




注:本篇主要是学习参考Designing Data-Intensive Application 第三章。
目前主流的存储引擎分类有日志结构(log-structured)的存储引擎、面向页面(page-oriented)的存储引擎。
日志结构(log-structured)的存储引擎
日志
日志:一个仅追加(append-only)的记录序列。许多数据库在内部使用了日志(log), 但它在实践中有很多问题需要解决,如:查询效率、并发控制、回收磁盘空间以避免日志无限增长,处理错误与部分写入。
为了高效查询数据库中特定键的值,我们一般需要一种数据结构——索引(index),来加快查询效率。
思考:
对于日志文件的索引可以怎么做?
假设我们的数据存储是一个追加写文件, 并且文件存储的是键值数据。我们可以为之选择什么样的索引策略?
哈希索引
最简单的索引策略就是:保留一个内存中的哈希索引,其中每个键都映射到一个数据文件中的字节偏移量,指明了可以找到对应值的位置。当将新的键值对追加到写入文件时,还要更新散列映射,以反映刚刚写入数据的偏移量。
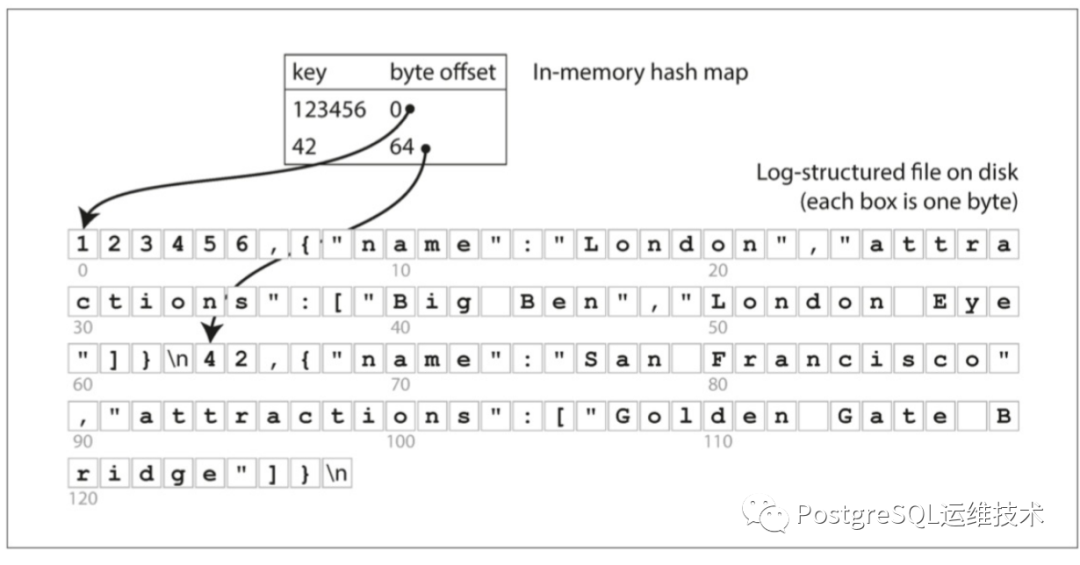
Bitcask就是采用这种存储策略的存储模型。以Bitcask为存储模型的k-v系统有Riak。
这种存储引擎适合键值少但需要经常更新的情况。例如,键是视频的URL,值是它播放次数(在用户每次的点击时递增)。这种类型的工作负载中,有很多写入操作,但没有太多不同的键(将所有键保存到内存中是可行的)。
上面我们讨论的场景,只是追加写入一个文件,所以再思考一个问题:
如何避免最终用完磁盘空间呢?
对这一个问题,一个好的解决方案是:将日志分为特定大小的段,当日志增长到特定尺寸时,关闭当前段文件,并开始写入一个新的段文件。然后,我们就可以对这些段进行压缩(compaction)。同时我们在执行压缩的同时,将多个段合并在一起,并写入到一个新的文件。段的合并和压缩可以在后台线程中完成,在这期间,我们仍然可以使用旧的段文件来提供正常的读写请求。合并完成后,我们将请求转化为使用新的合并段,此时就可以删除旧的段文件。
简单来说,就是对日志文件进行分段,分段后进行合并压缩。

每个段都有自己的内存散列表(哈希映射), 将键映射到文件偏移量。为了找到一个键的值,我们首先检查最近段的哈希映射,如果键不存在,我们检查第二个最近的段,依次类推。
这种方案,在进入实践时,存在很多问题需要注意,比如:
文件格式
选择什么样的文件格式进行存储。删除记录
如果要删除一个键及其关联的值,则必须在数据文件中附加一个特殊的删除记录。当日志段被合并时,逻辑删除告诉合并过程放弃删除键以前的所有值。崩溃恢复
如果数据库重新启动,则内存散列映射将丢失。原则上我们可以从段文件中恢复每个段的哈希映射。但是,如果段文件很大,这将需要很长时间。部分写入
在将记录追加到日志时,数据库可能发生崩溃。并发控制
此外,哈希索引也有一定的局限性:
散列表必须能放进内存。但当键有很多时,是无法做到的。原则上可以在磁盘上保留一个哈希映射,但是这就需要大量的随机访问IO。 需解决哈希冲突的问题。 范围查询效率低。
那么有没有什么方式去解决上述的问题呢?
