index 文件中的 uint64 值引用,引用值的高 4 字节便是段编号,低 4 字节表示 chunk 在文件内的偏移量。
4. InfluxDB
4.1 背景
InfluxDB 是 InfluxData 公司在 2013 年开源的时序数据库,采用 Go 语言编写。在 InfluxDB OSS 中有两种部署方式,单机版和集群版,单机版开源,在 GitHub 上有 21.8k start,集群版闭源,走商业路线。InfluxDB 在 db-engines 的时序数据库分类下 rank 1。InfluxDB 最新版为 2020 年底开始推出的 2.0 版本,该版本分为两个系列,云模式的 InfluxDB Cloud 和独立部署的 InfluxDB OSS。
在起初,InfluxDB 1.x 使用 InfluxQL 语言来操作数据。
在进入 2.0 版本之后,InfluxDB 的数据存储模式也发生了变化,存储单位由 databases 变为了 bucket,InfluxDB 推出了 Flux 语言用来操作数据。Flux 是一个独立项目,并不和 Influx 绑定。
以下分析基于 InfluxDB 2.0。
4.2 特性
读写性能高、高效存储与实时分析;
部署简单、使用方便、无系统环境依赖;
查询语句 Flux 功能强大,接口友好,使用方便,拥有丰富的聚合运算和采样能力;
无结构化多值数据模型,查询灵活;
支持多种通信协议,除了 HTTP、UDP 等原生协议外,还兼容 Graphite、OpenTSDB、Prometheus 等组件的通信协议;
丰富的权限管理功能,精细到”表“级别;
灵活的数据保留策略(Retention Policy),控制数据的保留时间和副本数;
灵活的连续查询策略(Continuous Query),离线执行查询任务并存储结果。
4.3 优势
读写、存储性能好(对比、benchmark)
4.4 集群模式
InfluxDB 开源版也就是单机版不支持集群模式,如果想要原生集群的话需要使用商业版。
除了商业版之外解决方案有如下:
InfluxDB-Relay
:官方提供的高可用层,为后端 InfluxDB 提供双写功能。不过这个项目缺乏维护,而且不提供集群必备的负载均衡功能;自研,各家都有各家的自研方案
4.5 数据格式
InfluxDB 采用 Line Protocol 格式来表示数据点:
measurement[,tag_key1=tag_value1...] field_key=field_value[,field_key2=field_value2] [timestamp]cpu_load,host_id=1 value=0.1 1434055562000000000复制
measurement:指标名;
tag_key、tag_value:存储标签键值对,会进行索引,方便查询时用于过滤条件;
field_key、field_value:存储数据,每条数据必须有一个 field-key,与 tag 类似,但是不会进行索引。
4.6 存储引擎
InfluxDB 底层的存储引擎从 LevelDB(LSM Tree),到 BoltDB(mmap B+树),到现在自己实现的基于 TSM Tree 算法的存储引擎,经历了多个版本的更替。TSM Tree 类似 LSM Tree,针对 InfluxDB 进行了特殊优化。
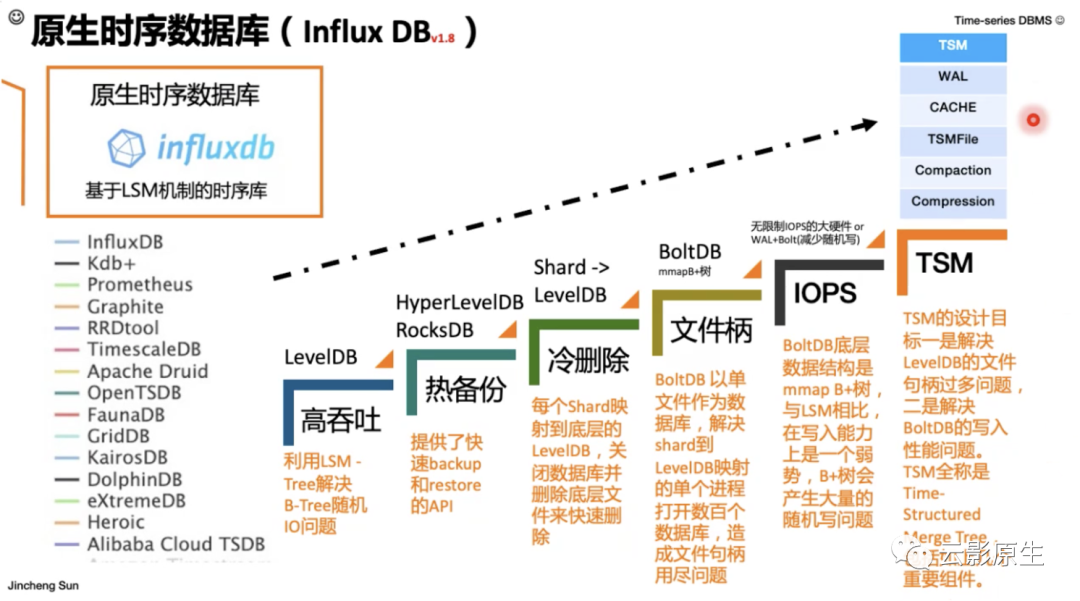
(1)组件
InfluxDB 存储主要有以下组件:
Write Ahead Log(WAL)
在写入数据点时,InfluxDB 不会将其直接写入 TSM,而是将其先保存在内存,并在 WAL 中记录,后续再批量写入 TSM。InfluxDB 启动时将会通过 WAL 来恢复内存中的数据。
WAL 被命名为
_00001.wal
