




大家好,我是飓风。
今天咱们来聊聊redis 的数据类型。
我们以问答的方式来开始今天的知识。
角色介绍:
小明 => 学生
飓风 => 老师
小明正在上大二,是个勤奋努力的小伙,最近正在学习redis相关的知识,官网、博客文章全部搜罗一遍,感觉自己信心满满,于是便去找了飓风老师讨教一番。
小明兴致勃勃的来到老师办公室。
小明:飓风老师,我最近学习了redis,redis 真的太强大了,数据类型丰富,能够适应我很多应用场景。
飓风:小孩子不要太骄傲,我来考考你吧。
飓风:咱们就聊聊redis 的数据类型吧,你说说你都知道哪些redis的数据类型?
小明:老师这个太简单了,包括String 、List、Hash、SortSet、Set。
飓风:那你是怎么应用他们的呢?
小明:简单的key value ,我就用String,如果是要是存储集合且可以重复的就用List,不能重复的我就用Set,如果需要进行排序 就用SortSet,如果要是存一些属性,可以用Hash类型。
飓风:可以吧,只是把每个类型存什么类型的数据说下而已,没有啥深度,那你知道每个数据类型的底层数据结构吗?只有你知道了底层数据结构,你才能知道他们的时间复杂度以及各自的应用场景。
小明:老师,这....,小明陷入懵逼状态,这个还要有底层数据结构....
飓风:当然了,就因为redis 设计了底层数据结构,不同的数据结构对应不同的使用场景,redis 才能这么高效,响应延迟才能发挥到极致,下面我给你画张数据类型和底层数据结构对应关系图。
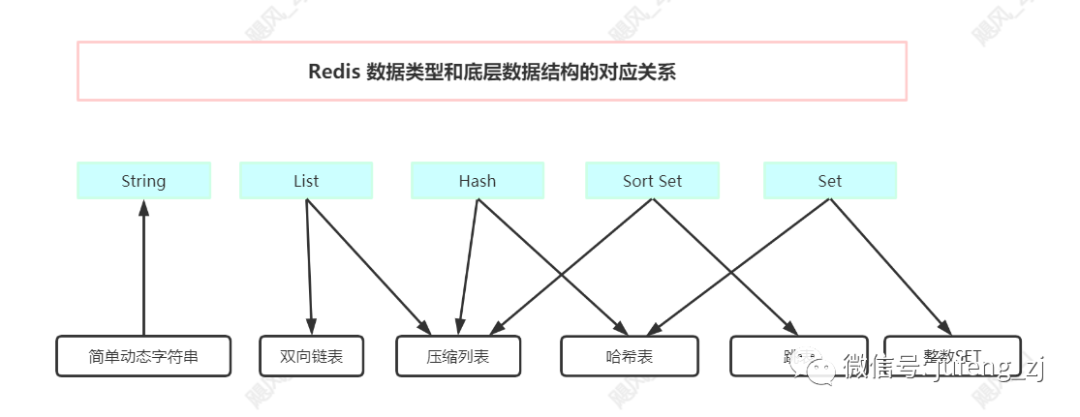
其中蓝色部门就是你刚说的数据类型,下面连线对应的红色框,就是数据类型对应的底层数据结构。
小明:老师,我明白了,原来每个数据类型对应多种底层数据结构的实现。
飓风:下面我来给你介绍下每个底层数据结构的原理吧,听完你就全明白了。
简单动态字符串(SDS)
redis 虽然是C编写的,但是它并没有采用C语言的字串符,而是自己实现了SDS,全称Simple Simple Dynamic String,即简单动态字符串。
我们在执行
set hello jufeng复制
实际上redis 会创建两个SDS,一个是key 的SDS hello,一个是value的SDS jufeng。
其实SDS 不是简单用在key value 中,如果value 是个集合类型,集合的元素是String类型,也是会用SDS来存储的。
除了redis 的数据类型会用SDS,redis 的缓冲区也是会用到的。
看下面结构:
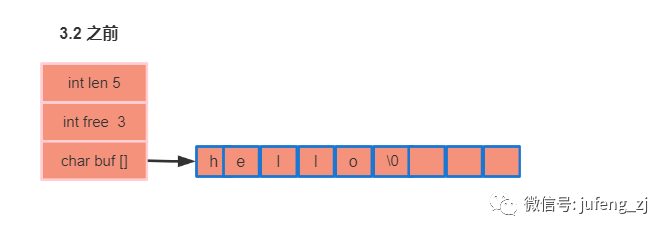
