




一、存储方式-行列混合存储
本特性自openGauss 1.0.0 版本开始引入。
openGauss 支持行存储和列存储两种存储模型,用户可以根据应用场景,建表的时候选择行存储还是列存储表。
但是官方文档没有说我一个表同时使用行+列的混合存储,这个是没有说的!
也能理解,你不能说一个表同时使用行存和列存储;
另外一种Opengauss 有特点的是内存表;
二、那么行存储和列存储格式有什么特点?
2.1 存储格式的差异
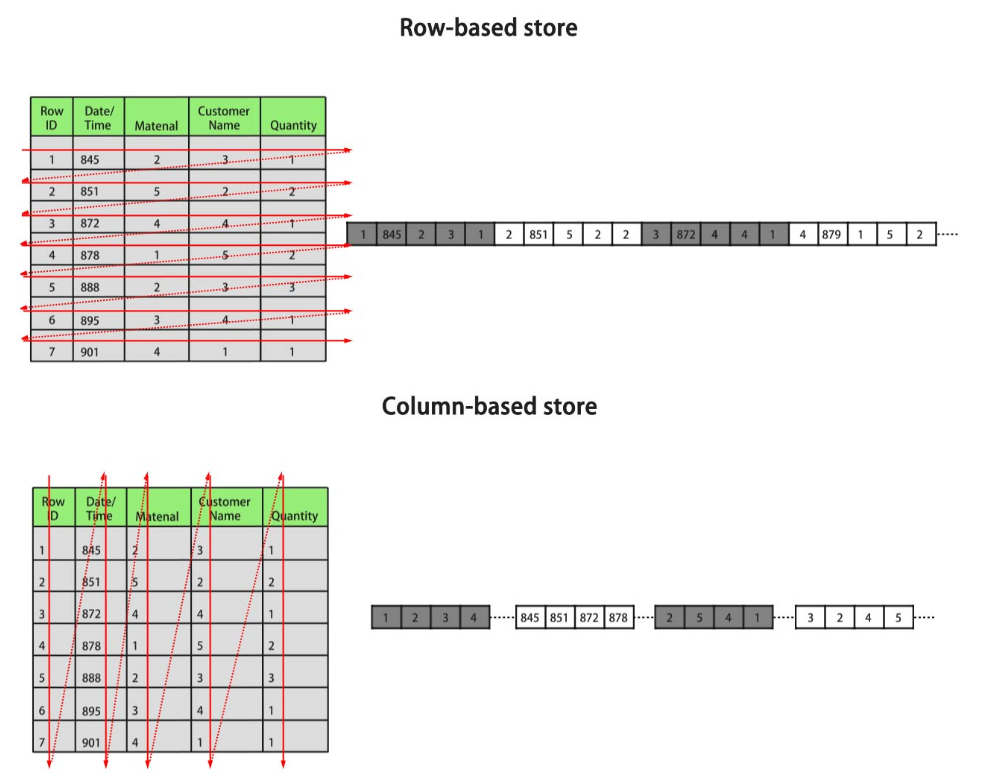
2.2 行存储和列存储的优点和缺点?
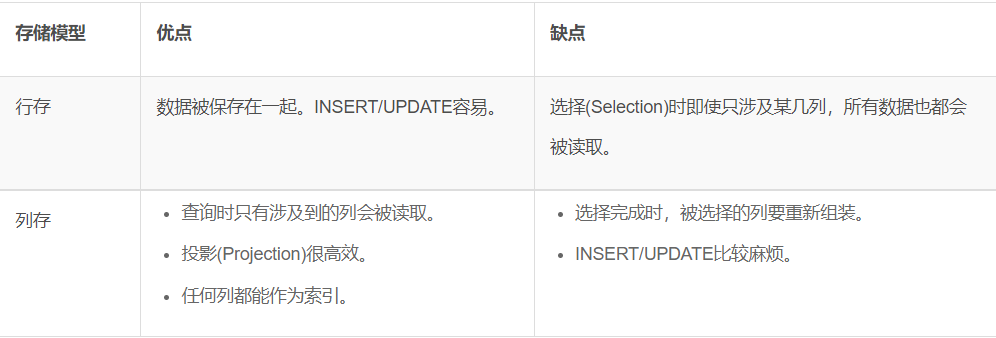
也就是说,对于很多字段的查询,还是行存储好一点。 反之,查询字段+where字段很少的情况下,使用列存储更优。 对于查询而言,如果都是全表扫描的情况下,查询一个字段,那么列存更优吗? 为什么? 如果对于一个表的存储方式没有本质区别,一个表=一个大的存储单位,那么内部如何加快的? 这个我暂时自己也不清楚,后续有时间测试一下。 有小伙伴有兴趣的可以测试一下? 查询一个字段,全表扫描,列存储是否优于行存? 为什么?
我们看官方文档的解释定义,查询时只有涉及到的列会被读取。 如果是oracle全表扫描,非分区表,一个segments,那么不论数据是否符合都是全部读取一遍。 那么,从这个官方文档的说明来看,可能性2中,1.每个列一个segments;2.内部存储里面,有条件过滤只访问某些blocks.
小结的话就是,对于修改频繁使用行存,大量少量列的查询,列存储更好! 大批量插入数据列存储也更好!
