




首先放一个MySQL官档中提供的InnoDB体系架构图:(MySQL 5.7)
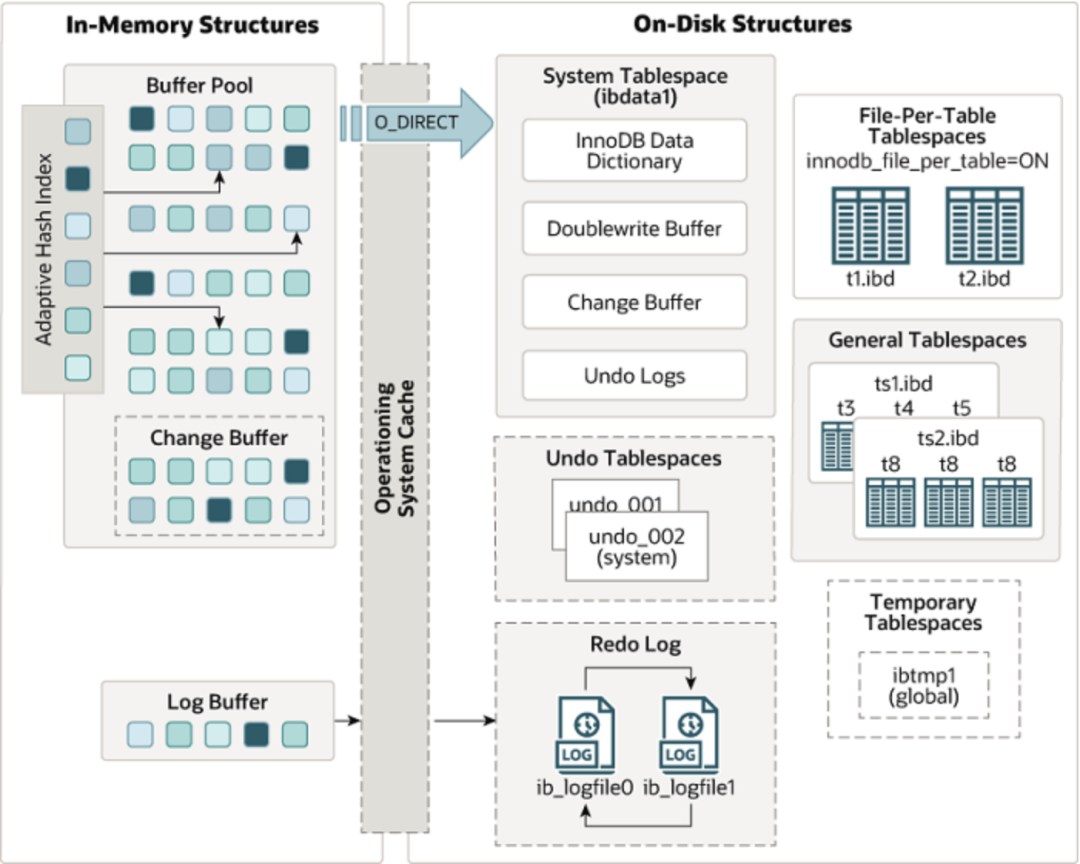
(https://dev.mysql.com/doc/refman/5.7/en/innodb-architecture.html)
本文摘录自:
58沈剑-架构师之路-公众号文章《缓冲池(buffer pool),这次彻底懂了!!!》
八怪(高鹏)-《深入理解MySQL主从原理》

InnoDB Buffer Pool介绍
再来看一张图:
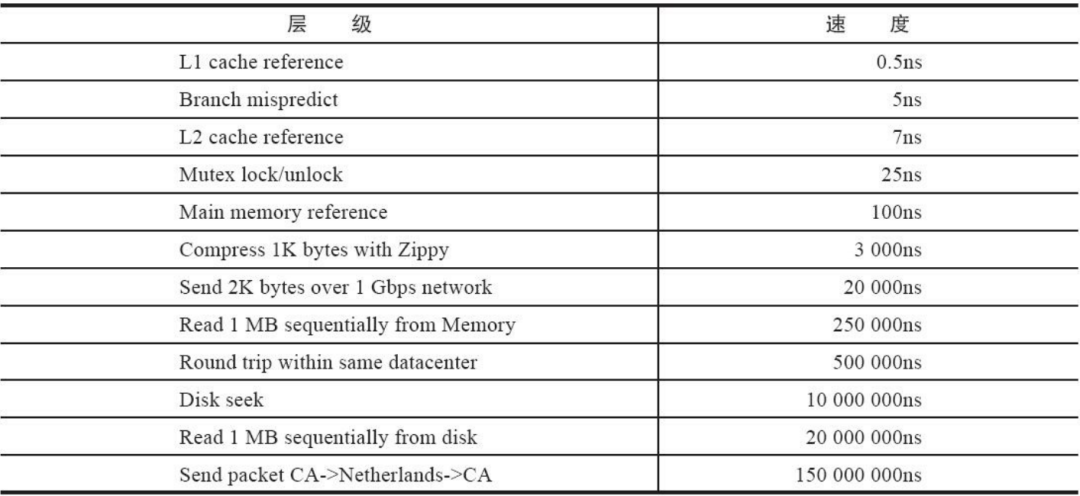
预备知识必知(预读与传统LRU算法)
速度快,那直接把所有数据都放到缓冲池里不就行了?