redis3.2 之前:
len: 表示实际使用的长度,这里实际使用了 5 ,/0 不会记录其中
free: 表示剩余多少长度未使用。这里空闲得为 3
buf: 表示实际存储的字符串hello,并以'/0'结尾,表示字符串的结束。
这里len 和 free 使用的 32bit int 来存储,如果实际的值的存储空间不够32 ,这里是其实浪费空间的,所以3.2 之后这里会进行优化。
SDS 的优势:
1. 获取长度的时间复杂度为o(1),而c的需要遍历字符串。
2. 防止 buf 存储内容溢出的问题;每次增加字符串的长度的时候先检查 free 属性是否能存下要增加的字符串的长度,如果不够,则先对 buf 数组扩容,然后在将内容存入 buf 数组中。
3. 能够存入任何二进制数据,图片,音频,文件等,c只能是文本字符串。
4. 空间预分配,减少空间重新分配的次数。
首先 redis 为了减少空间的多次分配,redis 采用jemalloc 来分配内存,为了减少内存分配的开销,jemalloc 会按照所需空间的2^n 最近的空间进行分配。
其次 redis 额外分配未使用空间数量的规则:
当SDS的len属性值小于1MB,程序分配和len属性同样大小的未使用空间。
当SDS的len属性值大于1MB,程序将多分配1M的未使用空间。
5. 惰性空间释放
当对SDS进行字符串缩短操作时,SDS的API不会立即使用内存重分配回收多出来的字节,而是使用free属性将这些字节的数量记录起来,等待将来使用。当然,SDS也提供了相应的API,可以用来真正释放SDS的未使用空间,所以不用担心惰性空间释放策略会造成内存浪费。
3.2 及以后
组成部分如下:
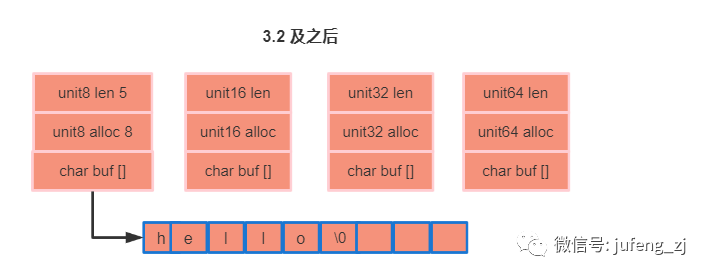
len: 表示实际使用的长度,这里实际使用了 5 。
alloc: 表示redis 分配的内存空间大小,这里是8 ,/0 不会记录其中。
buf: 表示实际存储的字符串hello,并以'/0'结尾。
len与alloc的数据类型 ,表示字符串的用于存储不同大小 len 和 alloc 属性,这样可以减少len 和 alloc 空间的浪费。
没想到吧 一个小小string 类型,竟然包含这么大的学问,我想如果你去面试能够说去这些,面试官肯定能对你刮目相看的,小明同学。
小明:老师,我真是太浮躁了,还说已经精通了呢。
飓风:认真听着,学习吧。
双向[端]链表(Linked List)
节点组成
