




背景
离群点检测算法具有非常强的实际意义和广泛的应用前景,包括欺诈检测、网络性能和活动监控等等。
📢 「离群点」和「噪声」有区别:噪声是观测值的随机误差和方差;离群点属于观测值,可能是真实数据产生或者噪声产生,整体而言是和大部分观测值明显不同的观测值。
本文主要学习下「基于密度的离群点检测方法」中最具有代表性的算法:「局部离群因子检测算法」 (Local Outlier Factor, LOF) [^1]。
LOF 算法
基于密度的离群点检测方法基本假设:非离群点对象周围的密度与其邻域周围的密度类似,而离群点对象周围的密度显著不同于其邻域周围的密度。 如下图所示:
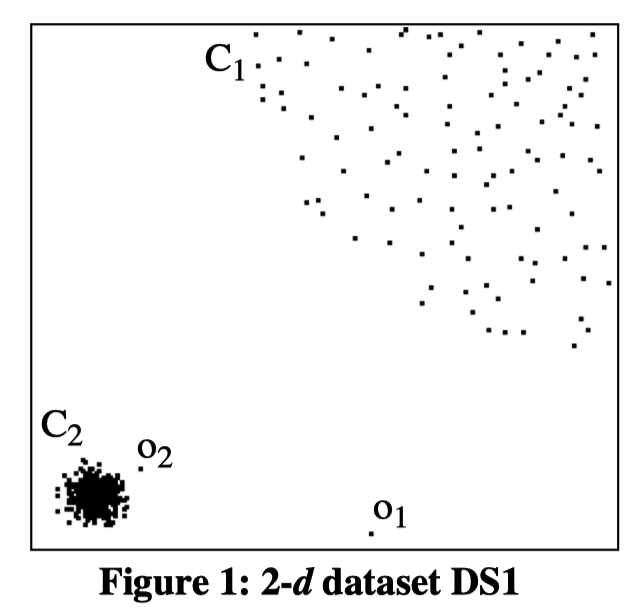
局部离群因子检测算法 LOF 是一种典型的基于密度的高精度离群点检测方法,通过给每个数据点都分配一个依赖于邻域密度的离群因子 ,进而判断该数据点是否为离群点。若 ,则该数据点为离群点;若 ,则该数据点为正常数据点。
假设当前的样本集合 包含 个数据点,其数据维度为 ,数据点表示为
LOF 算法需要度量不同数据点间的距离 ,至于距离度量可以采用欧式距离、汉明距离、马氏距离等等。为了简明仅给出欧式距离计算公式如下:
在介绍 LOF 算法前先引用几个重要的概念 ^2。
「第 距离」
定义:设 为数 的第 距离
即:点 是距离点 最近的第 个点。
「 距离邻域」
定义:设 为点 的第 距离邻域,满足条件
即: 中所有到点 距离不大于 的点集合。
「可达距离」
定义:以点 为中心,点 到点 的第 可达距离定义为
即:点 到点 的第 可达距离至少为 ,距离 最近的 个点到 的可达距离被认为是相等的为等于 。
「局部密度可达」
定义:局部密度可达为
即:点 的第 邻域内所有点到 的平均可达距离。如果 和周围邻域点是同一簇,那么可达距离越可能为较小的 ,导致可达距离之和越小,局部可达密度越大。如果 和周围邻域点较远,那么可达距离可能会取较大值 ,导致可达距离之和越大,局部可达密度越小。
📢 注意:关于局部可达密度的定义其实暗含假设,即:不存在大于等于 个重复的点,这些重复点的平均可达距离为零,局部可达密度就变为无穷大。解决方法是可以将可达距离加上非常小的值。
根据以上定义,LOF 计算公式如下
即:点 的邻域 内其他点的局部可达密度与点 的局部可达密度之比的平均数。如果这个比值越接近 1,说明 的邻域点密度差不多, 可能和邻域同属一簇;如果这个比值小于1,说明 的密度高于其邻域点密度为密集点;如果这个比值大于 1,说明 的密度小于其邻域点密度可能是异常点。
LOF 算法需要计算数据点对间的距离,整个算法时间复杂度为 。为了提高算法效率,FastLOF[^3] 算法对其进行改进。主要思路先将数据集划分为多个子集,再分别计算 LOF 分数,剔除异常分数小于 1 的再进行计算,详情可以参考原文。
Python 实践
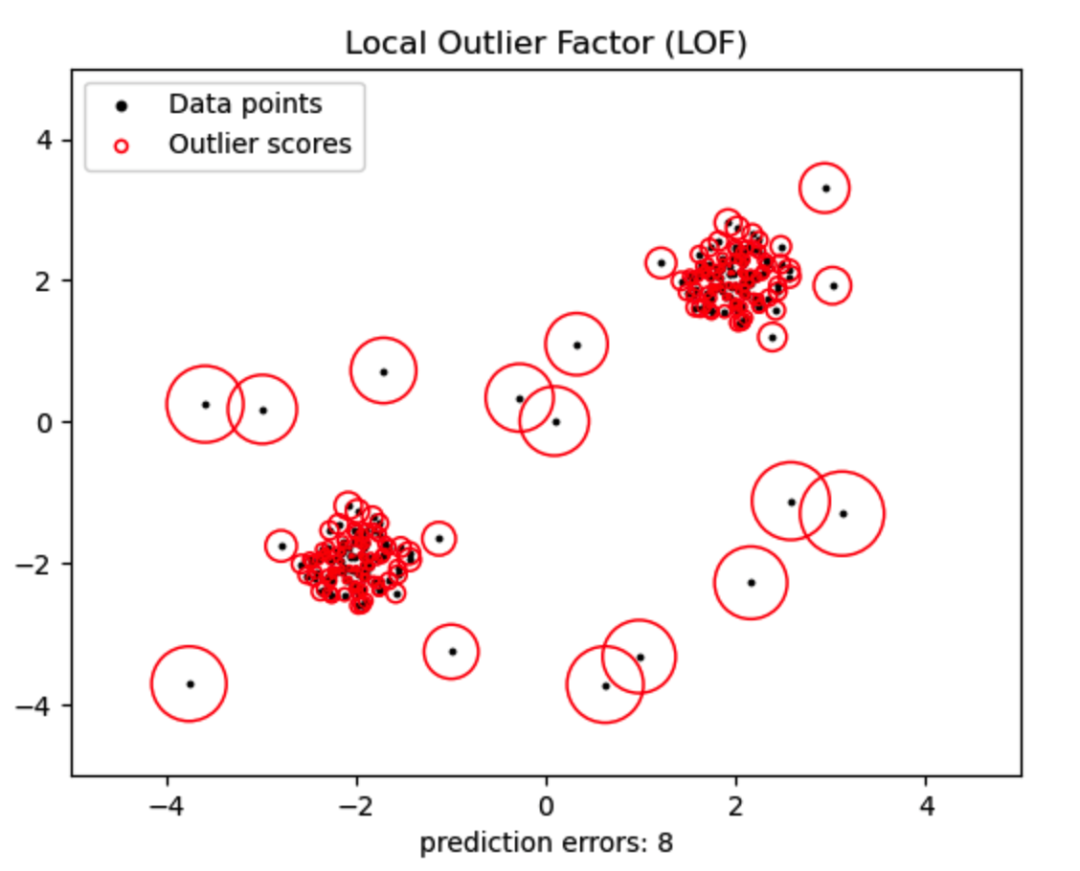
为了方便此处直接采用 Scikit-learn 中提供的包测试算法效果。
采用人工生成的离群点数据测试,代码如下所示:
# Generate train data
X_inliers = 0.3 * np.random.randn(100, 2)
