




现如今,软件交付的效率和质量成了当今企业的核心竞争力和核心价值,但是仍然存在很多公司还在以一种手工作坊的方式开发软件,引用别的文章中看到的一句话“工业革命虽然消灭了绝大多数的手工业群体,却催生了程序员这个现存量最大的手工业群体”。这句话有点夸张,但从侧面也反映出这种手工模式的存在,往往也伴随着大量的效率问题。
如何能提高软件交付的效率呢?
就不得不提到DevOps理念了,它的想法是一切软件交付过程中的手工环节,都是未来可以优化的方向。DevOps这个词,它是来自于Development和Operations的组合词,但是其内容不仅仅涉及到这两个领域。从开发到运维,中间还存在测试环节,因此,把DevOps看作开发、技术运营和质量保障(QA)三者的交集可能更为准确。
于是,一系列基于DevOps理念的自动化工具串联起整个产品的生命周期,从开发,提交代码,构建,测试,到最终发布都能够快速,且高效地通过自动化的方式完成,避免一些琐碎的沟通和手工操作。
现在市面上有许多devops的工具,它们主要可以分为以下几类:
开发和构建工具
自动化测试工具
部署工具
运行时 DevOps 工具
协作 DevOps 工具
而持续集成(CI)则是DevOps理念和方法论的其中一种实践。
CI 从字面意思上看,就是帮助开发人员能够持续不断地频繁地合并新代码,并及时发现新代码引入的冲突和bug。
举个例子,在CI日常实践中,一旦开发人员对应用所做的更改被合并(每次push or 发起merge request),系统就会通过自动构建应用并运行不同级别的自动化测试(通常是单元测试和集成测试)来验证这些更改,确保这些更改没有对应用造成破坏,这样持续不断地发现问题并解决问题,大大提高了产品的交付效率,也保证了产品的质量。
一条测试的CI流水线通常如下图那样:
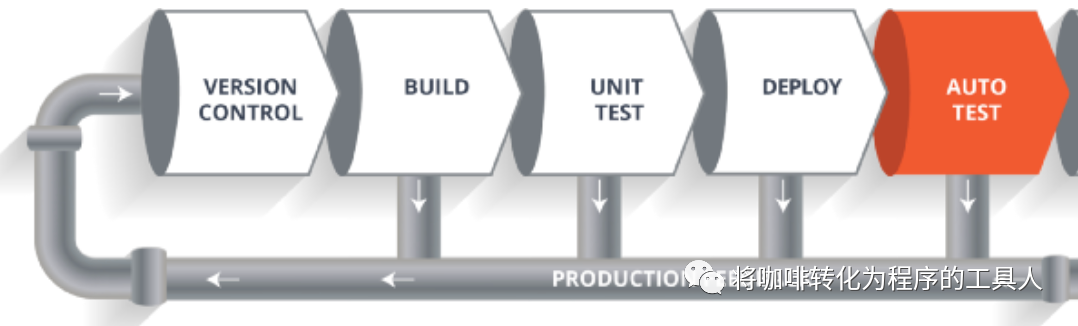
例如:从git上获取到更改的代码->构建->进行mock的单元测试->部署到指定的CI环境->运行自动化测试用例。
基于docker实现的CI流水线如下图:
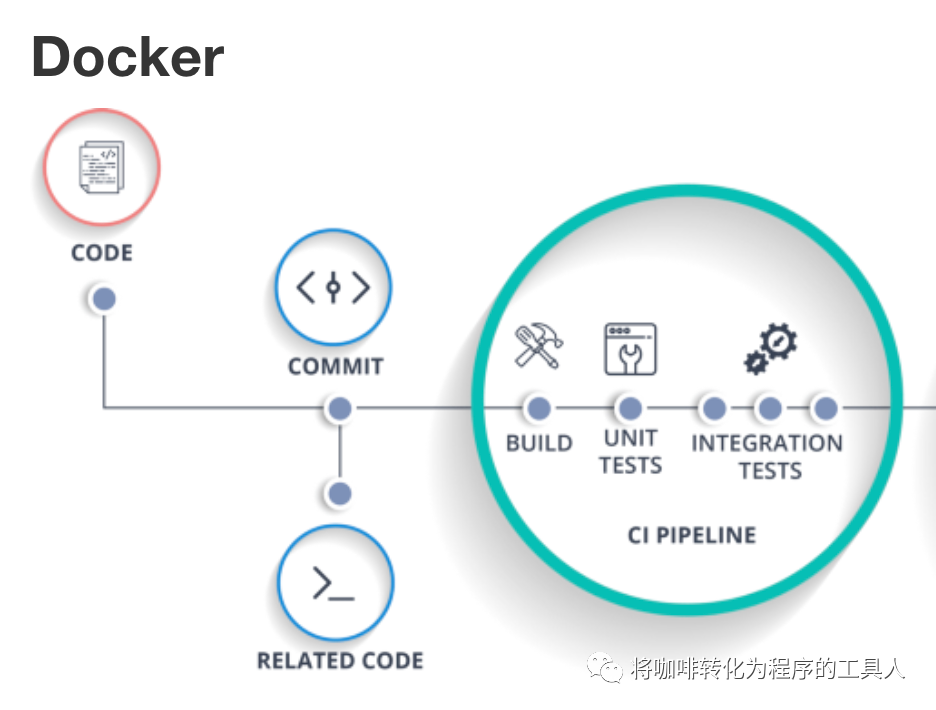
像工具美眉这样的测试开发,日常的工作之一就是维护CI流水线中很重要的保证质量的环节——自动化测试。我们会将自动化测试分成很多种类,应用于不同的流水线,例如:冒烟测试的用例应用于日常的探活流水线,回归测试的用例应用于代码merge以后的回归流水线等等。
显然对testcase的管理显得比较重要了,因为我们要在不同的流水线中运行不同职责的自动化测试代码,在一个探活的流水线中,运行全量的测试用例显然很不合理,耗时也很长,反而起不到快速的效果。
那我们如何在pytest框架中,指定不去运行那些不是主流程又运行很慢的case呢?