typedef struct listNode {// 前置节点struct listNode *prev;// 后置节点struct listNode *next;// 节点值void *value;}listNode;多个listNode 通过 pre 和 next 指针相连。为了操作方便,Redis 采用list 持有listNode复制
typedef struct list {// 表头节点listNode *head;// 表尾节点listNode *tail;// 链表包含的节点数量unsigned long len;// 节点复制函数void *(*dup)(void *ptr);// 节点释放函数void (*free)(void *ptr);// 节点对比函数int (*match)(void *ptr, void *key);} list;复制
list 提供了表头 head ,表尾 tail,以及链表的长度 len,和一些链表相关的函数。
具体组成结构为:
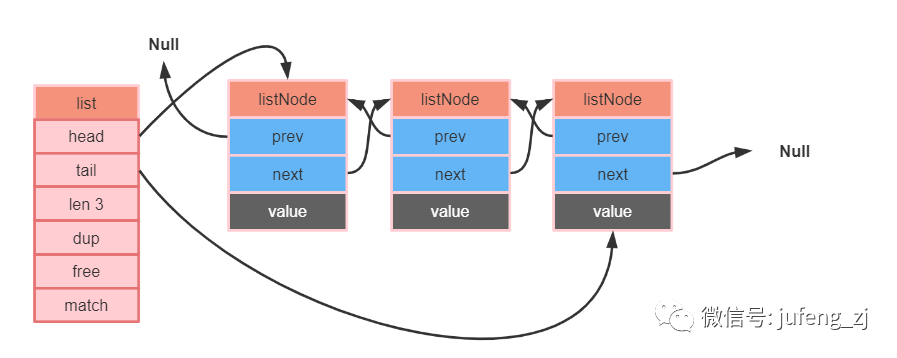
具体的特点有:
双端:链表节点带有pre 和 next 指针,获取某个节点的前置节点和后置节点的复杂度为O(n)
无环:表头的节点 head 的prev指针和 表尾节点 next 都指向了Null,说明链表的访问结束了
获取链表长度:list 的len 属性,可以直接获取链表的长度,复杂度O(1)
多态:链表节点使用void* 指针来保存节点值,可以保存各种不同类型的值。
获取表头和表尾数据负责度O(1)
对应的数据类型:List。
压缩列表(ziplist)
介绍
压缩链表是一种专门为了提升内存使用效率而设计的,经过特殊编码的双端链表数据结构。既可以用来保存整形数值,也可以用来保存字符串数值,为了节约内存,同时也是体现压缩之含义, 当保存一个整形数值时,压缩链表会使用一个真正的整形数来保存,而不是使用字符串的形式来存储。这一点很容易理解,一个整数可以根据其数值的大小使用1个字节,2个字节,4个字节或者8个字节来表示, 如果使用字符串的形式来存储的话,其所需的字节数大小一定不小于使用整形数所需的字节数。
压缩链表允许在链表两端以 O(1) 的时间复杂度执行 Pop 或者 Push 操作,当然这只是一种理想状态下的情况, 由于压缩链表实际上是内存中一段连续分配的内存,因此这些操作需要对压缩链表所使用的内存进行重新分配, 所以其真实的时间复杂度是和链表所使用的内存大小相关的。
压缩链表与经典双端链表最大的区别在于,双端链表的节点是分散在内存中并不是连续的,压缩链表中所有的数据都是存储在一段连续的内存之中的,时间换空间。
组成:
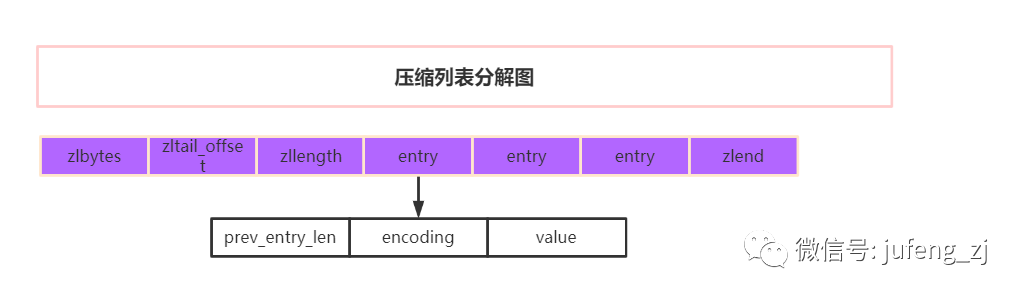