X_inliers = np.r_[X_inliers + 2, X_inliers - 2]
# Generate some outliers
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
X = np.r_[X_inliers, X_outliers]
n_outliers = len(X_outliers)
ground_truth = np.ones(len(X), dtype=int)
ground_truth[-n_outliers:] = -1
clf = LocalOutlierFactor(n_neighbors=20, contamination=0.1)
y_pred = clf.fit_predict(X)
n_errors = (y_pred != ground_truth).sum()
X_scores = clf.negative_outlier_factor_
plt.title("Local Outlier Factor (LOF)")
plt.scatter(X[:, 0], X[:, 1], color="k", s=3.0, label="Data points")
# plot circles with radius proportional to the outlier scores
radius = (X_scores.max() - X_scores) / (X_scores.max() - X_scores.min())
plt.scatter(
X[:, 0], X[:, 1], s=1000 * radius, edgecolors="r", facecolors="none", label="Outlier scores"
)
plt.axis("tight")
plt.xlim((-5, 5))
plt.ylim((-5, 5))
plt.xlabel("prediction errors: %d" % (n_errors))
legend = plt.legend(loc="upper left")
legend.legendHandles[0]._sizes = [10]
legend.legendHandles[1]._sizes = [20]
plt.show()
对应的实验结果如下:
[^1]: M. M. Breunig, H. P. Kriegel, R. T. Ng, J. Sander. LOF: Identifying Density-based Local Outliers SIGMOD, 2000.
[^3]: M. Goldstein. FastLOF: An Expectation-Maximization based Local Outlier detection algorithm. ICPR, 2012

● KDD 2021丨RANSynCoder:异步多变量时间序列异常检测与定位模型
● KDD 2020 | MTGNN: 基于图神经网络的多变量时间序列预测模型

 「阅读原文」留言哦!
「阅读原文」留言哦! 