一种简单粗暴的方式,在testcase上加上slow的标签:
def test_case1():time.sleep(2)pass@pytest.mark.slowdef test_case2():time.sleep(5)pass@pytest.mark.slowdef test_case3():time.sleep(4)pass复制
在conftest.py中,通过pytest_collection_modifyitems hook和pytest_deselected hook 对case进行过滤。
def pytest_collection_modifyitems(items, config):selected_items = []deselected_items = []for item in items:if item.get_closest_marker("slow"):deselected_items.append(item)else:selected_items.append(item)config.hook.pytest_deselected(items=deselected_items)items[:] = selected_items复制
如果没有打上slow标签的case不会被执行,实际运行的只有1个testcase,被打了slow标签的case被deselected了。pytest_collection_modifyitems 这个hook,会在收集完所有testcase ,逐一运行之前调用,通常可以通过这个hook方法对testcase进行一些过滤或顺序调整,通过遍历这个hook的参数items对象,可以拿到所有的testcase对象的属性。
这种实现比较简单粗暴,事实上,我们并不知道哪些case耗时较长,一个个加上slow标签又很费劲,有没有办法,利用程序自己对testcase的耗时做个统计,当运行时长超过某个阈值时,则给这个case 打上slow的标签,下次再运行时,就可以根据标签进行过滤了。
于是,我们可以大概的设计按以下的流程图:
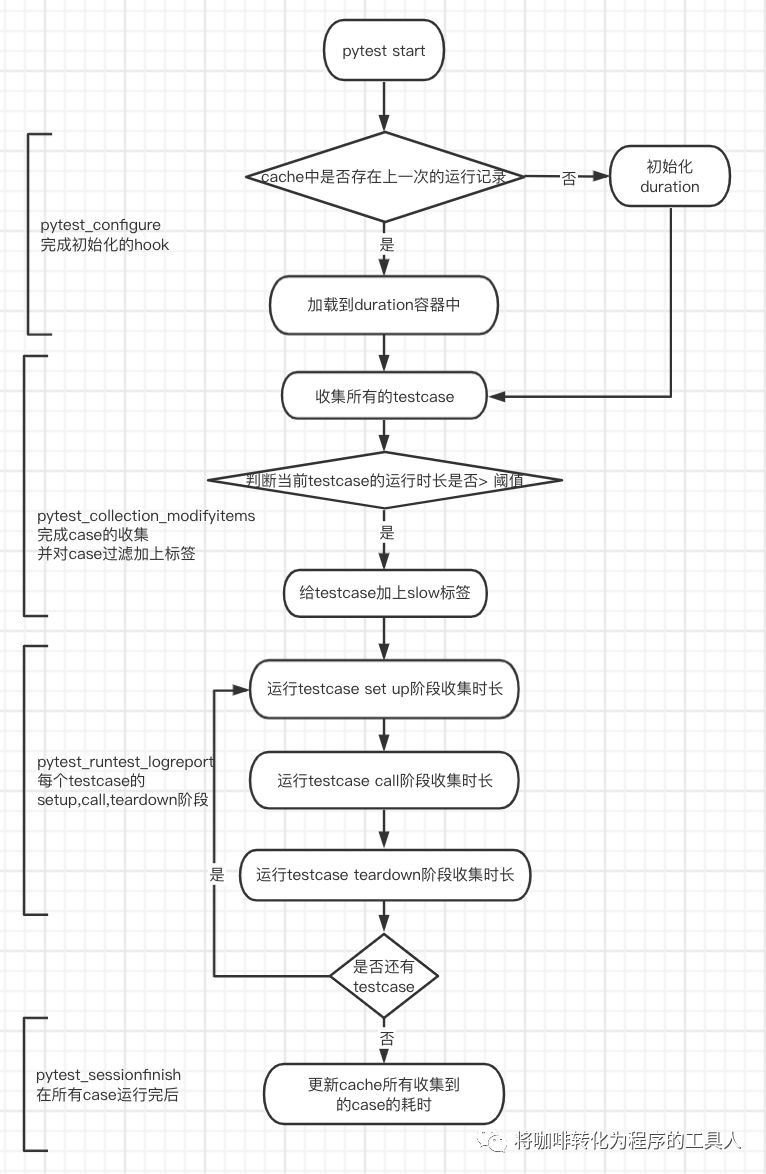
大致思路有了,赶紧给conftest.py做个修改:
