




各位小伙伴,大家好,欢迎阅读我对openGauss训练营的学习心得,我是一名来自传统金融行业的IT架构师,之前听的最多的就是GaussDB一款华为旗下国产自主研发的分布式数据库,公司内使用场景最多的是大数据团队,但作为一名长期使用Db2、Oracle这样关系数据库的一名金融IT从业人员,对国产数据库了解并不是很多,总觉得国产数据库无非就是在开源mysql的基础上做了二次革新,换汤不换药,平时工作过程中,关注最多的是墨天轮的数据库排名,OceanBase和Tidb一直遥遥领先,最近浏览墨天轮的文章,突然看到openGauss最近突飞猛进跃至第四位,超过了polarDB和gaussDB,为什么它能市场占有率迅猛增长,怀着好奇的心情和为了迎接国家信创事业,还是决定一探国产数据库的秘密,一个特别的机会,和平常一样登录墨天轮,看到8个小时玩转openGauss训练营(第二期)的帖子,毫不犹豫立马报了名,来探一探openGauss的神秘面纱。
怀着猎奇探索的心情,来到了openGauss训练营(第二期)第一天(周六)下午1点半,端坐在电脑旁边坐等开课,再次特别感谢墨天轮平台和openGauss团队们的分享,首先听朱金伟老师的《OpenGauss体系架构》第一讲,终于认识了OpenGauss一个开源的国产关系型数据库,也理解了华为为何牛,因为华为是在做所有人不敢做的事情,思想理念太强大,华为这么多的技术大牛,竟然把openGauss开源出来让全国乃至全世界的IT专家们去共同完成一个属于中国人自己研发的关系型数据库,而且做的这么专业这么厉害,太难易想象了,真是为我打开了国产数据库的面纱。华为公司从20年前就开始孵化国产数据库,20年后发布属于华为研发平台国内版gaussDB分布式交易性数据库。如下图:

并之后使用了9个月的时间做了一款同gaussDB共研发平台的OpenGauss并进行了开源,让国内各行业都能使用到自主研发的数据库。
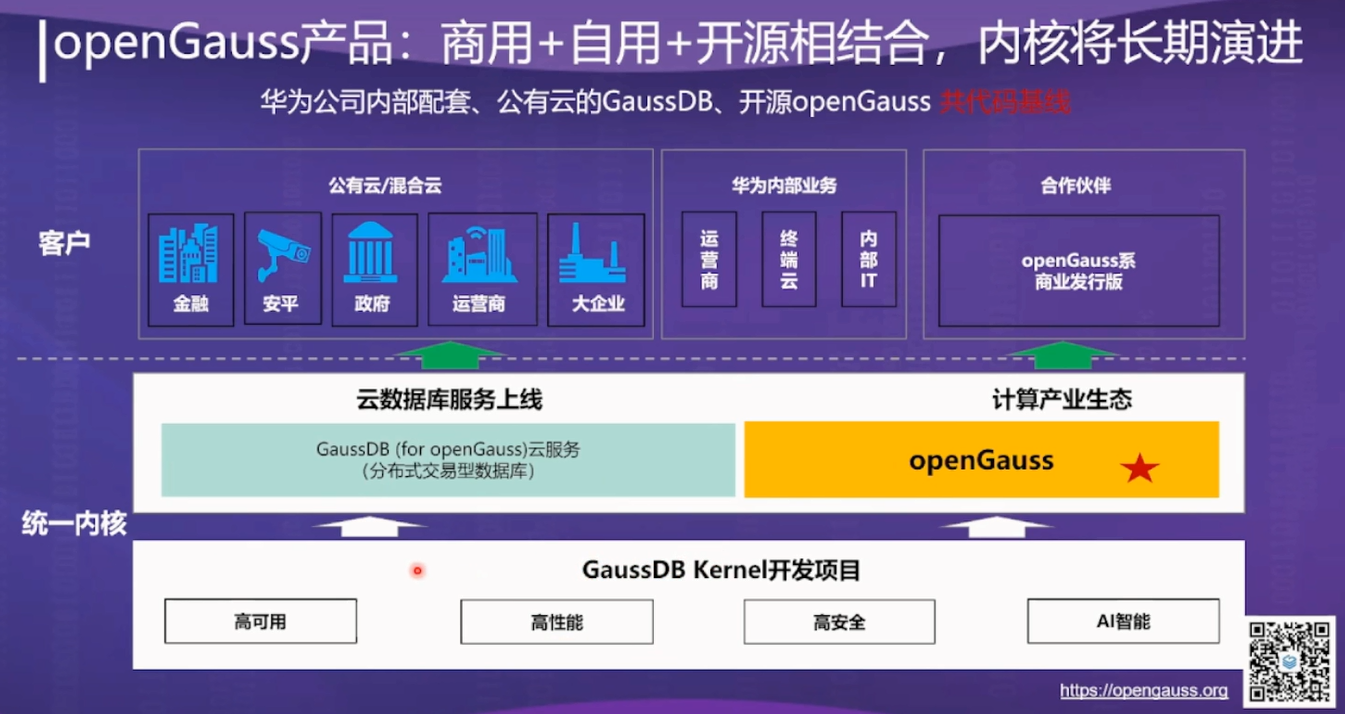
