




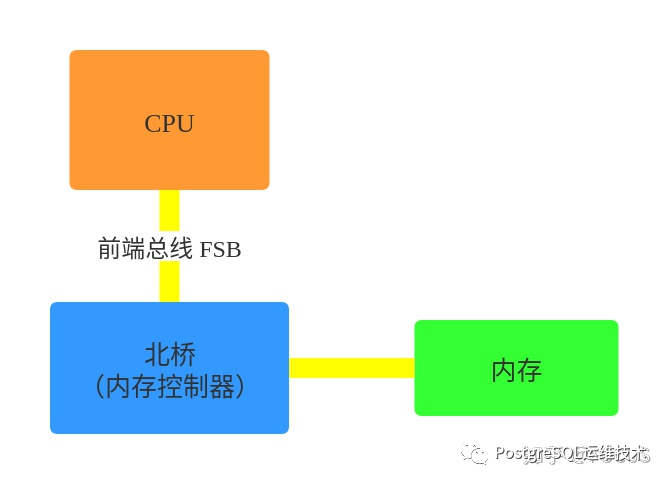
在单cpu的时代,cpu与内存的交互需要通过北桥芯片来完成。cpu通过前端总线(FSB, front Side Bus)连接到北桥芯片,由北桥芯片连接到内存(内存控制器是集成在北桥芯片里的)。
 图片来源:https://zhuanlan.zhihu.com/p/336365600
图片来源:https://zhuanlan.zhihu.com/p/336365600
为了提升性能,cpu的频率不断提高,后又向多核发展。多核也是共享一个北桥来读取内存。在多处理器的系统里,多个cpu共享相同的物理内存,每个cpu访问内存的任何时间所需时间相同,这种架构被称为一致性内存访问模型(Uniform-memory-Access, 简称UMA)。
UMA服务器的主要特征是共享,系统中的资源cpu、内存、io等都是共享的,这就导致了它的扩展能力是有限的,对它而言,每一个共享的环节都是造成其扩展的瓶颈。尤其是,随着核数的增多,cpu对总线、北桥(内存控制器)的争用越来越激烈,它们在响应时间上的性能瓶颈越来越明显。
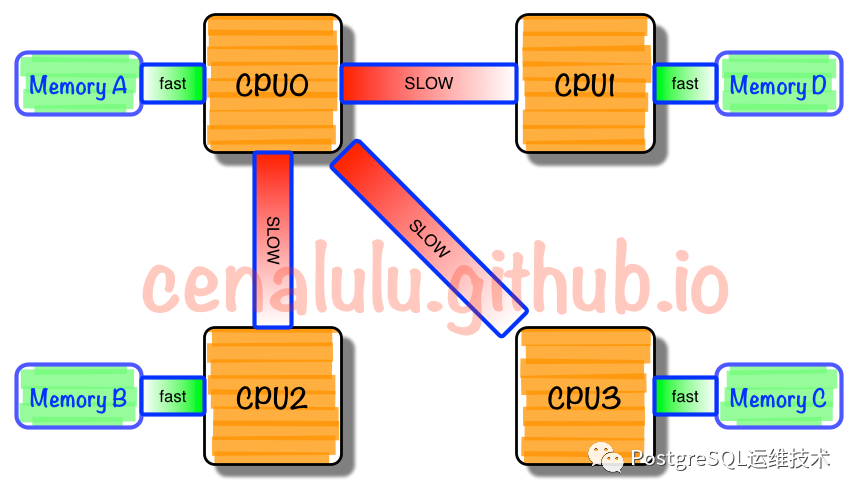
为了消除UMA架构的瓶颈,硬件工程师将原集成在北桥芯片中的内存控制器进行了拆分,将其集成到cpu中,一般一个cpu socket都有一个独立的内存控制器,每个cpu socket也独立连接到一部分对立的内存,这部分CPU直连的内存被称为本地内存。cpu之间通过QPI总线连接,CPU 可以通过 QPI 总线访问不和自己直连的“远程内存”。
图片来源:http://cenalulu.github.io/linux/numa/
这种架构模型,cpu访问本地内存与远程内存所用的时间是不一样的,一般访问本地内存要比访问远程内存快,因此也被称做非一致或非均匀内存访问模型(Nonuniform-Memory-Access, 简称NUMA)。
UMA使用单内存控制器,占用内存带宽有限。而NUMA机器通过使用多个内存控制器来增强内存的可用带宽。
我们可以通过numactl -H命令查看机器上的NUMA节点。
$ numactl -H
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35
node 0 size: 63539 MB
node 0 free: 18566 MB
node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45 46 47
node 1 size: 64485 MB
node 1 free: 20716 MB
node distances:
node 0 1
0: 10 21
1: 21 10复制
如上图所示,
CPU被分成node 0 和node 1 两组(这台机器有两个CPU Socket)。 node 0 CPU分配到63539+18566=82105MB的内存,node 1 CPU分配到64485+20716=85201MB的内存。 node distances 是一个二维矩阵,node[i][j] 表示 node i 访问 node j 的内存的相对距离。比如 node 0 访问 node 0 的内存的距离是 10,而 node 0 访问 node 1 的内存的距离是 21。
所以如果node 0 上的进程如果在node 1上分配内存,会增加进程的延迟。
基于Numa的特性,我们可以看到,NUMA的CPU和内存策略将会影响到系统的稳定性。在 Linux 系统中,我们可以使用 numactl命令来设置两者。
Numa的CPU策略
cpunodebind:将进程绑定到某几个NUMA节点上; physcpubind:将进程绑定到某几个物理 CPU 上;