#一个全局用于存放运行时长的容器durations = defaultdict(dict)#设置运行时长阈值 = 3 秒slow = 3.0#初始化durations容器,如果上一次运行结果已经保存在cache中,#则从cache中加载def pytest_configure(config):durations.update(config.cache.get("cache/case_duration", defaultdict(dict)))#每个testcase运行过程中的运行时长收集#每个testcase的 setup,call,teardown阶段都会进入该方法#三个阶段的duration都会存放到durations容器中def pytest_runtest_logreport(report):durations[report.nodeid][report.when] = report.duration#统计每个testcase setup,call,teardown三个阶段的运行总时长#跟阈值作比较,大于阈值,认为该case是slow的#给slow的case加上标签@pytest.mark.tryfirstdef pytest_collection_modifyitems( session, config, items):for item in items:duration = sum(durations[item.nodeid].values())if duration > slow:item.add_marker(pytest.mark.slow)#在所有case运行完后,更新cache的duration为本次最新的结果def pytest_sessionfinish(session):session.config.cache.set("cache/case_duration", durations)复制
现在可以通过pytest -m 指定运行一下slow的case试试
pytest test_case.py -m slow复制
我们在cache的目录下看到了一个case_duration的文件,记录了三个testcase分别的运行时长。
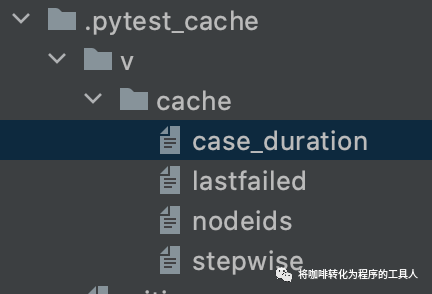
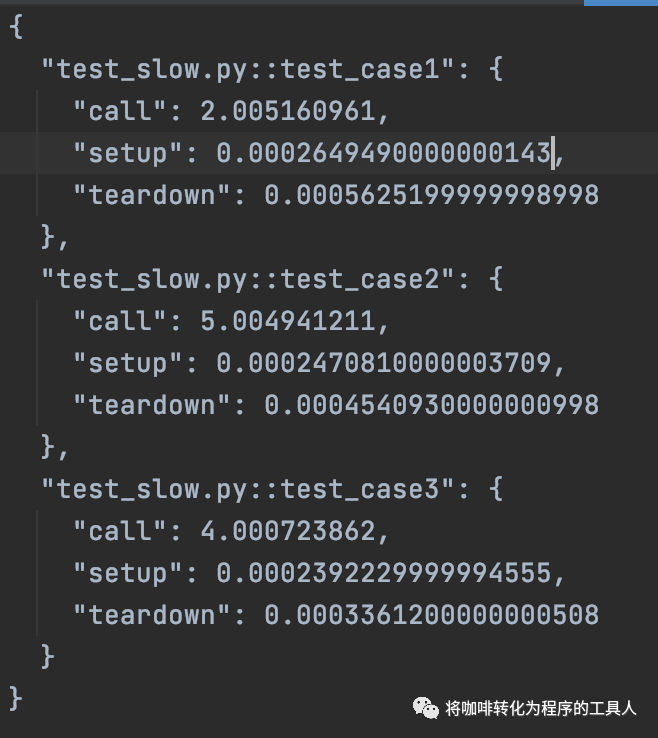
当我们把slow的阈值设置为3秒时,可以看到只有一个test_case1不会被加上slow的标签。因此只运行slow标签的case时,只有一个case被deselected了。

总结一下,今天学习的几个hook方法:
pytest_configure
pytest_runtest_logreport
pytest_collection_modifyitems
pytest_sessionfinish
今天的学习就到这里,如果这篇文章对你有帮助,记得点赞和转发哦👍