可从上图可以看到GaussDB和openGauss是统一内核,共同建立在GaussDB Kerner平台之上,这样对国内业界为苦于无法找到更好的替代DB2和Oracle的IT研发者们提供了更好的选择性,并且华为针对开源openGauss有专业的运营和技术支持团队。
第一天下午4个小时的时间里,最令我印象深刻的是第三讲 刁现峰老师针对《WDR报告及性能调优》因为自己公司在使用DB2关系型数据库过程中接触最多的还是存储过程执行效率、DB2数据库参数调整和性能调优,这是所有使用关系型数据库都必须面临的一个环节,当我听到刁老师讲解性能调优时,脑海中想到最多的还是建立索引,查看执行计划中耗费资源最多的项进行开展,但听了刁老师的讲解,让我们看到了华为工程师都是最专业的,刁老师竟然能把数据库性能优化讲解的这么有条理,首先他把数据库的指标分为三个层级:

系统级、对象级、应用级,没想到一个开源数据库团队能把枯燥的数据库指标拆分的这么清晰明了,听了一遍就能听懂为何我们数据库优化没有人家专业了,因为我们的知识不够,没有对数据库指标进行分层次研究。
从时间内存消耗系统级监控指标:
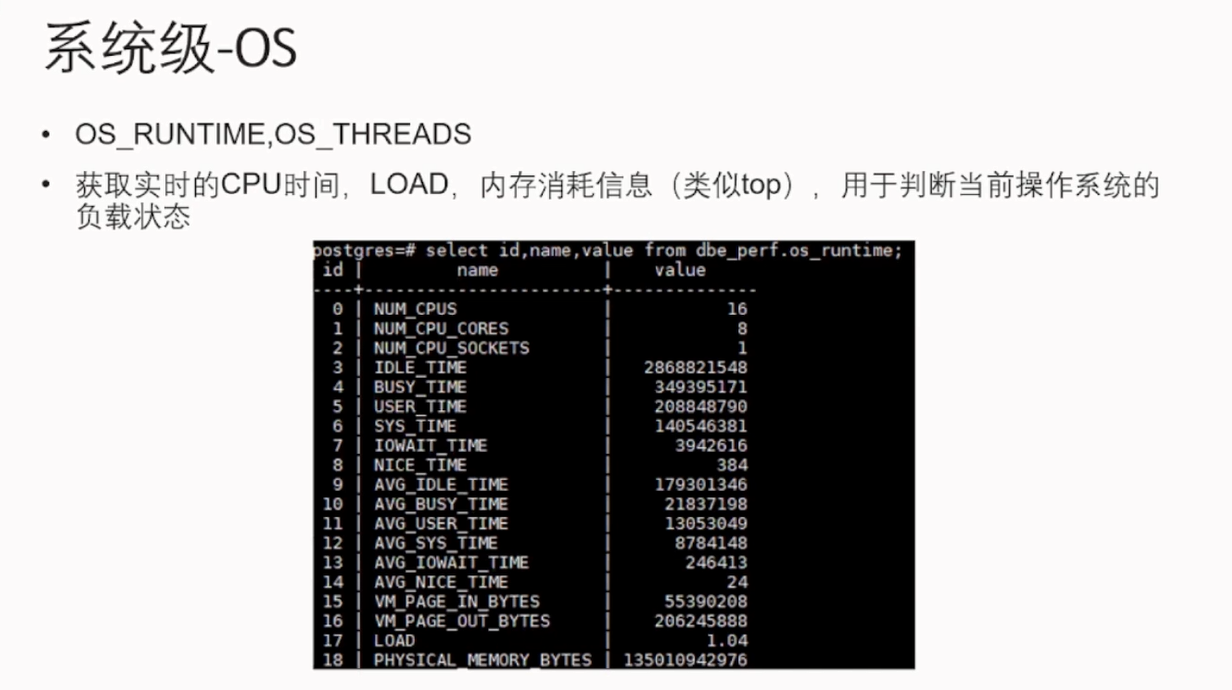
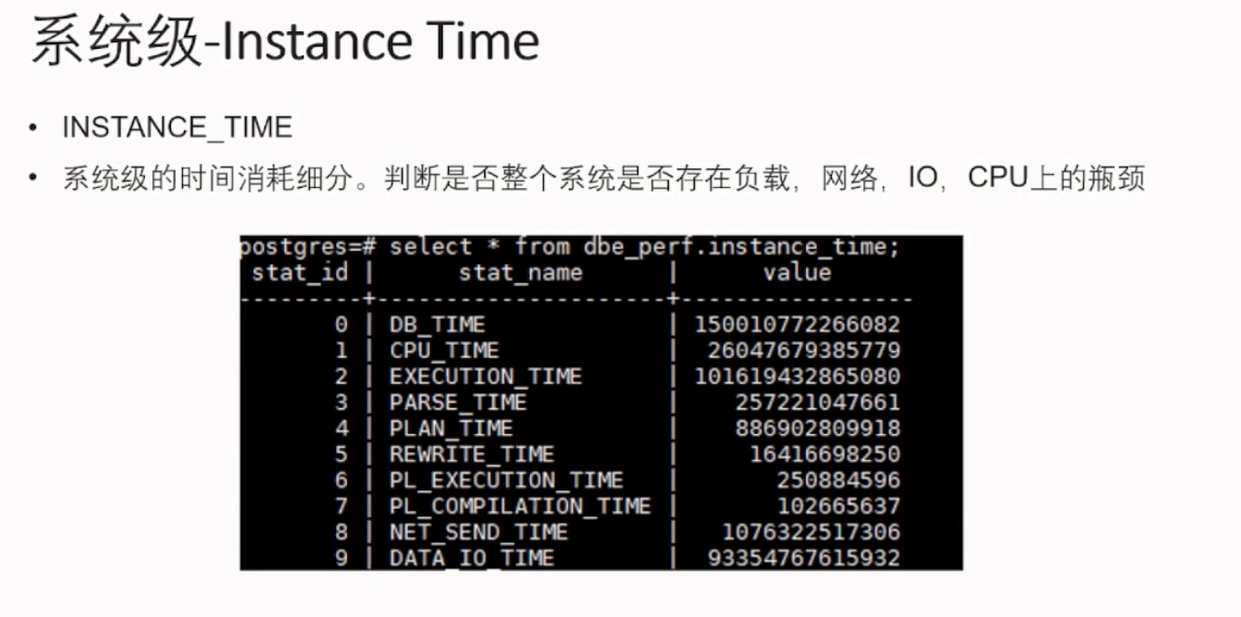

到应用级慢SQL的处理与监控:

另外通过刁老师针对核心的指标还做了一个核心矩阵:
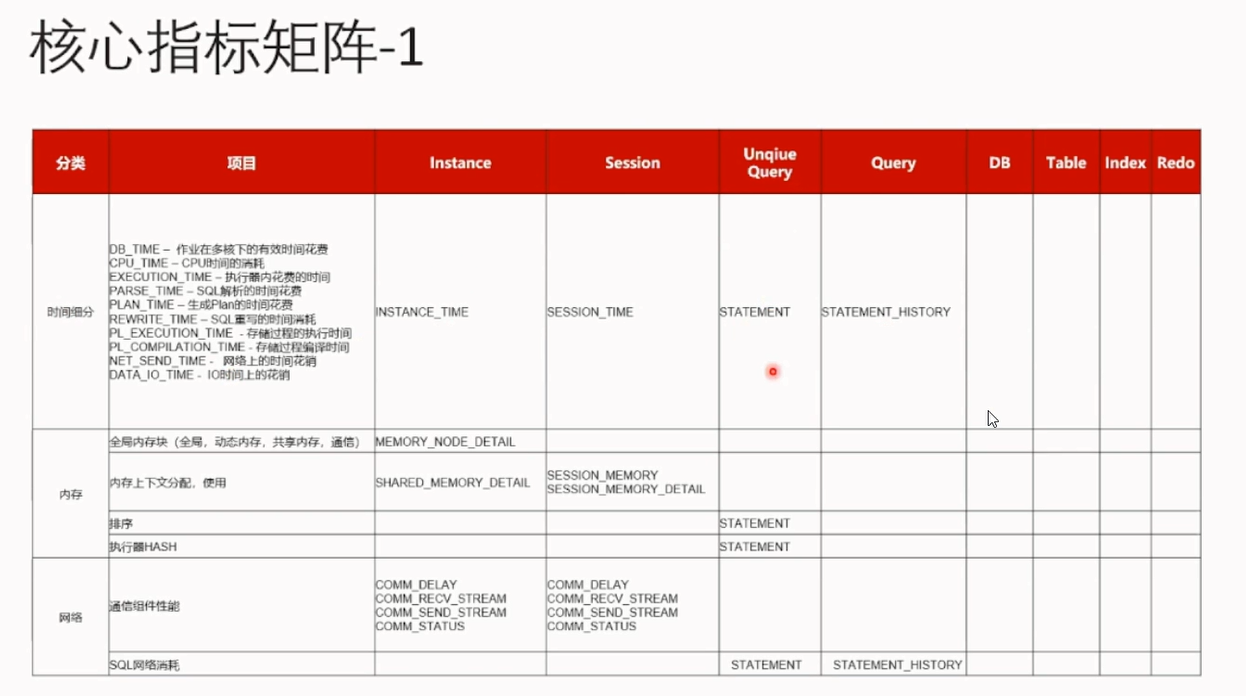
通过以上的内容系统和详细的剖析,让我们更深刻的了解OpenGauss原来什么都可以做,只要是关系型数据库能做的它都能做,正常关系型数据库不能做的它也能做。比如它的AI特性、openGauss大内存表的概念。
特别是openGauss大内存表的概念是王鹏博士的主攻方向,它竟然可以支撑2T的内存级数据库,真实不敢想象。

比如上图的MOT介绍,体现了高吞吐量3倍于磁盘表,事务处理加速3倍至5.5倍。
通过对openGass的初探,更加深了我要未来要继续研究OpenGauss,最好能让公司在信创的推动下把国外数据库都换成华为的开源关系型数据库openGauss。