zlbytes:记录整个压缩列表占用的内存字节数,该字段固定是一个四字节的无符号整数,用于表示整个压缩链表所占用内存的长度(以字节为单位),这个长度数值是包含这个<zlbytes>
本身的。
zltail_offset:记录压缩列表尾节点距离压缩列表的起始地址的字节数(目的是为了直接定位到尾节点,方便反向查询)
。该字段固定是一个四字节的无符号整数,用于表示在链表中最后一个节点的偏移字节量,借助这个字段,我们不需要遍历整个链表便可以在链表尾部执行Pop操作。
zllength:记录了压缩列表的节点数量。即在上图中节点数量为3。该字段固定是一个两个字节的无符号整数,用于表示链表中节点的个数。但是该字段最多只能表示2^16-2
个节点个数;超过这个数量,也就是该字段被设置为2^16-1
时, 意味着我们需要遍历整个链表,才可以获取链表中节点真实的数量。
zlend:保存一个常数255(0xFF),标记压缩列表的末端。该字段可以被认为是一个特殊的<entry>
节点,用作压缩链表的结束标记,只有一个字节,存储着0xFF
,一旦我们遍历到这个特殊的标记,便意味着我们完成了对这个压缩链表的遍历。
entry:数据节点
数据节点包括三个部分,分别是前一个节点的长度prev_entry_len,当前数据类型和编码格式encoding,具体数据value。
prev_entry_len:记录前驱节点的长度。
encoding:记录当前数据类型和编码格式。
value:存放具体的数据
为了节省空间,entry做了很多的优化工作。
prev_entry_len , 这个字段标记了该节点的前序节点的长度,以便我们可以向链表的头部反向遍历链表。
当前节点的前序节点的长度为0到253个字节时,
<prevlen>
字段只需要一个8位的无符号整数,也就是一个字节,便可以编码对应的长度。当前节点的前序节点的长度大于等于254个字节时,
<prevlen>
字段则需要5个字节,其中第一个字节会被设置成0xFE
也就是254, 这是一个特殊标记,用于表明,这里保存了一个比较大的数值,需要继续读取后续的4个字节以解码出前序节点的长度。而为什么不选择0xFF
作为特殊标记的原因在于,0xFF
是整个链表结束的标记。
enconding, 这个字段用于表示该节点使用的编码方式,具体是按照整形数进行编码还是按照字符串进行编码, 当节点使用的是字符串编码时,该字段还会指明字符串数据的字节长度。
当<encoding>
字段首字节的前两个比特都为1的时候,也就是出现[11XXXXXX]
这样的情况时,表明当前节点是使用整形数进行编码的。
当<encoding>