的格式,文件编号单调递增,并被称为 WAL 段。当分段大小达到阈值时,该段将被关闭并重新开启一个新的分段,每个 WAL 段都存储多个压缩过的写入和删除条目。WAL 条目遵循 TLV(Type-Length-Value)标准,首先存储条目类型(写入或删除)、然后是压缩块长度,最后是压缩块内容。当一个新的数据点写入时,
首先经过压缩打包成 WAL 条目追加到 WAL 文件末尾;
然后就要更新索引,这个是加速查询的本质,包含了倒排索引内容;
然后将数据点写入内存中的 cache;
最后才将写入结果返回。
Cache
Cache 是 WAL 数据点在内存中的表现形式。WAL 存储的是压缩后的数据点条目,cache 中存储的是未压缩的数据点。当 InfluxDB 启动时可以通过 WAL 将数据点恢复到 cache 中。
当 cache 大小超过
--storage-cache-snapshot-memory-size
规定值(默认 25MiB)时会触发 cache 数据写入 TSM 文件,同时删除 WAL 段文件并清除 cache 中的数据点。当 cache 大小超过--storage-cache-max-memory-size
设定值(默认 1GiB)时将会拒绝写入请求。Time-Structured Merge Tree (TSM)
TSM 文件用于存储 series,时序以 <measurement, tag key and value, and field key> 作为标识(从这里可以看出虽然 InfluxDB 支持多 field,但是存储的时候还是单 field 存储)。
Time Series Index (TSI)
TSI 以 measurement、tag、field 为分组对 series 的 key 进行。所以 TSI 本质上也是从 measurement、tag、field 到 series 的倒排索引。通过对多个查询的 series 结果取交集,就能够计算出从哪些 TSM 文件的哪些地址开始去取数据。
(2)逻辑存储结构
InfluxDB 2.0 对逻辑存储概念进行了很大的变更,去除了 database,引入了 bucket。不过 bucket 依旧可以类比旧版本的 database,写入数据点时需要指定 bucket。
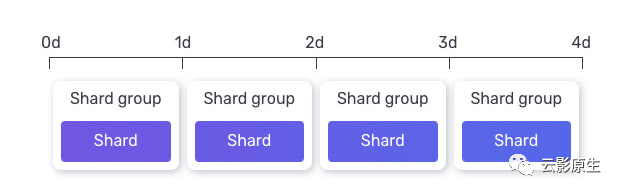
InfluxDB 2.0 按照 shard -> shard groups -> bucket 的级别来存储。
shard
属于 shard groups。一个 series 中的数据点在 shard groups 中只会存储在同一个 shard 中。一个 shard 可以包含多个 TSM 文件,只能属于唯一一个 shard groups;
shard groups
属于 bucket。用于存储 bucket 在特定时间段内的所有 series 数据点。shard groups 会根据时间来自动滚动,当超过写入周期后,会创建新的 shard groups 并写入。
默认情况下,shard groups 的周期会根据 bucket 的保留时间来自动计算,规则如下:bucker 保留时间小于 2 天则 shard groups 周期为 1h,保留时间大于 6 个月则 shard groups 周期为 7d,其他情况下 shard groups 周期为 1d。
举个栗子,一个保留时间为 4 天的 bucket 的 shard group 周期就是 1 天。
bucket
顶层 series 结构,类似 database。
4.7 存储目录结构
InfluxDB 2.0 的主要存储目录由以下参数指定:
--engine-path
:指定存储引擎目录,所有 WAL 和数据都存储在本目录,默认为/root/.influxdbv2/engine