Numa的内存策略
localalloc:总是在当前节点上分配内存; preferred :倾向于在特定节点上分配内存,当指定节点的内存不足时,操作系统会在其他节点上分配; membind:只能在传入的几个节点上分配内存,当指定节点的内存不足时,内存的分配就会失败; interleave:内存会在传入的节点上依次轮询,当指定节点的内存不足时,操作系统会在其他节点上分配;
查看当前系统的numa策略
$ numactl -show
policy: default
preferred node: current
physcpubind: 0 1
cpubind: 0
nodebind: 0
membind: 0复制
NUMA可以为我们解决UMA架构中总线、北桥带来的性能瓶颈,但是如果使用了不合适的CPU或内存策略,也会带来一些问题。
常讨论的一个问题是:Numa架构下,数据库等大量依赖内存的应用,因为内存分配不均以及numa reclaim回收策略导致频繁发生交换分区,而使服务出现延迟。
可参考如下两篇文章:
Mysql: https://blog.jcole.us/2010/09/28/mysql-swap-insanity-and-the-numa-architecture/ PostgreSQL:http://frosty-postgres.blogspot.com/2012/08/postgresql-numa-and-zone-reclaim-mode.html
 图片来源:https://draveness.me/whys-the-design-numa-performance
图片来源:https://draveness.me/whys-the-design-numa-performance
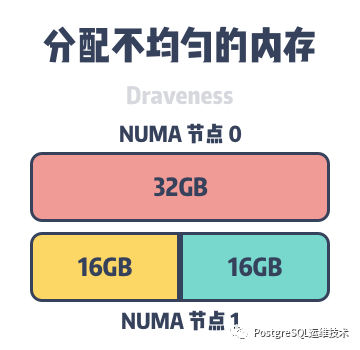
以PG为例,如上图所示,假设主机上包含两个 NUMA 节点,其中每个节点都有 32GB 的内存,并且numa的内存分配策略是优先从本地分配内存。shared_buffer占用 48GB 的内存时,它会在 NUMA 节点0 和 NUMA 节点1 分别分配 32GB 和 16GB 的内存。
虽然48GB的内存没有到达主机64GB的内存上限,但是当某些数据必须要在 NUMA 节点0的内存上分配时,就会导致 NUMA 节点0中的内存被交换出内存为新的内存请求让出位置,shared_buffer的内存的频繁换入和换出会使服务器的性能下降。
这个现象关系到两个问题:一是内存分配不均;二内存的回收策略的问题。
内存分配不均
对于内存分配不均这一点,我们可以设置numactl的内存分配策略为interleave=all。表示内存会在所有节点上依次轮询,当指定节点的内存不足时,操作系统会在其他节点上分配。
使用该内存分配策略会使得内存均匀地分配到不同的NUMA节点上,能够降低页面频繁换入换出的可能性。
numactl --interleave=all复制
内存的回收策略
Linux的vm.zone_reclaim_mode, 该设置表示在NUMA节点内存不足时内存的回收策略。
vm.zone_reclaim_mode:当一个内存区域(zone)内部的内存耗尽时,是从其内部进行内存回收还是可以从其他zone进行回收的选项,0表示可以从下一个zone找可用内存;
对于数据库应用来说,一般将其设置为0。
vm.zone_reclaim_mode = 0复制
参考文档
https://cloud.tencent.com/developer/article/1372348
http://cenalulu.github.io/linux/numa/
https://zhuanlan.zhihu.com/p/336365600