预读
相较于磁盘的容量和速度。内存虽快,但容量小、价格贵的缺点还存在。所以就要考虑如何管理与淘汰缓冲池,使得性能最大化(如何让有限的空间做更多的事情)。
在介绍具体细节之前,先介绍下“预读”的概念。
什么是预读?
操作系统的磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K),如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。
预读为什么有效?
数据访问,通常都遵循“集中读写”的原则,使用一些数据,大概率会使用附近的数据,这就是所谓的“局部性原理”,它表明提前加载是有效的,确实能够减少磁盘IO。
按页(4K)读取,和InnoDB的缓冲池设计有啥关系?
1、磁盘访问按页读取能够提高性能,所以缓冲池一般也是按页缓存数据;
2、预读机制启示了我们,能把一些“可能要访问”的页提前加入缓冲池,避免未来的磁盘IO操作;
LRU(Least Rrecently Used)
知道了缓冲池是以页为单位缓存数据的,往里放有了,那么又是如何淘汰的呢?最容易想到的,就是LRU(Least Rrecently Used)算法——最近、最少使用原则。
传统LRU(常见包含如Memcache、OS)的缓冲页管理方式:把入缓冲池的页放到LRU的头部,作为最近访问的元素,从而最晚被淘汰。这里又分两种情况:
1、页已经在缓冲池里,那就只做“移至”LRU头部的动作,而没有页被淘汰。
2、页不在缓冲池里,除了做“放入”LRU头部的动作,还要做“淘汰”LRU尾部页的动作。

假如,接下来要访问的数据在页号为4的页中:

情况一:
1、页号为4的页,本来就在缓冲池里;
2、把页号为4的页,放到LRU的头部即可,没有页被淘汰;
提示:为了减少数据移动,LRU一般用链表实现。
假如,再接下来要访问的数据在页号为50的页中:

情况二:
1、页号为50的页,原来不在缓冲池里;
2、把页号为50的页,放到LRU头部,同时淘汰尾部页号为10的页。
MySQL中的LRU
MySQL针对预读失效的LRU优化
知道了预读失效的弊端,该如何对预读失效进行优化?
要优化预读失效,思路是:
1、让预读失败的页,停留在缓冲池LRU里的时间尽可能短;
2、让真正被读取的页,才挪到缓冲池LRU的头部;