;--bolt-path
:指定 Boltdb 数据库,Boltdb 是一个基于文件的 KV 数据库,InfluxDB 使用 Boltdb 来存储用户、dashboard 等信息。默认为/root/.influxdbv2/influxd.bolt
。
其中存储引擎目录有 2 个子目录:
# tree -L 3.├── engine│ ├── data // 存储 TSM 文件│ │ ├── 2572c690d4017577│ │ └── f6f978ef44e66af7│ └── wal // 存储 WAL 文件│ ├── 2572c690d4017577│ └── f6f978ef44e66af7└── influxd.bolt复制
5. VictoriaMetrics
5.1 背景
VictoriaMetrics 是 VictoriaMetrics 公司于 2019 年开源由 Go 语言实现的时序数据库,当前最新版本为 1.63.0,且仍在高速迭代中。VictoriaMetrics 强调自身的优点为“高效”、“经济”、“可扩展”。其中,“高效”不做过多介绍,没有一个数据库不号称自己高效。其次,“经济”指其高性能读写和低存储计算资源需求所带来的经济优势,同时 VictoriaMetrics 还因为其集群版免费且易用的优点也被不少公司采用,这也可以理解为是一种“经济”。最后“可拓展”是指 VictoriaMetrics 集群模式中的有状态组件(vmstorage
)采用 shard-nothiing 架构,可以快速无缝水平拓展。
以下分析基于 VictoriaMetrics 1.63。
5.2 特点
高性能读、高性能写、高效压缩时序数据;
集群版开源;
单值模型,仅支持浮点数指标;
独立部署,无额外依赖;
支持长期存储;
支持 Prometheus Query API,可以作为 Prometheus 型数据源在 Grafana 中直接使用;
支持多种数据源类型,包括 Prometheus 格式、Prometheus 远程写、Influx Line 协议等;
使用 MetricsQL 作为查询语言,向后兼容 PromQL;
支持多命名空间(亦称多租户)。
5.3 优势
生态协议丰富,兼容性强,支持市面上大多数指标类型的抓取;
部署使用简单;
可拓展性良好,
vmstorage
和vmselect
组件可以独立拓展到任意数量。
5.4 架构
(1)集群架构
VictoriaMetrics 分为单机版和集群版。VictoriaMetrics 集群模式架构图如下:
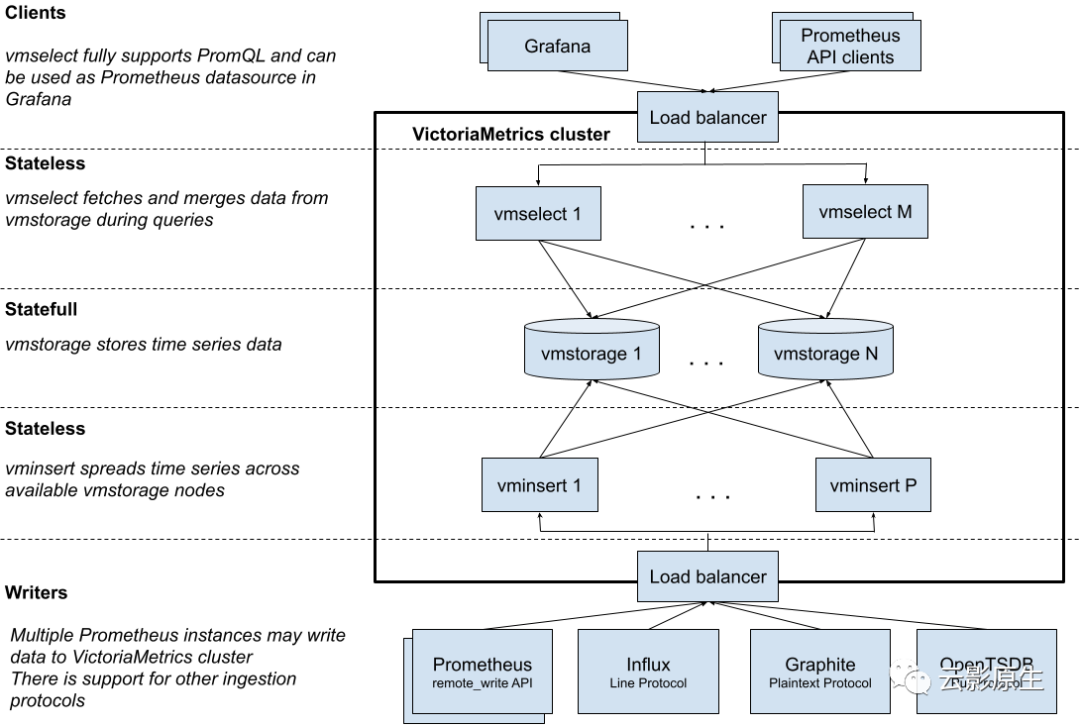
其中:
vmselect
:分发查询请求、合并后端查询结果;vmstorage
:存储时序数据。可水平拓展,多个实例间不存在共享关系;vminsert
:通过一致性哈希算法进行写入后端vmstorage
分片。可水平无缝拓展。
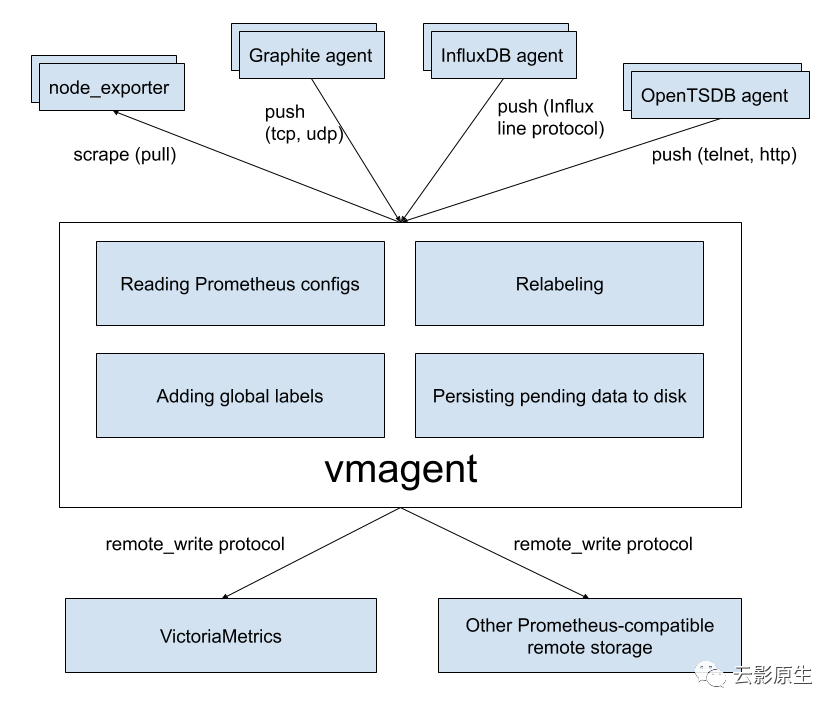
(2)vmagent
vmagent 是一个负责指标采集的模块,用于从各种数据源中采集指标并存储在 VictoriaMetrics 或其他支持 remote write 的 Prometheus 兼容存储系统。VictoriaMetrics 负责指标的存储与查询,而指标的配置、采集由 vmagent 模块来实现,也就是说 Prometheus 的指标采集与存储功能分别被划分到了 vmagent 和 VictoriaMetrics 主模块中了。将二者拆分开,更有利于采集种类的增加与采集配置的管理。
vmagent 的主要功能包括采集目标静态管理与动态发现、标签重写、指标远程写入、临时数据存储(远程存储不可用时将指标临时存入 -remoteWrite.tmpDataPath