2.3 Opengauss如何创建表指定行存储还是列存储呢?
–默认行存储
postgres=# CREATE TABLE customer_t1
(
state_ID CHAR(2),
state_NAME VARCHAR2(40),
area_ID NUMBER
);
–删除表
postgres=# DROP TABLE customer_t1;
–列存储需要指定
postgres=# CREATE TABLE customer_t2
(
state_ID CHAR(2),
state_NAME VARCHAR2(40),
area_ID NUMBER
)
WITH (ORIENTATION = COLUMN);
–删除表
postgres=# DROP TABLE customer_t2;
2.4 压缩的情况
参考
https://opengauss.org/zh/docs/2.0.0/docs/CharacteristicDescription/%E8%A1%8C%E5%88%97%E6%B7%B7%E5%90%88%E5%AD%98%E5%82%A8.html
https://opengauss.org/zh/docs/2.0.0/docs/Description/%E4%BC%81%E4%B8%9A%E7%BA%A7%E5%A2%9E%E5%BC%BA%E7%89%B9%E6%80%A7.html
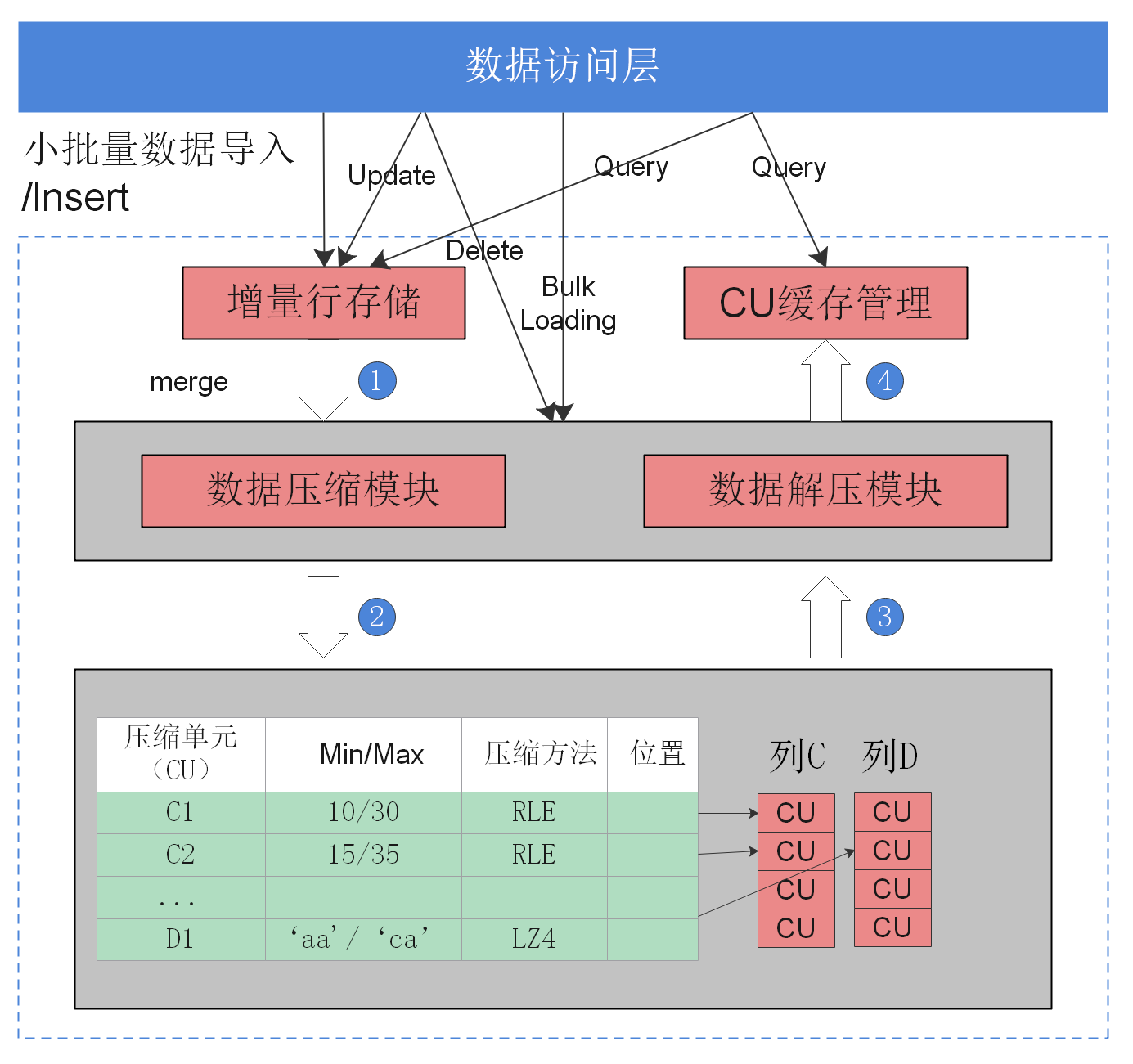
版本2.0.0的一些限制,以及标识列存储引擎的压缩支持选项
当前列存储引擎有以下约束:
DDL仅支持CREATE/DROP/TRUNCATE TABLE的功能。
兼容分区的DDL管理功能(如: ADD/DROP/MERGE PARTITION,EXCHANGE功能)。
支持CREATE TABLE LIKE语法。
支持ALTER TABLE的部分语法。
其他功能都不支持。
DML支持UPDATE/COPY/BULKLOAD/DELETE。
不支持触发器,不支持主外键。
支持Psort index、B-tree index和GIN index,具体约束参见《开发者指南》中“SQL参考 > SQL语法 > CREATE INDEX”章节。
列存下的数据压缩
对于非活跃的早期数据可以通过压缩来减少空间占用,降低采购和运维成本。
openGauss列存储压缩支持Delta Value Encoding、Dictionary、RLE 、LZ4、ZLIB等压缩算法,且能够根据数据特征自适应的选择压缩算法,平均压缩比7:1。压缩数据可直接访问,对业务透明,极大缩短历史数据访问的准备时间
学习官方文档记得收藏哈
https://opengauss.org/zh/docs/2.0.1/docs/Quickstart/Quickstart.html