MySQL的具体实现方法是:
1、将LRU分为两个部分:
①新生代(New Sublist)
②老生代(Old Sublist)
2、新老生代收尾相连,即:新生代的尾(Tail)连接着老生代的头(Head);
3、新页(例如被预读的页)加入缓冲池时,只加入到老生代头部:
* 如果数据真正被读取(预读成功),才会加入到新生代的头部
* 如果数据没有被读取,则会比新生代里的“热数据页”更早被淘汰出缓冲池
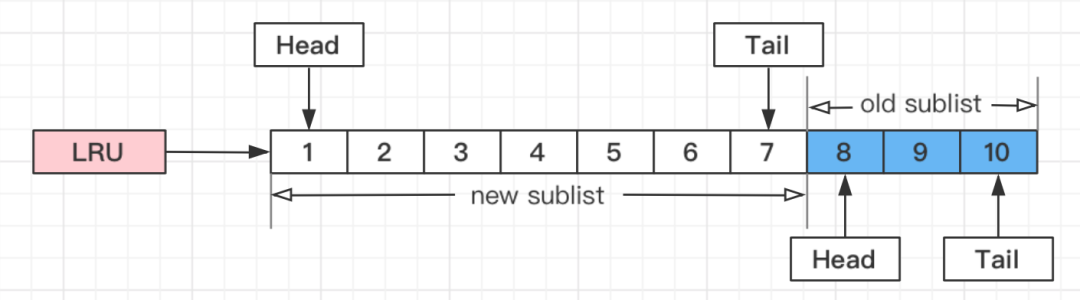
a. 整个LRU长度是10;
b. 前70%是新生代;
c. 后30%是老生代;
d. 新老生代首尾相连;
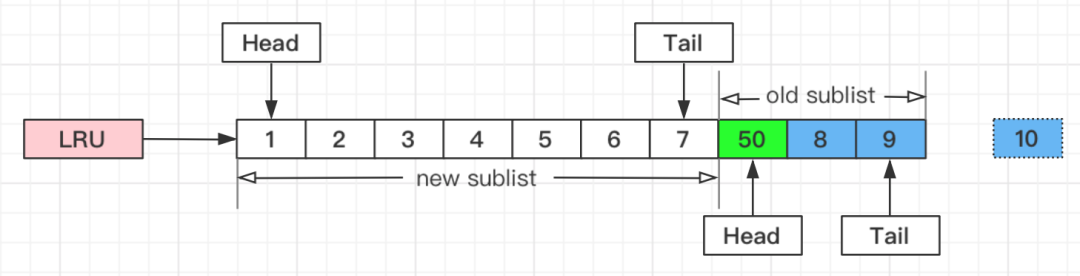
假如有一个页号为50的新页被预读加入缓冲池:
情况一:
1、50只会从老生代头部插入,老生代尾部(也是整体尾部)的页会被淘汰掉;
2、假设50这一页不会被真正读取,即预读失败,它将比新生代的数据更早淘汰出缓冲池;
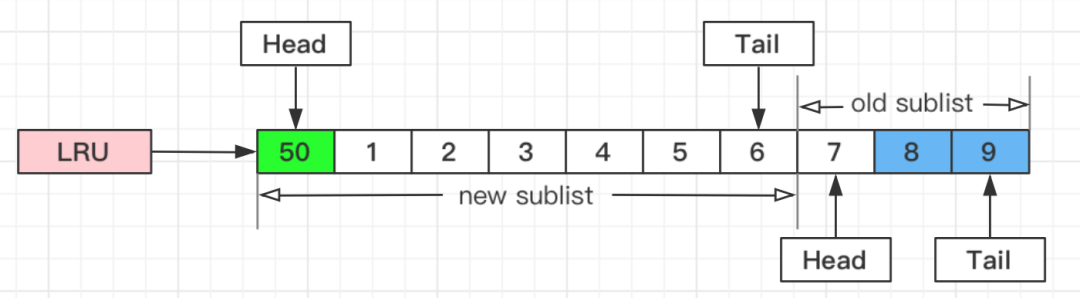
情况二: 假如50这一页立刻被读取到,例如SQL访问了页内的行row数据: 1、它会被立刻加入到新生代的头部; 2、新生代的页会被挤到老生代,此时并不会有页面被真正淘汰;
改进版缓冲池LRU能够很好的解决“预读失败”的问题。但也不要因噎废食,因为害怕预读失败而取消预读策略,大部分情况下,局部性原理是成立的,预读是有效的。但是,新老生代改进版LRU仍然解决不了缓冲池污染的问题。
MySQL针对缓冲池污染的LRU优化
SELECT * FROM student WHERE student_name LIKE '%路%';
虽然结果集可能只有少量数据,但这类like不能命中索引,必须全表扫描,就需要访问大量的页:
1、把页加到缓冲池(插入老生代头部);
2、从页里读出相关的row(插入新生代头部);
3、row里的student_name字段和字符串'路'进行比较,如果符合条件,加入到结果集中;
4、直到扫描完所有页中的所有row。
如此一来,所有的数据页都会被加载到新生代的头部,但只会访问一次,真正的热数据被大量换出。
怎么这类扫码大量数据导致的缓冲池污染问题呢?