字段首字节的前两个比特不是11
的情况时,则表明该节点的数据是以字符串的形式进行编码的。
对应的数据类型:List 、Hash、Sort Set
哈希表
数据结构
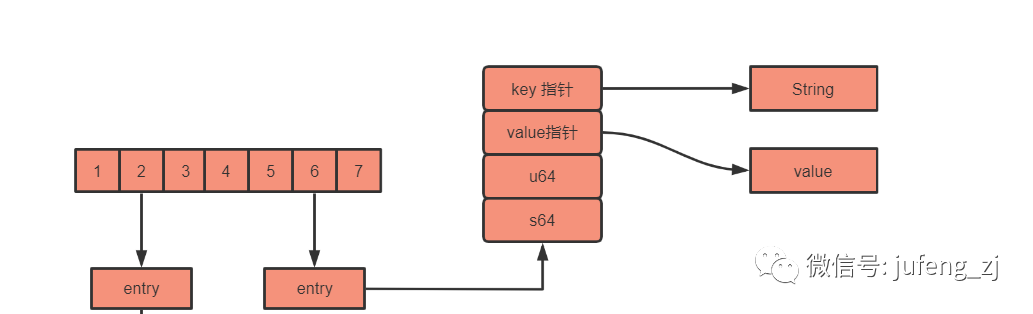
Redis使用的哈希表由dictht结构定义:
typedef struct dictht{// 哈希表数组dictEntry **table;// 哈希表大小unsigned long size;// 哈希表大小掩码,用于计算索引值// 总是等于 size-1unsigned long sizemask;// 该哈希表已有节点数量unsigned long used;} dictht复制
哈希表节点使用dictEntry结构表示,每个dictEntry结构都保存着一个键值对:
typedef struct dictEntry {// 键void *key;// 值union {void *val;unit64_t u64;nit64_t s64;} v;// 指向下一个哈希表节点,形成链表struct dictEntry *next;} dictEntry;复制
key属性保存着键值对中的键。
v属性则保存了键值对中的值。值可以是一个指针,一个uint64_t整数或者是int64_t整数。
哈希表其实就是一个数组,数组的元素存储的是一个dictEntry,具体看下图解:
next属性指向了另一个dictEntry节点,在数组桶位相同的情况下,将多个dictEntry节点串联成一个链表,以此来解决键冲突问题,看下图:
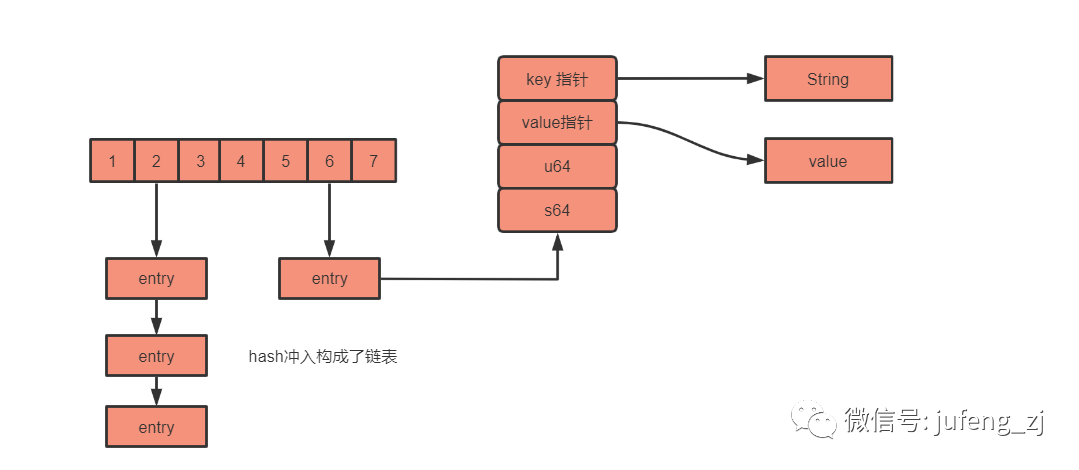
对应的数据类型:Hash、Set
整数集合
intset数据结构
typedef struct intset {uint32_t encoding; // 编码模式uint32_t length; // 长度int8_t contents[]; // 数据部分} intset;复制
Intset是集合键的底层实现之一,如果一个集合满足只保存整数元素和元素数量不多这两个条件,那么 Redis 就会采用 intset 来保存这个数据集,它的特点有:
元素类型只能为数字。
元素有三种类型:int16_t、int32_t、int64_t。
元素有序,不可重复。
内存连续,来节省内存空间。
length 字段用来保存集合中元素的个数。
contents 字段用于保存整数,数组中的元素要求不含有重复的整数且按照从小到大的顺序排列。在读取和写入的时候,均按照指定的 encoding 编码模式读取和写入。