路径中)。
vmagent 的配置文件直接参照了 Prometheus 的配置文件格式。一个可用的 Prometheus 配置文件可以直接被拿来作为 vmagent 的配置文件,只是除了 global
和 scrape_configs
段之外的配置内容都会被忽略。
如下图所示,vmagent 通常作为指标数据源和 VictoriaMetrics 间的中间组件,独立配置以适应不同的输入输出环境。
5.5 数据格式
Prometheus 规范的指标样本格式如下如所示
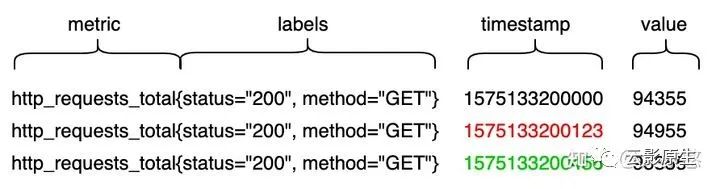
VictoriaMetrics 在采集到 Prometheus 规范指标时,会对样本格式进行转换后再建立索引和存储。首先根据 metric 名称和 label 生成全局唯一的 TSID,然后使用 metric 名称 + label + TSID 作为索引,视同 TSID + timestamp + value 作为数据,后分别以 TSID 为分组进行存储。在检索时,也是先根据 metric 名称和 label 获取 TSID,后从 TSID对应的 block 中检索出时间范围内的样本数据。

5.6 存储目录结构
VictoriaMetrics 的所有数据均存储在 --storageDataPath
参数所指定的目录中。存储目录结构如下:
# tree -L 1.├── data # 数据目录├── flock.lock # 锁├── indexdb # 索引目录├── metadata├── snapshots└── tmp复制
数据目录
进一步来说,数据目录如下所示:
# tree -L 3 data/data/├── big│ ├── 2021_07│ │ ├── tmp│ │ └── txn│ └── snapshots├── flock.lock└── small├── 2021_07│ ├── 2_2_20210719033007.000_20210719033007.000_1693137B97EAA93C│ ├── 57374_1527_20210719032831.787_20210719033511.787_1693137B97EAA979│ ├── 58552_1583_20210719033516.791_20210719034131.787_1693137B97EAA9C5│ ├── tmp│ └── txn└── snapshots复制
在 VictoriaMetrics 中,数据和索引的根目录称为 table,但实际上 VictoriaMetrics 中没有 table 级别的存储结构。
数据根目录之下有 big 和 small 两个 table 目录以及 flock.lock
锁文件。
big 和 small 目录的结构一致,都被用于存储 partition。Partition 以月为单位创建,以 yyyy-MM
格式命名。big 与 small 中的 partition 同时创建,文件名对应。
在 partition 目录下,有 part 目录、tmp 临时目录、txn 事务目录。
VictoriaMetrics 没有 WAL 机制,最近时间段内的数据只保存在内存中?。内存中的指标数据每落盘一次,就会生成一个对应的 part 目录。Part 目录以 rowsCount_blocksCount_minTime_maxTime_suffix
格式命名:rowsCount 表示 part 目录中的指标条数,blocksCount 表示目录中的数据块数,minTime/maxTime 表示目录中数据的最小最大时间戳,suffix 表示创建本 part 目录时的系统纳秒级时间戳的 16 进制表示。