SSTable
在上面我们讨论的场景中,每个日志结构存储段都是一系列键值对。这些键值对按照它们写入的顺序出现,日志中稍后的值优先于日志中较早的相同键的值。现在,我们对段文件的格式做一些改变:我们要求键值对的序列按键排序。这时候你会想,那这样不是打破了日志顺序写的能力了吗?往下看。
键值对序列按键排序的存储结构就是SSTable(Sortable String Table)。在Google Bigtable论文中对SSTable的定义是:
SSTable提供一个可持久化的,有序的、不可变的从键到值的映射关系,其中键和值都是任意字节长度的字符串。SSTable提供了以下操作:按照某个键来查询关联值,可以指定键的范围,来遍历其中所有的键值对。每个SSTable内部由一系列块(block)组成(通常每块大小为64KB,是可配置的)。使用存储在SSTable结尾的块索引(block index)来定位块;当SSTable打开时,索引会被加载到内存里。一次磁盘寻道(disk seek)就可以完成查询(lookup)操作:首先通过二分查找搜索存储在内存的索引找到对应的块,然后从磁盘上读取这块内容。SSTable也可以完整地映射到内存里,这样在执行查询和扫描(scan)的时候就不用操作磁盘了.
简而言之,SSTable是一个键是有序的,存储字符串形式键值对的文件。
与使用散列索引的日志段相比,SSTable有几个优势。
合并段更加简单而高效。因为每个段中键是有序的。这种合并就类似于归并排序算法中使用的方法一样:并排读取输入文件,查看每个文件中的第一个键,复制最低键(按排序顺序)到输出文件,并重复。这将产生一个新的也是按键排序的合并段文件。

不再需要在内存中保存所有键的索引。假设你想要寻找键handiwork,但是内存中没有保存该键值的确切偏移量,但是保存了handbag和handsome的偏移,由于段的排序特性,我们知道了handiwork必定在这两者之间,这就意味着我们可以跳到handbag的偏移位置,然后向后扫描,直到找到handiwork即可。

这种方案虽然仍然需要保存一些键的偏移量,但是不需要是全部的键。它们可以说很稀疏的。
另外,由于读取请求无论如何都需要扫描所请求范围内的多个键值对,因此可以将这些记录分组到块中,并在将其写入磁盘之前进行压缩。稀疏内存索引中的每个条目都指向压缩块的开始处(上图中阴影区域所示)。这样可以节省磁盘空间,压缩还可以减少IO带宽。
我们看到了SSTable的好处,但是写入可以以任意顺序发生的, 所以我们应该怎么让数据按键排序?或者说怎么去构建和维护SSTable呢?