encoding 字段表示该整数集合的编码模式,Redis 提供三种模式的宏定义如下:
// 可以看出,虽然contents部分指明的类型是int8_t,但是数据并不以这个类型存放// 数据以int16_t类型存放,每个占2个字节,能存放-32768~32767范围内的整数#define INTSET_ENC_INT16 (sizeof(int16_t))// 数据以int32_t类型存放,每个占4个字节,能存放-2^32-1~2^32范围内的整数#define INTSET_ENC_INT32 (sizeof(int32_t))// 数据以int64_t类型存放,每个占8个字节,能存放-2^64-1~2^64范围内的整数#define INTSET_ENC_INT64 (sizeof(int64_t))复制
升级:
intset中最值得一提的就是升级操作。当intset中添加的整数超过当前编码类型的时候,intset会自定升级到能容纳该整数类型的编码模式,如 1,2,3,4,创建该集合的时候,采用int16_t的类型存储,现在需要像集合中添加一个大整数,超出了当前集合能存放的最大范围,这个时候就需要对该整数集合进行升级操作,将encoding字段改成int32_t类型,并对contents字段内的数据进行重排列。
插入1 2 3 4 情况如下:
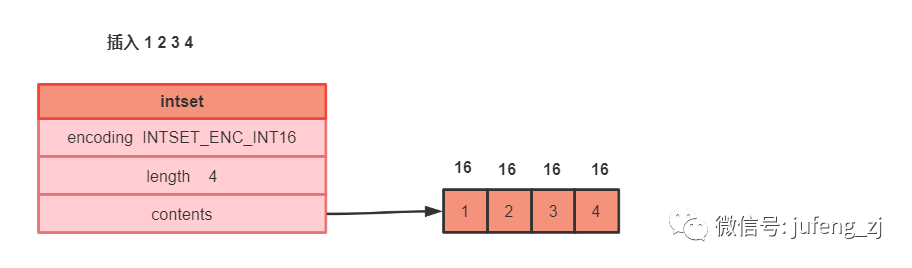
采用的econding 类型为 INTSET_ENC_INT16
插入4 个元素,所以length 为4 具体内容就是 contents
如果此时接着就插入一个 32768 ,占用了4字节 ,econding 就是会升级为 INTSET_ENC_INT16,同时对所有元素进行重新排位,占用16bit。看下图,注意和上图比较,格子的宽度变大了。
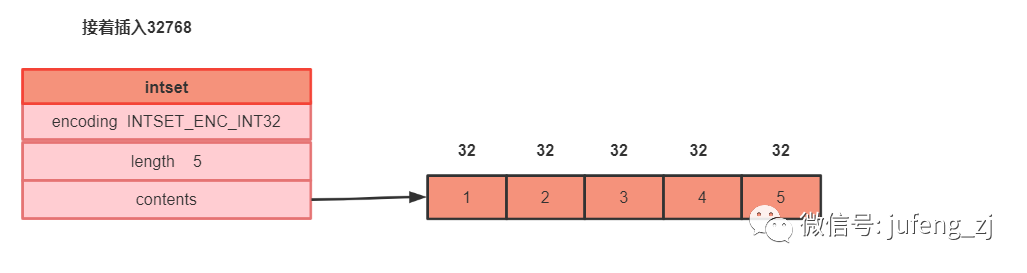
一个intset只能有一种规格。一个intset的规格升级后就永远不会降级了。
其他特点
intset不提供批量插入接口。插入多个元素只能循环插入。
由于数组要保持有序,所以插入时,需将插入位置之后的所有元素都向后移动。同理,删除元素时,需将删除位置之后的所有元素都向前移动。
由于有序,查找时采用二分查找。这里针对二分做了优化,查找的元素先与最大值比较,如果比最大值还大,则肯定不存在。最小值也是一样。
intset不提供修改接口,因为它是集合,相当于只有key,没有value,也就没有修改这一说,只能增、删。
对应的数据类型:Set
跳表