上图中的 57374_1527_20210719032831.787_20210719033511.787_1693137B97EAA979
目录表示 part 中包含 57374 条指标,保存在 1527 个数据块,时间范围是 2021-07-19 03:28:31 到 2021-07-19 03:35:11,创建 part 的时间是 1626665311961524601纳秒即 2021-07-19 11:28:31 (UTC+8)。
在 VictoriaMetrics 中,指标会被先写入到 small 目录的 partition 中,每个 partition 最多包含 256 个 part。
big 和 small 中的数据都会被定时检查是否需要被合并压缩。默认每 10ms 检查一次,如果有需要则会进行合并,否则以 10ms 的指数次方来等待下一次检查,等待时间上限 10s。每次最多合并 10 个 part。每个 part 最多包含 1000w 行数据,当合并后的 part 超过上限时,合并后的 part 会被存放在 big 目录中,并采取比 small 更高级的 ZSTD 压缩级别,而 small 目录使用的则是较低级别的 ZSTD 压缩。
5.7 索引文件格式
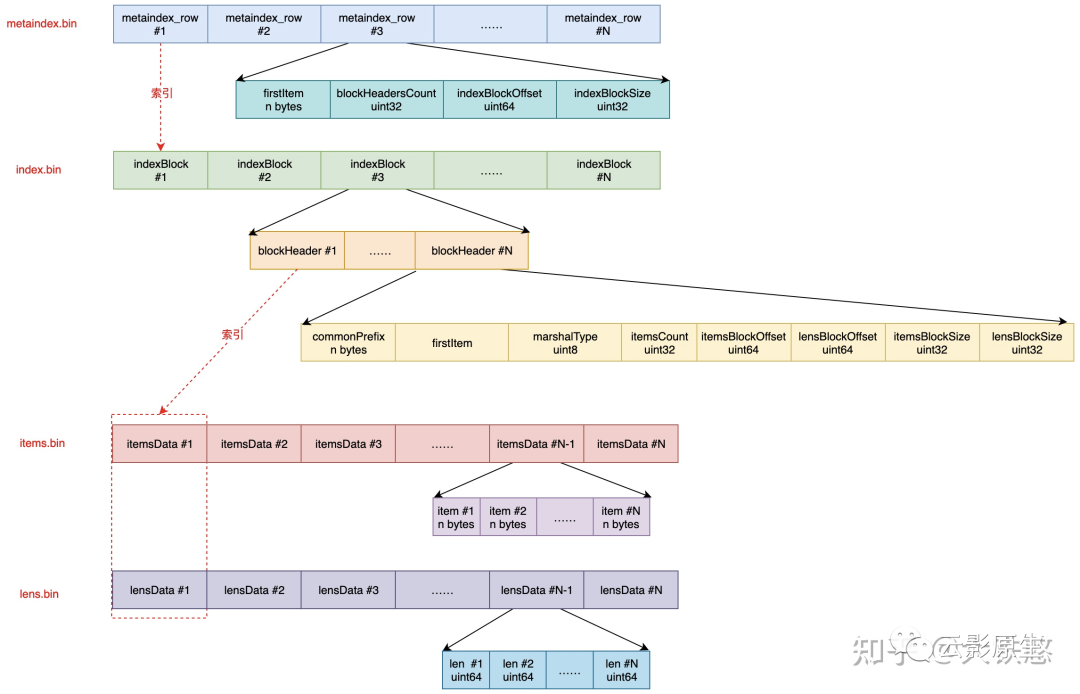
VictoriaMetrics 在每次落盘或者 part 合并时都需要创建新的 part 索引,索引目录包含 5 个文件。文件夹索引结构和跳表类似:
metadata.json:索引描述文件,包含 item 数量、block 数量等信息;
metaindex.bin:包含 metaindex_row,通过 metaindex_row 索引 index.bin 文件;
index.bin:包含 indexBlock,通过 IndexBlock 同时索引 lens.bin 和 items.bin 文件;
items.bin:存储 item;
lens.bin:与 items.bin 对应,便是对应的 item 长度。
说了这么多,我们其实一直绕过了一个定义——item。Item 是索引的载体,本质是一种 KV 结构的字节数组,VictoriaMetrics 有 7 种索引,所以 item 也有 7 种类型。Item 存储在 items.bin 文件中,item 以字节序列表示,不同类型的 item 以不同前缀来区分。
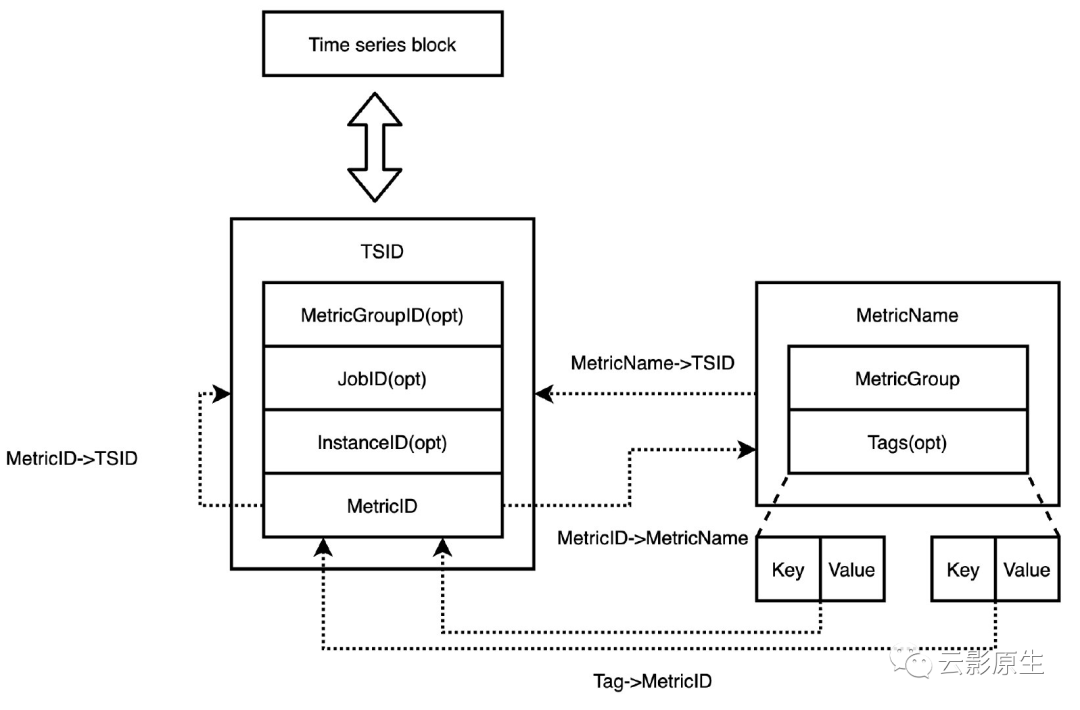
// MetricName reperesents a metric name.type MetricName struct {MetricGroup []byte// Tags are optional. They must be sorted by tag Key for canonical view.// Use sortTags method.Tags []Tag}复制
其中,Tags 是字节 KV 数组,VictoriaMetrics 在处理时会特别把指标 label 中的 job 和 instance 放在 Tags 数组的前两位。
根据 MetricName 可以生成指标名对应的 TSID,TSID 结构体如下所示:
type TSID struct {MetricGroupID uint64JobID uint32InstanceID uint32MetricID uint64}复制
其中:
MetricGroupID 根据 MetricName 中的 MetricGroup 取摘要生成;
JobID 和 InstanceID 根据 MetricName 中 Tags 前 2 个 tag 取摘要生成;
MetricID 使用 VictoriaMetrics 启动时的纳秒时间戳自增生成。