MySQL缓冲池加入了一个“老生代停留时间窗口”的机制:
1、假设T=老生代停留时间窗口;
2、插入老生代头部的页,即使立刻被访问,并不会立刻放入新生代头部;
3、只有满足“被访问”并且“在老生代停留时间”大于T,才会被放入新生代头部;
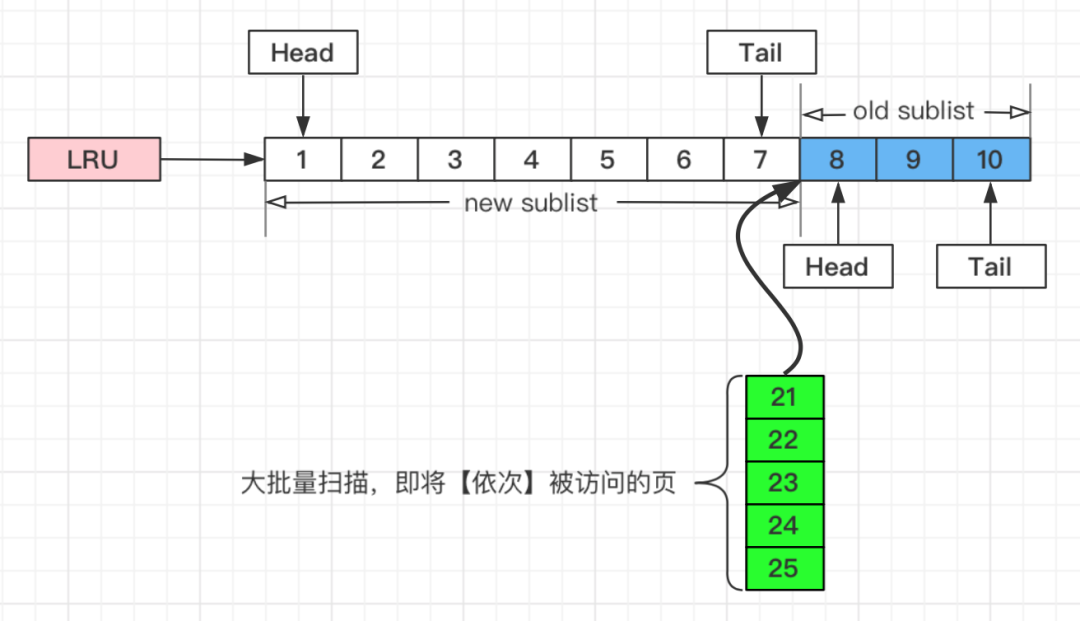
↑假如批量数据扫描,有21,22,23,24,25等五个页面将要依次被访问。

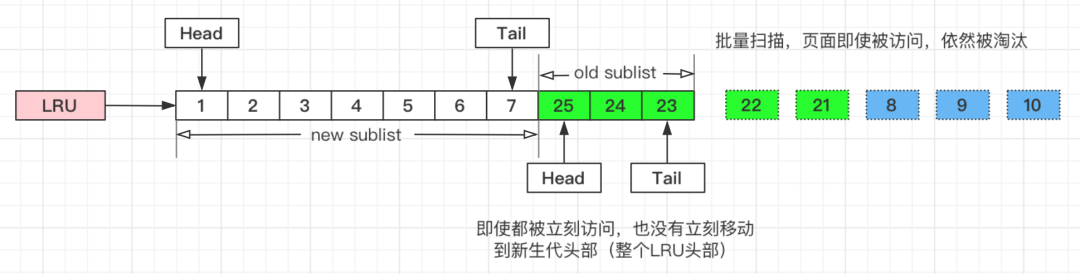
↑加入“老生代停留时间窗口”策略后,短时间内被大量加载的页,并不会立刻插入新生代头部,而是优先淘汰那些,短期内仅仅访问了一次的页。
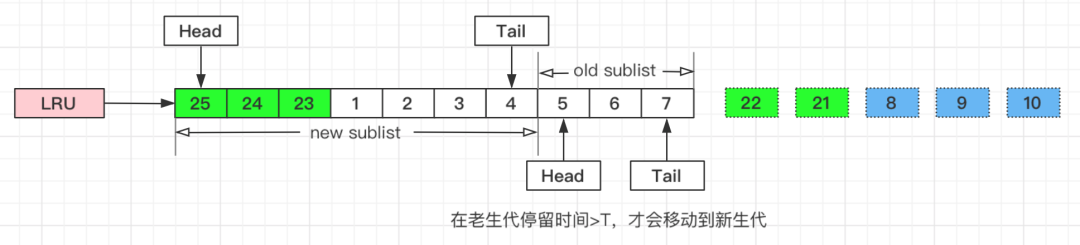
↑而只有在老生代呆的时间足够久,停留时间大于T,才会被插入新生代头部。
InnoDB里涉及LRU的重要的参数
SHOW VARIABLES LIKE '%innodb_buffer_pool_size%';SHOW VARIABLES LIKE '%innodb_old_blocks_pct%';SHOW VARIABLES LIKE '%innodb_old_blocks_time%';
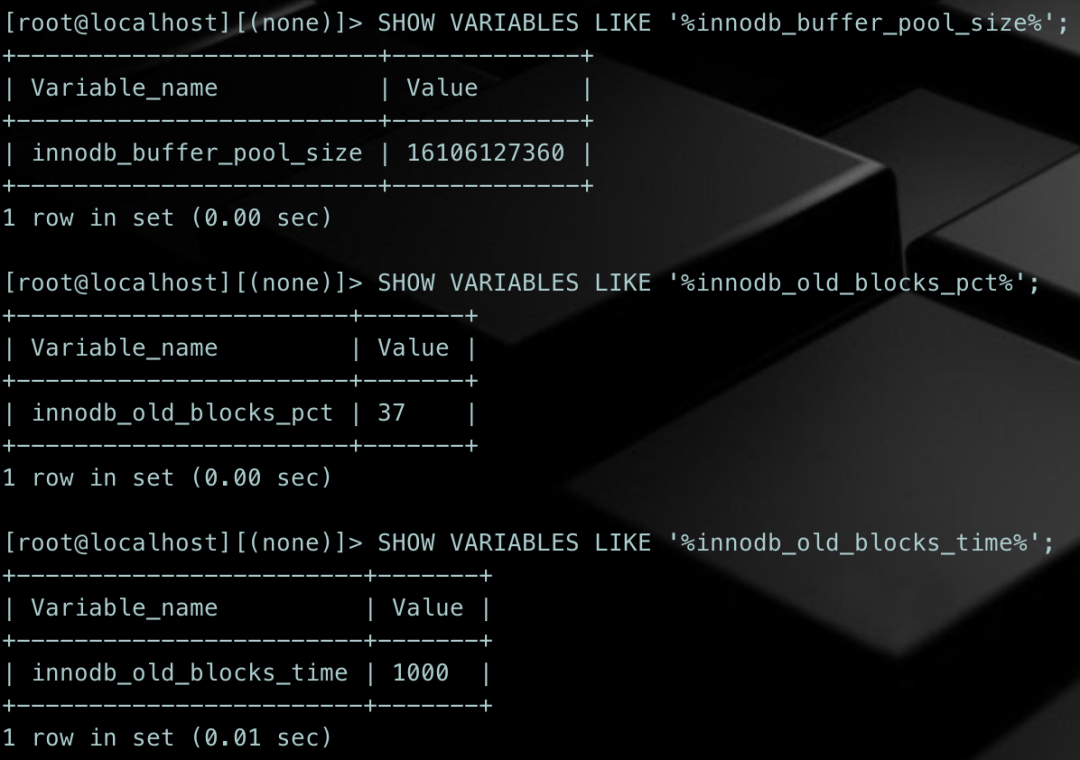
参数:innodb_buffer_pool_size
参数:innodb_old_blocks_pct
参数:innodb_old_blocks_time
知识补充
三种Page
LRU链表知识点补充
从上面我们知道,LRU分成两部分,一个是New Sublist新生代,也可以称之为Young链表;另一个是Old Sublist老生代,也可以称之为Old链表。新老生代首尾相连,连接处的位置叫做Midpoint(当被访问的数据页被加载到Buffer Pool的时候,数据页加载的位置就是Midpoint,即Old链表的首部,Young链表的尾部)。