构建和维护SSTable
写入磁盘时,做到使文件有序是很困难的,所以我们可以选择在内存中去维护顺序, 可行的做法是,在写入时,我们可以先将其添加到内存中的平衡树数据结构(例如:红黑树、AVL树),由树来维护键的顺序。等内存中结构达到一定的阈值时,将其作为SSTable写入磁盘。
这个时候我们可以使我们的存储引擎按如下方式工作:
写入时,将其添加到内存中的平衡树数据结构,也被称为内存表(memtable)。 当内存表大于某个阈值时,将其作为SSTable写入磁盘。当SSTable被写入磁盘时,写入可以继续到一个新的内存表。 对于读取请求,先尝试在内存表中找到关键字,然后在最近的磁盘段中,如果找不到,继续到下一个较旧的段中找到该关键字,依此类推。 在后台不断合并和压缩段文件并丢弃老的文件。
这种方案有个问题:如果数据库崩溃,则最近的写入(还在内存表中,尚未写入SSTable——磁盘)将会丢失。为了避免这个问题,我们在每次收到一个写请求,先把该条数据写入的wal log里,用作故障恢复。
这里描述的算法本质上是LevelDB和RocksDB中使用的关键字存储引擎库,在Cassandra和HBase中也使用了类似的存储引擎。基于这种合并和压缩排序文件原理的存储引擎通常被称为LSM存储引擎。
LSM Tree
LSM-Tree全称是Log Structured Merge Tree, 有三个组成部分:MemTable、Immutable Memtalbe。
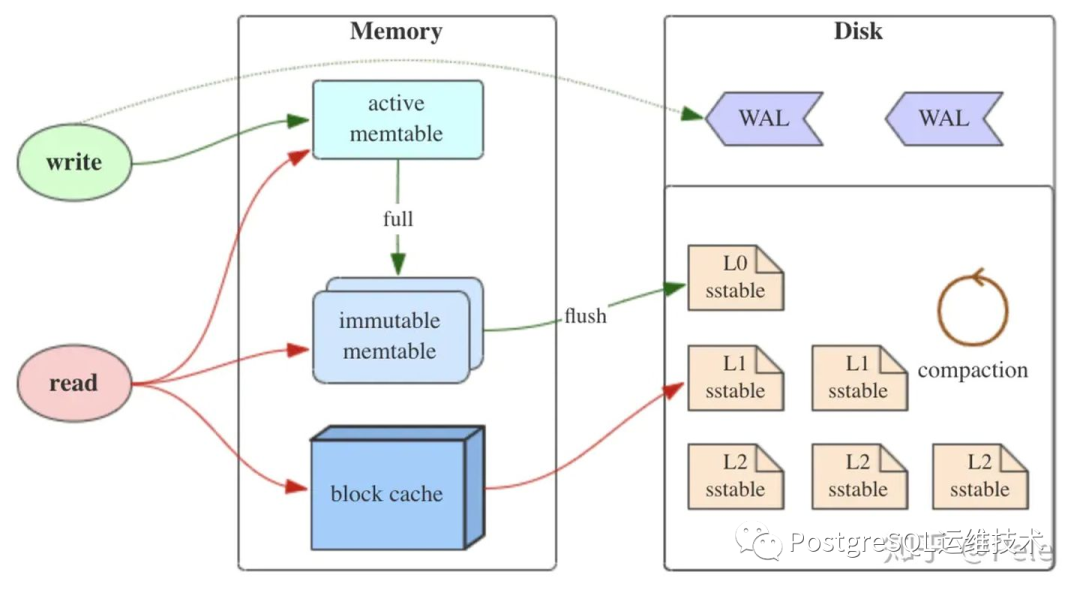
图片来源于:https://zhuanlan.zhihu.com/p/181498475
MemTable: 是在内存中的结构,用于保存最近更新的数据,会按照key有序地组织这些数据,为了维持有序性,通常在内存里采用红黑树或跳跃表相关的数据结构。因为内存并不是可靠存储,如断电会丢失数据,因此通常会通过wal的方式来保证数据可靠性。 Immutable Memtable:当 MemTable达到一定大小后,会转化成Immutable MemTable。Immutable MemTable是MemTable转变为SSTable的一种中间状态。写操作由新的MemTable处理,在转存过程中不阻塞数据更新操作。 SSTable:上节我们也介绍了,SSTable是一个键是有序的,存储字符串形式键值对的文件。它是LSM数组在磁盘中的数据结构。
我们再总结下在在LSM-Tree里面如何写数据的:
当收到一个写请求时,会先把该条数据记录在WAL Log里面,用作故障恢复。 当写完WAL Log后,会把该条数据写入内存的SSTable里面,也称Memtable。为了维持有序性在内存里面可以采用红黑树或者跳跃表相关的数据结构。 当Memtable超过一定的大小后,会在内存里面冻结,变成Immutable Memtable,同时为了不阻塞写操作需要新生成一个Memtable继续提供服务。 把内存里面Immutable Memtable给dump到硬盘上的SSTable层中。 当每层的磁盘上的SSTable的体积超过一定的大小或者个数,会周期的进行合并。
