




每一个工具人都是一个齿轮,他们有大有小,缺一不可;
健康的环境下,这些齿轮彼此依靠、共同承压、互为备份,推动团队不断地运转、逐步前进。
失控的环境中,无人给齿轮加油;随着不断地压榨,小齿轮一个接着一个磨损,最后只剩大齿轮苦苦支撑,慢慢生锈。当这个大齿轮出现单点故障时,整个团队就会出现雪崩。
Flink也是一个由很多组件一起运作的集群,其中一些重要的组件,比如:jobMaster,ResourceManager,Dispatcher等都受到了高可用的保护。Flink中主要使用了CuratorFramework 作为基于Zookeeper的选举与监听。
一,我们以JobMaster为例,看下Flink是如何实现的:
JobMasterServiceLeadershipRunner.class
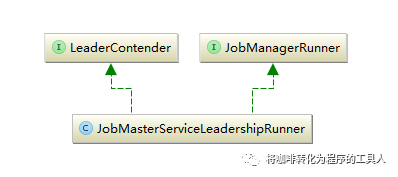
JobMasterServiceLeadershipRunner.class 实现了两个接口,
其中LeaderContender接口主要在leader选举中使用,代表了参与leader竞争的角色,其实现类有JobMasterServiceLeadershipRunner、ResourceManager、DefaultDispatcherRunner、WebMonitorEndpoint,该接口中包含了两个重要的方法:
1. grantLeadership,表示leader竞选成功的回调方法
2. revokeLeadership,表示由leader变为非leader的回调方法
而JobManagerRunner中的接口负责Job的生命周期相关的服务,如启动一个JobMaster,并在启动时,将自身作为竞争者,传递给了leaderElectionService。
@Overridepublic void start() throws Exception {LOG.debug("Start leadership runner for job {}.", getJobID());leaderElectionService.start(this);}
leaderElectionService的实现类是DefaultleaderElectionService,它是Leader选举服务的实现类,它也有两个接口服务。
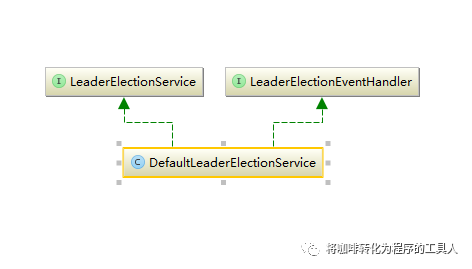
LeaderElectionService主要提供了参与选举竞争的接口调用以及竞争结果的查询接口:
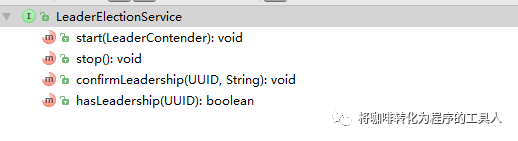
LeaderElectionEventHandler主要负责Leader变化后的响应行为。
在开始参加Leader选举时(DefaultleaderElectionService::start ),会通过选举驱动器工厂创建一个leaderElectionDriver,通过这个Driver工厂类,Flink将基于zookeeper的CuratorFramework的细节,与Flink本身做了解耦(这应该最近的版本做的改动,工具人看的是1.13版本的)。
并将自身作为一个LeaderElectionEventHandler传入leaderElectionDriver。
@Overridepublic final void start(LeaderContender contender) throws Exception {checkNotNull(contender, "Contender must not be null.");Preconditions.checkState(leaderContender == null, "Contender was already set.");synchronized (lock) {leaderContender = contender;leaderElectionDriver =leaderElectionDriverFactory.createLeaderElectionDriver(this,new LeaderElectionFatalErrorHandler(),leaderContender.getDescription());LOG.info("Starting DefaultLeaderElectionService with {}.", leaderElectionDriver);running = true;}}
ZooKeeperLeaderElectionDriver是一个LeaderLatchListener,选举成功会调用isLeader方法,由leader变为非leader调用notLeader方法;并且还同时是NodeCacheListener,要通过NodeCache方式添加了监控当前节点变化,当监听的节点发生变化时,则调用nodeChanged方法。
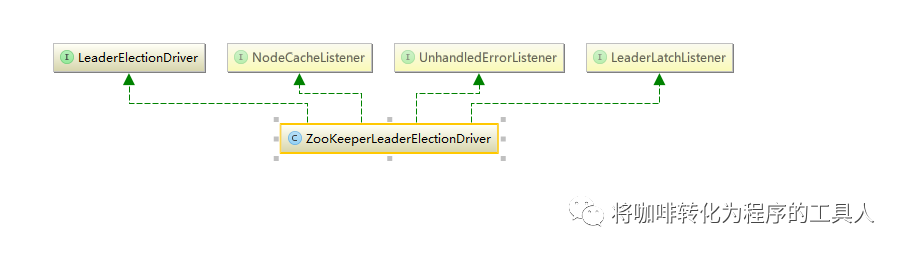
ZooKeeperLeaderElectionDriver在构造时,启动了curator框架的leaderLatch和NodeCache。
public ZooKeeperLeaderElectionDriver(CuratorFramework client,String latchPath,String leaderPath,LeaderElectionEventHandler leaderElectionEventHandler,FatalErrorHandler fatalErrorHandler,String leaderContenderDescription)throws Exception {this.client = checkNotNull(client);this.leaderPath = checkNotNull(leaderPath);this.leaderElectionEventHandler = checkNotNull(leaderElectionEventHandler);this.fatalErrorHandler = checkNotNull(fatalErrorHandler);this.leaderContenderDescription = checkNotNull(leaderContenderDescription);leaderLatch = new LeaderLatch(client, checkNotNull(latchPath));cache = new NodeCache(client, leaderPath);client.getUnhandledErrorListenable().addListener(this);running = true;leaderLatch.addListener(this);leaderLatch.start();cache.getListenable().addListener(this);cache.start();client.getConnectionStateListenable().addListener(listener);}
选举成功后,一层一层回调用DefaultLeaderElectionService:
@Overridepublic void isLeader() {leaderElectionEventHandler.onGrantLeadership();}
DefaultLeaderElectionService响应选举成功,回调leaderContender.grantLeadership:
@Override@GuardedBy("lock")public void onGrantLeadership() {synchronized (lock) {if (running) {issuedLeaderSessionID = UUID.randomUUID();clearConfirmedLeaderInformation();if (LOG.isDebugEnabled()) {LOG.debug("Grant leadership to contender {} with session ID {}.",leaderContender.getDescription(),issuedLeaderSessionID);}leaderContender.grantLeadership(issuedLeaderSessionID);} else {if (LOG.isDebugEnabled()) {LOG.debug("Ignoring the grant leadership notification since the {} has "+ "already been closed.",leaderElectionDriver);}}}}
JobMasterServiceLeadershipRunner响应选举成功后,启动JobMaster。
@Overridepublic void grantLeadership(UUID leaderSessionID) {runIfStateRunning(() -> startJobMasterServiceProcessAsync(leaderSessionID),"starting a new JobMasterServiceProcess");}
这里做下小小的科普:在curatorFramework中,有两种选举模式:一种是使用LeaderSelector接口,这种方式在每个实例在获取领导权后,如果 takeLeadership(CuratorFramework client) 方法执行结束,将会释放其领导权,第二种方式就是Flink使用的LeaderLatch,获取领导权的节点在调用close之前会一直拥有领导权,所以更适合于Flink的运作场景。
二,对于TaskExecutor来说,同样需要监听zookeeper的变化,来感知到JobMaster是否主从切换。
在TaskExecutor中包含了一个JobLeaderService的对象属性jobLeaderService,在jobLeaderService中维护了所有的jobmaster leader,并且监听它,监听正是通过ZooKeeperLeaderRetrievalService完成。TaskExecutor在申请slot时会调用requestSlot方法,在该方法里面调用jobLeaderService.add方法,启动了leader寻回服务。
JobLeaderService.class
public void addJob(final JobID jobId, final String defaultTargetAddress) throws Exception {Preconditions.checkState(JobLeaderService.State.STARTED == state, "The service is currently not running.");LOG.info("Add job {} for job leader monitoring.", jobId);final LeaderRetrievalService leaderRetrievalService = highAvailabilityServices.getJobManagerLeaderRetriever(jobId,defaultTargetAddress);JobLeaderService.JobManagerLeaderListener jobManagerLeaderListener = new JobManagerLeaderListener(jobId);final Tuple2<LeaderRetrievalService, JobManagerLeaderListener> oldEntry = jobLeaderServices.put(jobId, Tuple2.of(leaderRetrievalService, jobManagerLeaderListener));if (oldEntry != null) {oldEntry.f0.stop();oldEntry.f1.stop();}leaderRetrievalService.start(jobManagerLeaderListener);}
ZooKeeperLeaderRetrievalService同样继承了curatorFramework的NodeCacheListener,并在启动时注册回调监听
@Overridepublic void start(LeaderRetrievalListener listener) throws Exception {Preconditions.checkNotNull(listener, "Listener must not be null.");Preconditions.checkState(leaderListener == null, "ZooKeeperLeaderRetrievalService can " +"only be started once.");LOG.info("Starting ZooKeeperLeaderRetrievalService {}.", retrievalPath);synchronized (lock) {leaderListener = listener;client.getUnhandledErrorListenable().addListener(this);cache.getListenable().addListener(this);cache.start();client.getConnectionStateListenable().addListener(connectionStateListener);running = true;}}
当JobMaster节点发生变化时,nodeChanged函数就会被回调,
@Overridepublic void nodeChanged() throws Exception {synchronized (lock) {if (running) {try {LOG.debug("Leader node has changed.");.............if (!(Objects.equals(leaderAddress, lastLeaderAddress) &&Objects.equals(leaderSessionID, lastLeaderSessionID))) {lastLeaderAddress = leaderAddress;lastLeaderSessionID = leaderSessionID;//核心逻辑leaderListener.notifyLeaderAddress(leaderAddress, leaderSessionID);}} catch (Exception e) {leaderListener.handleError(new Exception("Could not handle node changed event.", e));throw e;}} else {LOG.debug("Ignoring node change notification since the service has already been stopped.");}}}
其中的JobLeaderService.JobManagerLeaderListener.notifyLeaderAddress将会被执行,其主要职责是与新的JobMaster建立连接rpcConnection。
好了今天的学习就到这里,最后,希望所有的工具人,不要学三国杀中的黄盖,为了不给桃的主公,寻找虚无缥缈的诸葛连弩,鞭挞自己,苦肉到死,流血而亡。