TSID 中只有 MetricID 是必备的,所以 TSID 中的标识信息其实只有 MetricID。所以指标 tag 的倒排索引的对象是 TSID 中的 MetricID。
以写入 http_requests_total{status="200", method="GET"}
为例,则 MetricName
为 http_requests_total{status="200", method="GET"}
, 假设生成的 TSID 为 {metricGroupID=0, jobID=0, instanceID=0, metricID=51106185174286}
,则 VictoriaMetrics
在写入时就构建了如下几种类型的索引 item,其他类型的索引 item 是在后台或者查询时构建的。
metricName -> TSID, 即
http_requests_total{status="200", method="GET"}
->{metricGroupID=0, jobID=0, instanceID=0, metricID=51106185174286}metricID -> metricName,即
51106185174286 -> http_requests_total{status="200", method="GET"}metricID -> TSID,即
51106185174286 -> {metricGroupID=0, jobID=0, instanceID=0, metricID=51106185174286}tag -> metricID,即
status="200" -> 51106185174286
,method="GET" -> 51106185174286
,"" = http_requests_total -> 51106185174286有了这些索引的 item 后,就可以支持基于 tag 的多维检索了,在当给定查询条件
http_requests_total{status="200"}
时,VictoriaMetrics 先根据给定的tag条件,找出每个 tag 的 MetricID 列表,然后求所有 tag 的 MetricID 列表的交集,然后根据交集中的 MetricID,再到索引文件中检索出 TSID,根据 TSID 就可以到数据文件中查询数据了,在返回结果之前,再根据 TSID 中的 MetricID,到索引文件中检索出对应的写入时的原始 MetircName。
回到 part 内索引文件,除去 metadata.json 文件外,metaindex.bin、index.bin、lens.bin、items.bin 四个文件总体来说是从上到下索引的关系,文件内有序,使用二分查找提升效率,找到下一级索引后,继续进入下一级文件进行二分查找。
具体来讲:
metaindex.bin:由 metaindex_row 组成,metaindex_row 包含 firstItem、blockHeadersCount、indexBlockOffset、indexBlockSize。
metaindex.bin 文件使用 ZSTD 进行压缩。metaindex_row 按照 firstItem 的大小进行字典序排序,以支持二分检索。当 part 打开时,metaindex.bin 会全部读入内存以快速查找。
firstItem 表示 metaindex_row 指向的 indexBlock 中最小 item;
blockHeadersCount 表示 metaindex_row 指向的 indexBlock 中 blockHeader 的数量;
indexBlockOffset 表示指向的 indexBlock 在 index.bin 中的偏移量;
indexBlockSize 表示指向的 indexBlock 大小。