MySQL中提供了Buffer Pool的一些监控指标,可以通过下面的命令进行查看:
SHOW ENGINE INNODB STATUS\G
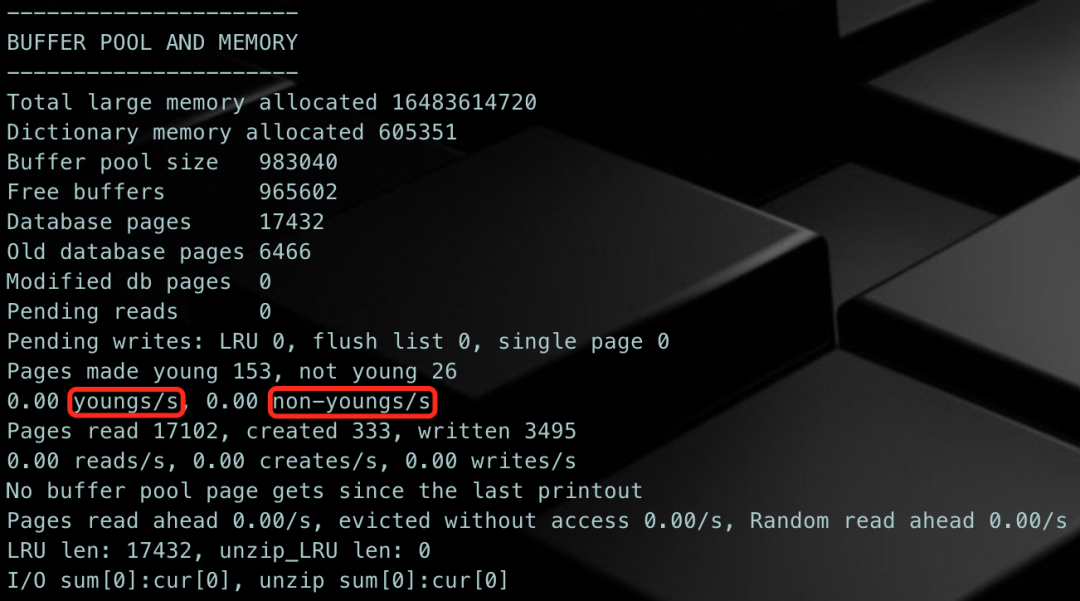
1、如果一个数据页已经处于Young链表,当它再次被访问的时候,只有当其处于Young链表长度的1/4(大约值)之后,才会被移动到Young链表的头部。这样做的目的是减少对LRU链表的修改,因为LRU链表的目标是保证经常被访问的数据页不会被淘汰。
2、innodb_old_blocks_time控制的是Old链表头部页面的转移策略。该Page需要在Old链表停留超过innodb_old_blocks_time时间,之后再次被访问,才会移动到Young链表。这样操作是避免Young链表被那些只在innodb_old_blocks_time时间间隔内频繁访问,之后就不被访问的页面塞满,从而有效的保护Young链表。
3、在全表扫描或者全索引扫描的时候,InnoDB会将大量的页面写入LRU链表的Midppoint位置,并且在短时间内访问几次之后就不再访问了。设置innodb_old_blocks_time的时间窗口可以有效保护Young List,保证了真正频繁访问的页面不被淘汰。
4、当扫描的表很大,Buffer Pool都放不下时,可以将innodb_old_blocks_pct设置为较小的值,这样只读取一次的数据页就不会占据大部分的Buffer Pool。例如,设置innodb_old_blocks_pct=5,会将仅读取一次的数据页在Buffer Pool的占用限制为5%。
5、当经常扫描一些小表时,这些页面在Buffer Pool移动的开销较小,我们可以适当调大innodb_old_blocks_pct,例如,设置innodb_old_blocks_pct=50%。
