




众所周知,Elasticsearch返回的结果其实根据其相关性进行排序的。所以这里就会涉及到一个概念,就是相关性是怎么定义的,也就是说凭什么这个结果的相关性就比另一个结果的相关性好。本文就来针对这个问题详细介绍一下。
什么是相关性
Elasticsearch中的相关性是通过一个浮点的数值_score来显示的,这个_score的值越大,就表示相关性越高。那这个_score的值是如何计算的呢?我们通常在全文本查询的时候,使用的是标准相似算法,它的名字是TF/IDF(term frequency/inverse document frequency),它包含下面三个重要的方面:
Term frequency:我们所查的term在这个field中出现的次数,通常来说,出现的次数越多,则相关性越高。
Inverse document frequency:我们所查的term在整个index中出现的频率,出现的频率越高,则相关性越低。这个可以理解,所谓物以稀为贵就是这个道理。
Fiel-length norm:这个是用来看field的长度的,field的长度越大,则相关性越高。好吧,什么时候专一都是一个好的品质。
当然TF/IDF不是决定score的唯一因素,这里还有很多别的影响因素,比如说fuzzy查询中的term相似度等等。那么在实践中,我们如何才能知道score都是由哪些部分决定的呢?
理解Score
我们在实际工作中可以通过下面的explain参数来具体查看score是如何得到的。

在返回的结果中就会包含一个explanation的域如下所示,其中description就是计算使用的类型,value就是score的结果,details就详细记录了各个子计算的情况。你可以看到我们上面提到的TF/IDF/FLN的结果各是什么,最终的score(value)就是基于这三个结果计算出来的。

Score的算法介绍
这个时候也许你就会好奇,上面这些1,0.30685282以及0.25都是怎么算出来的。这节我们就一起来看看具体的算法:
Term Frequency
我们上面也提到对TF来说就是它在整个field中出现的次数,越多则分数越高。它的值是通过这个公式来计算的:

其实就是出现的次数开方就得到了最终的值。
Inverse document frequency
IDF是说出现在越多的field中,那么分数就越低。所以它是通过下面公式进行计算的:

其中numDocs就是index有多少个documents,docFreq就是有多少个document中有这个term,很明显,docFreq越大,这个值就越小。
Field-length norm
FIN是说field的长度越大,则分数越小。所以它使用的公式如下所示:

很简单,term长度取根号之后被1除。很显然,长度越长,数值越小。
三者结合计算
有了上面三个值的计算方法之后,我们来看一下他们三个是如何计算出最终的score值的。我们先来看一个最简单的例子,就是我们只搜索了一个term:

就是在quickbrown box中搜索fox,那么它得到的结果就如下所示:
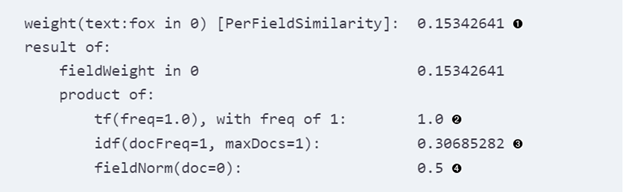
总得分数是0.15342641,其实就是下面的三个tf*idf*filedNorm。
Tf的值,因为fox就出现了一次,所以开根号之后还是1。
总共就一个documents,所以numDocs=1,出现fox的documents也是1,所以,根据上面的结果就可以得到对应的结果是0.30685282
这里的总的terms是3,然后根据上面的计算可以得到结果是0.5
向量空间模型
上面的例子就是一个简单的term的情况,而事实上,我们一般会同时搜索多个词,这个时候的score如何计算呢?一个常见的方法就是使用向量空间模型,说白了就是给每个词一个权重,然后根据权重来计算最终的score值。
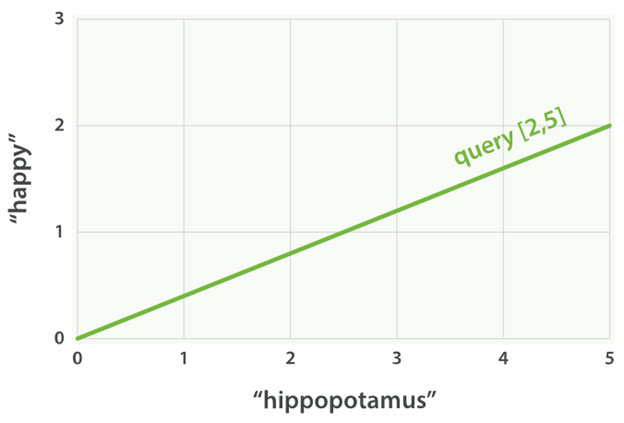
比如说我们搜索happy hippopotamus这两个词,显然我们认为hippopotamus这个词的权重会大一点,比如我们给happy赋予的权重是2,hippopotamus赋予的权重是5,那么这里的向量值就是[2,5]。我们把它画到一个二维图中就如下所示:
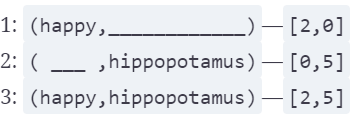
现在我们假设我们有以下几个documents:
I am happy in summer.
After Christmas I’m a hippopotamus.
The happy hippopotamus helped Harry.
这样我们就可以根据这两个term在各个documents出现的情况来得到相应文本的向量:
根据这个我们就可以得到对应的向量图如下所示:
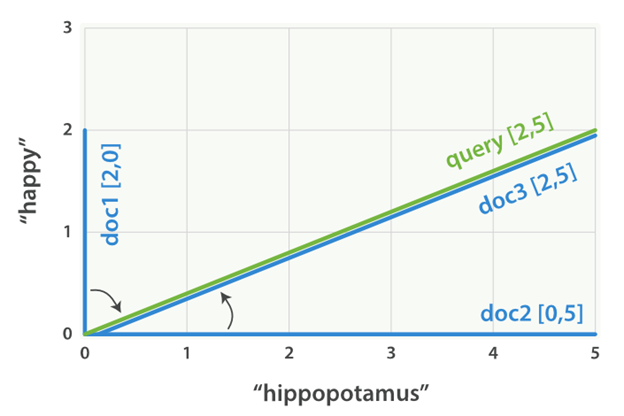
这样一来,我们就可以根据它和查询的那个向量之间的夹角来计算相关性,这个夹角越大,那么相关性就越小。
从人的观察来看,二维和三维的图是比较容易直观理解的,但是对计算机来说,其实不管几维(搜索几个term)都是可以用同样的方法来计算最终结果的。
总结
本文重点介绍了ElasticSearch中的score的计算方法,希望能够给大家在平时的实践中提供理论的支撑。

赞和在看就是最大的支持