index.bin:有 indexBlock 组成,indexBlock 包含一系列 blockHeader,blockHeader 包含 commonPrefix、firstItem、itemsCount、itemsBlockOffset、lensBlockOffset、itemsBlockSize、lensBlockSize。
index.bin 文件使用 ZSTD 进行压缩。index.bin 也是根据 indexBlock 中的 firstItem 有序存储,二分查找。
commonPrefix 表示 item 的公共前缀,item 在存储时将会去除公共前缀后存储;
firstItem 表示 indexBlock 指向的地址中最小 item;
itemsCount 表示 indexBlock 指向的地址范围中的 item 数量;
itemsBlockOffset、lensBlockOffset、itemsBlockSize、lensBlockSize 表示 item 和 item 长度的文件内起始地址和长度。
items.bin:由 itemsData 组成,每个 itemsData 中都包含若干个 item。每个 itemsData 都长度不定,其长度保存在 lens.bin 文件中,index.bin 文件可以同时索引到 itemsData 首地址及其长度,因此可以准确地计算出 itemsData 的范围。items.bin 根据情况判断是否使用 ZSTD 压缩;
lens.bin:由 lensData 组成,每个 lensData 包含若干个 8 字节的 len,与 items.bin 中 itemsData 包含的 item 一一对应。
5.8 数据文件格式
VictoriaMetrics 在每次落盘或者 part 合并时都需要创建新的 part 数据目录,数据目录包含 4 个文件:
metaindex.bin:包含 metaindex_row,以 metaindex_row 索引 index.bin 文件;
index.bin:包含 indexBlock,以 indexBlock 同时索引 timestamps.bin 和 values.bin 文件;
timestamps.bin:存储样本点时间戳;
values.bin:存储样本值,与 timestamps.bin 对应。
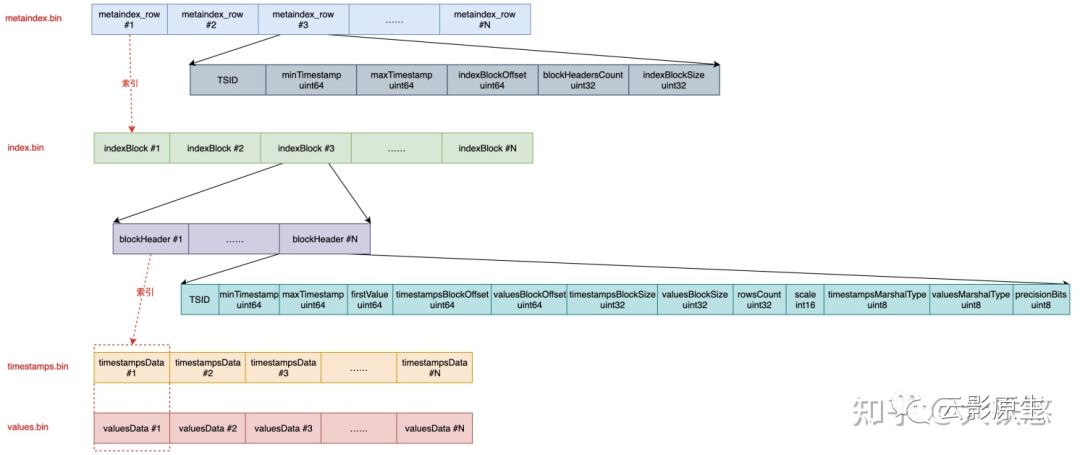
具体来说:
metaindex.bin:由 metaindex_row 组成,metaindex_row 包含 TSID、minTimestamp、maxTimestamp、indexBlockOffset、indexBlockSize。
与索引目录中的 metaindex.bin 类似,数据目录中的 metaindex.bin 依旧是按照 TSID 字典序排序,二分查找,ZSTD 压缩,读入内存。
TSID:标识本 metaindex_row 所指向的 indexBlock 中的 blockHeader 的最小 TSID;
minTimestamp/maxTimestamp:目标指标序列的范围时间戳;
indexBlockOffset:在 index.bin 中的对应 indexBlock 文件内偏移量,也就是起始地址;
indexBlockSize:在 index.bin 中的对应 indexBlock 长度。
index.bin:由 indexBlock 组成,indexBlock 包含一系列 blockHeader,blockHeader 包含 TSID、minTimestamp、maxTimestamp、firstValue、TimestampBlockOffset、valuesBlockOffset 等内容。