6、每间隔1秒,Page Cleaner线程执行LRU List Flush的操作,来释放足够的Free Page、innodb_lru_sacn_depth变量控制每个Buffer Pool实例每次扫描LRU List的长度,来寻找对应的脏页,执行Flush操作。
Flush链表
Free链表
LRU链表和Flush链表的区别
1、LRU链表flush,由用户线程触发(MySQL 5.6.2之前);而Flush链表flush由MySQL数据库InnoDB存储引擎后台srv_master线程处理。(在MySQL 5.6.2之后,都被迁移到Page Cleaner线程中)。
2、LRU链表flush,其目的是为了写出LRU链表尾部的脏页,释放足够的空闲页,当Buffer Pool满的时候,用户可以立即获得空闲页面,而不需要长时间等待;Flush链表flush,其目的是推进Checkpoint LSN,使得InnoDB系统崩溃之后能快速的恢复。
3、LRU链表flush,其写出的脏页,需要从LRU链表中删除,移动到Free链表;Flush链表flush,不需要移动Page在LRU链表中的位置。
4、LRU链表flush,每次flush的脏页数量较少,基本固定,只要释放一定的空闲空间即可;FLUSH链表flush,根据当前系统的更新繁忙程度,动态调整一次flush的脏页数量,量很大。
5、在Flush链表上的页面一定在LRU链表上,反之则不成立。
小结
将缓冲池分为New Sublist(新生代/Young)和Old Sublist(老生代/Old),入缓冲池的Page,优先从Midpoint进入Old Sublist,Page被访问,才进入New Sublist,以解决预读(Read-Ahead)失效的问题。 Page被访问,且在Old Sublist停留时间超过配置innodb_old_blocks_time阀值时,才进入New Sublist,以解决批量数据访问,大量数据淘汰的问题。


end