跳跃表是一种有序的数据结构,它通过在每个节点中维持多个指向其他的节点指针,从而达到快速访问队尾目的,复杂度o(logn)。跳跃表的效率可以和平衡树想媲美了,最关键是它的实现相对于平衡树来说,代码的实现上简单很多。
插入
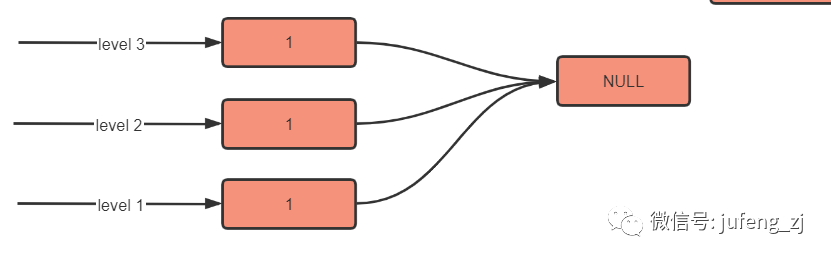
我们需要插入一些数据,此时的链表是空

插入 level = 3,key = 1 :
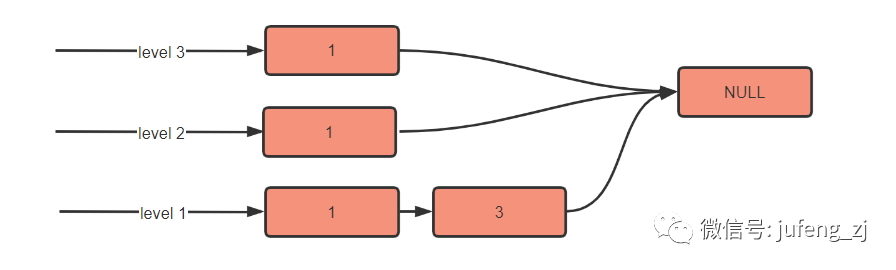
当继续插入 level = 1,key = 3 时,结果如下:
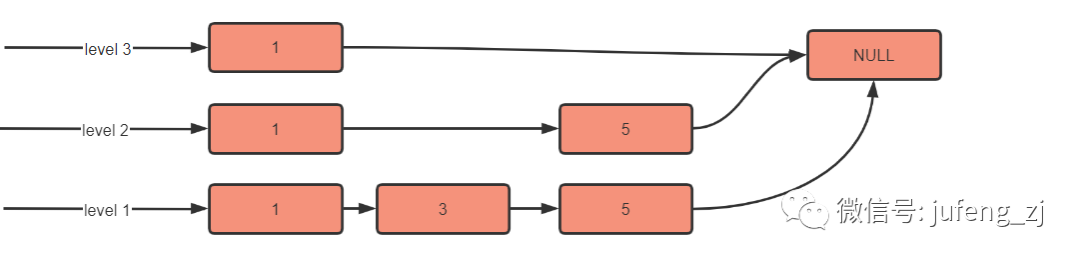
当继续插入 level = 2,key = 5 时,结果如下:
当继续插入 level = 3,key = 7 时,结果如下:
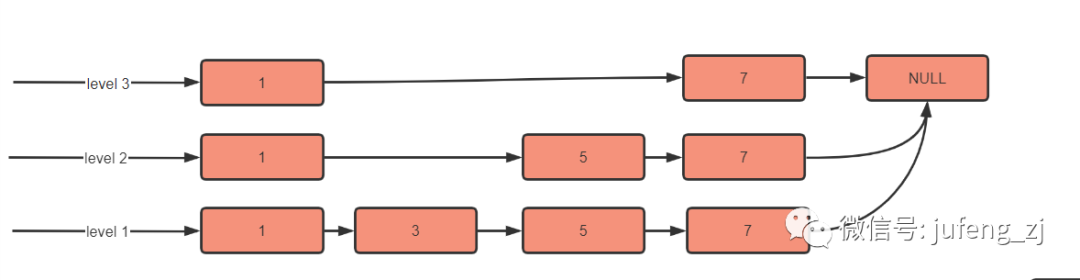
当继续插入 level = 1,key = 88 时,结果如下:

当继续插入 level = 2,key = 100 时,结果如下:

每个层级最末端节点指向都是为 null,表示该层级到达末尾,可以往下一级跳。
查询
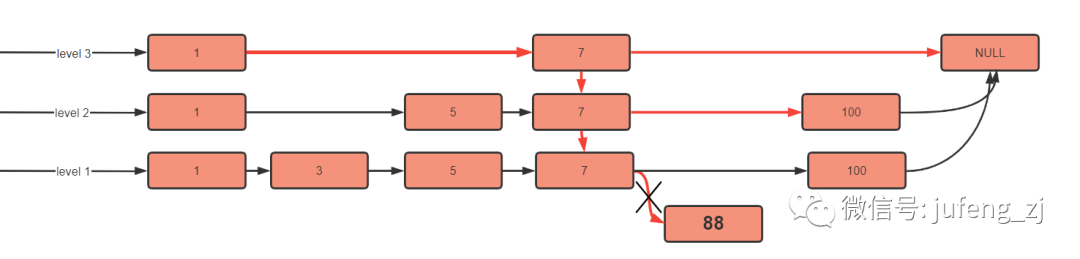
现在查找88 节点
跳跃表的查询是从顶层往下找,那么会先从第顶层开始找,方式就是循环比较,如果顶层节点的下一个节点为空说明到达末尾,会跳到第二层,继续遍历,直到找到对应节点。
我们带着键 88 和 1 比较,发现 88 大于 1。继续找顶层的下一个节点,发现 88 也是大于五的,继续遍历。由于下一节点为空,则会跳到 level 2。
上层没有找到 88,这时跳到 level 2 进行遍历,但是这里有一个点需要注意,遍历链表不是又重新遍历。而是从 7 这个节点继续往下找下一个节点。如下,我们遍历了 level 3 后,记录下当前处在 7 这个节点,那接下来遍历是 7 往后走,发现 100 大于目标 88,所以还是继续下沉。
当到 level 1 时,发现 7 的下一个节点恰恰好是 88 ,就将结果直接返回。具体看下面红色线走向

删除
删除和查找类似,都是一层层去查找,查到之后,进行删除,移动指针就可以了
对应的数据类型:Sort Set
飓风:小明,这就是我给你讲的这几种底层数据结构,希望你能好好熟悉哦。
小明:老师 我回去一定好好阅读和复习。
其实redis 不光这几种数据类型,还包括 HyperLogLog 、Bitmap、Bloomfilter、GEO等。
RedisObject
redis 的每一个key value 都会被包装成一个 RedisObject 对象。