indexBlock 采用 ZSTD 算法进行压缩。查找时,在 indexBlock 内线性遍历 blockHeader 查找 TSID。
TSID:指向的指标序列的 TSID;
min/maxTimesamp:指向的指标序列的范围时间戳;
firstValue:indexBlock 指向区块的第一个值;
timestampsBlockOffset:指标序列在 timestamps.bin 中的起始地址;
valuesBlockOffset:指标序列在 values.bin 中的起始地址;
timestamps.bin:包含一系列时间戳压缩块 timestampsData。会根据时序数据特征进行压缩,整体上的压缩思路是:先做时序压缩,然后再做通用压缩。比如,先做 delta-of-delta 计算或者异或计算,然后根据情况做 Zig-zag,最后再根据情况做一次ZSTD压缩;
values.bin:包含的一系列指标值压缩块 valuesData,也会压缩,方式与 timestamps.bin 类似。
6. 最佳实践
指标的指标设计可以拆解为指标名与标签两个部分分别讨论。
(1)监控项选择
首先是指标名的部分,在设计指标名之前,我们需要先选取采集对象。
我们经常会提到系统监控的 4 个黄金指标:
延迟:服务请求的时间。反应用户体验;
通讯量:当前流量,用于衡量服务的容量需求。反映系统的服务量;
错误:系统中的所有错误数,衡量当前系统的稳定性。帮助发现和定位故障;
饱和度:影响服务质量的受限资源的使用率,用来衡量当前当前及未来的服务稳定性。反映系统的饱和度负载。
此外还有一种指标的选取角度。从系统类别出发选择指标:
线上系统:主要有请求量、错误量、服务时延等;
线下系统:主要有当前任务数统计、工作队列长度等;
批处理作业:任务数统计,作业各阶段耗时等;
除了系统本身,有时还需监控子系统:
库(Libraries): 调用次数,成功数,出错数,调用的时延;
日志(Logging):计数每一条写入的日志,从而可找到每条日志发生的频率和时间;
Failures: 错误计数;
线程池:排队的请求数,正在使用的线程数,总线程数,耗时,正在处理的任务数等;
缓存:请求数,命中数,总时延等;
...
(2)指标命名
准确;
需要符合 pattern
[a-zA-Z_:][a-zA-Z0-9_:]*
;应该包含一个单词作为前缀,表明这个指标所属的域。如:
prometheus_notifications_total(Prometheus 指标)
process_cpu_seconds_total(进程指标)
http_request_duration_seconds(HTTP 指标)
应该包含一个单位的单位作为后缀,表明这个指标的单位。如:
http_request_duration_seconds
node_memory_usage_bytes
http_requests_total (无单位时使用 total)
process_cpu_seconds_total (累计值也可以使用 total)
尽量使用基本单位,如 seconds,bytes。而不是 milliseconds、megabytes。
(3)标签选取
对于一个资源对象的不同操作,如 read/write、send/receive, 应采用不同的指标去记录,而不要放在一个指标里,原因是监控时一般不会对这两者做聚合,而是分别去观测。除此之外,就可以将常用于聚合的分类信息放到标签中,比如 API 的 method 等。
文末声明
本文 InfluxDB 章节部分图表来自 时序数据库随笔:综述篇;
本文 VictoriaMetrics 章节部分图表来自 https://zhuanlan.zhihu.com/p/368912946。
如有侵权请告知,将立即删除。
点个在看你最好看
评论

 0 点赞 0 点赞
0 点赞 0 点赞