除此之外,对于这种算法,在实践中仍有一些优化点,比如:
当查找数据库不存在的键时,LSM算法会很慢,为了优化这种访问,存储引擎通常使用额外的Bloom过滤器,来判断一个key是否存在。 SSTable压缩策略的选择。comapation操作可以清除无效数据,缩短读取路径,提高磁盘利用空间。但是compaction操作本身是非常消耗cpu和磁盘io的,尤其在业务高峰期,会导致系统的吞吐量下降,所以说合适的compation策略也十分重要。
面向页面(page-oriented)的存储引擎
这种类型的存储引擎也是应用最广范、大众最熟知的一种,即我们知道的B tree存储结构。
B树
这是一种使用最广泛的存储索引结构,设计理念和日志结构索引不同。它将数据分解成固定大小的页, 插入新key时,查找key的位置,并用新的value覆盖老的value。
B树在1970年被引入,在几乎所有的关系型数据,它仍是标准的索引实现。
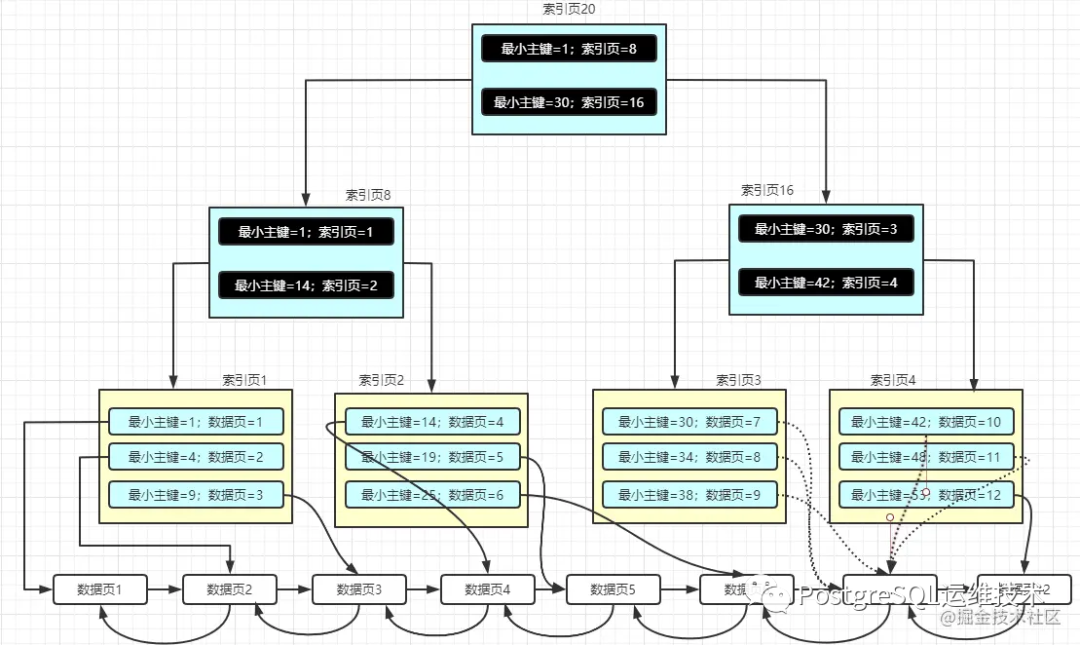 图片来源:https://juejin.cn/post/6931901822231642125#heading-7
图片来源:https://juejin.cn/post/6931901822231642125#heading-7
B+树有几点性质:
在B+树中的每一个节点,就是一个页。 根节点和叶节点是索引页,叶子节点是一个数据页。 数据在数据页中的存储是连续的,页内的记录按照主键的大小顺序组成一个单向链表,页面之间通过双向链表连接。
LSM Tree vs BTree
BTree相对于LSM tree来说,起源更早,实现上也更成熟。直到现在,在几乎所有的主流关系型数据中,它仍是标准的索引实现。而LSM Tree,由于其较高的写吞吐量也在逐渐被越来越多数据库产品所选择。
LSM树相比B树有更高的写吞吐量。一是因为顺序写比随机写要快得多。再是它有用较低的写放大。
怎么理解写放大?b树是面写页的,页是它进行写操作的最小单元,所以即使在页面中只有几个字节发生了变化,也需要一次编写整个页面。LSM树也有写放大的问题,因为需要反复压缩和合并SSTable,lsm也会重写数据,这通常需要对数据库进行良好的配置,合理设置压缩策略,避免压缩过程严重影响正常的读写操作,相比之下,B树的行为则更具有可预测性。 LSM树相对比B树,有较低的存储开销。由于LSM不是面向页面的,并且定期合并SSTables以去除碎片,所以LSM树可以被压缩地更好,它会比b树在磁盘上产生更小的文件。 B树拥有更好的读性能,并且更容易实现事务(因为b树的每个键值存在于索引中的一个位置,而LSM可能在段中有相同键的多个副本。)
参考:
Designing Data-Intensive Application
https://zhuanlan.zhihu.com/p/181498475
https://cloud.tencent.com/developer/article/1441835
https://juejin.cn/post/6931901822231642125#heading-7