typedef struct redisObject {// 类型unsigned type:4;// 编码unsigned encoding:4;// 底层数据结构的指针void *ptr;} robj;复制
type 属性 记录了 对象的类型。
encoding 表示了数据对应的数据结构类型。
ptr 是指针,指向底层的数据结构。
type 属性表
| 类型常量 | 对象名称 |
|---|---|
| REDIS_STRING | 字符串对象 |
| REDIS_LIST | 列表对象 |
| REDIS_HASH | 哈希对象 |
| REDIS_SET | 集合对象 |
| REDIS_ZSET | 有序集合对象 |
encoding 对照表
| 编码常量 | 底层数据结构 |
|---|---|
| REDIS_ENCODING_INT | long类型的整数 |
| REDIS_ENCODING_EMBSTR | emstr编码的简单动态字符串 |
| REDIS_ENCODING_RAW | 简单动态字符串 |
| REDIS_ENCODING_HT | 字典 |
| REDIS_ENCODING_LINKEDLIST | 双端链表 |
| REDIS_ENCODING_ZIPLIST | 压缩列表 |
| REDIS_ENCODING_INTSET | 整数集合 |
| REDIS_ENCODING_SKIPLIST | 跳跃表和字典 |
对于REDIS_ENCODING_INT、REDIS_ENCODING_EMBSTR 、后面还会专门讲解。REDIS_ENCODING_HT 会在全局hash表,或者 rehash 的时候讲解。
总结
今天学习了reids 的数据类型 String 、List、Hash、SortSet、Set 对应的底层数据结构,SDS、双向链表、压缩列表、哈希表、整数SET、跳表。
正因为redis 实现了这些底层的数据结构,才能使用性能发挥到的极致。
这里再说下查找的时间复杂度吧
| 数据结构 | 时间复杂度 |
|---|---|
| 哈希表 | O(1) |
| 跳表 | o(logN) |
| 压缩列表 | o(N) |
| 压缩列表头尾节点 | o(1) |
| 双端链表 | o(N) |
| 双端链表头尾节点 | o(1) |
| 整数SET | o(N) |
其中压缩列表和整数set 都是连续的内存地址,没有指针的开销,节省了内存,典型的时间换空间。
压缩列表和双端链表 对头尾操作都是o(1),所以适用于做FIFO 队列来适用,不建议做为集合来做全量和范围查找。




