





目录
1 概述
2 配置环境
3 规则定义
4 数据生成
5 分发性能测试
6 总结
概述
Pgpool-II是一个位于PostgreSQL服务器和PostgreSQL数据库客户端之间的中间件。它可以提供并行查询的功能。在并行查询中,数据可以被分割到两个或两个以上的数据库节点中,也就是分区存储。一个查询就可以在多个节点上同时执行,以减少总体执行时间。这在进行大规模数据查询的时候非常有效。
那么当我们需要执行大规模数据写入的时候,是否可以使用pgool的并行模式来完成分区存储?它的性能如何?本文接下来的内容将通过pgpool-II中parallel mode来实现数据分区存储,并通过修改分区规则函数分别测试sql语句和C语言下分区写入的性能。
配置环境
本文中将pgpool和主备pg数据库分别安装在三个不同的server上。
Pgpool server IP:192.168.199.99
Primary Server IP:192.168.100.122
Standby Server IP:192.168.100.124
PostgreSQL版本:11.5(7.4以上即可)
Pgpool版本:pgpool-II-3.3.6
(配置参考:https://www.pgpool.net/docs/pgpool-II-3.2.1/tutorial-zh_cn.html#dist-def)
规则定义
本文测试中,将pgbench中pgbench_branches和pgbench_accounts分区存储到两个节点上,规则中定义:
对pgbench_branches表中bid为偶数的数据分发到节点0上,为奇数的数据分发至节点1。
对pgbench_accounts表中aid为偶数的数据分发到节点0上,为奇数的数据分发至节点1。
详细代码如下(dist_def_pgbench.sql):
$Header$INSERT INTO pgpool_catalog.dist_def VALUES ('bench_parallel','public','pgbench_branches','bid',ARRAY['bid', 'bbalance', 'filler'],ARRAY['integer', 'integer', 'character(88)'],'pgpool_catalog.dist_def_tbls');INSERT INTO pgpool_catalog.dist_def VALUES ('bench_parallel','public','pgbench_accounts','aid',ARRAY['aid', 'bid', 'abalance', 'filler'],ARRAY['integer', 'integer', 'integer', 'character(84)'],'pgpool_catalog.dist_def_tbls');CREATE OR REPLACE FUNCTION pgpool_catalog.dist_def_tbls(anyelement)RETURNS integer AS $$SELECT CASE WHEN MOD($1,2) = 0 THEN 0ELSE 1END;$$ LANGUAGE sql;复制
另外两张表pgbench_tellers和pgbench_history作为复制表,复制规则(replicate_def_pgbench.sql)定义如下:
-- $Header$INSERT INTO pgpool_catalog.replicate_def VALUES ('bench_parallel','public','pgbench_tellers',ARRAY['tid', 'bid', 'tbalance', 'filler'],ARRAY['integer', 'integer', 'integer', 'character(84)']);INSERT INTO pgpool_catalog.replicate_def VALUES ('bench_parallel','public','pgbench_history',ARRAY['tid', 'bid', 'aid', 'delta', 'mtime', 'filler'],ARRAY['integer', 'integer', 'integer', 'integer', 'timestamp without time zone', 'character(22)']复制
数据生成
定义好了分发和复制规则,我们先用pgbench生成200000条数据测试一下分区存储是否生效。
数据生成过程如下:
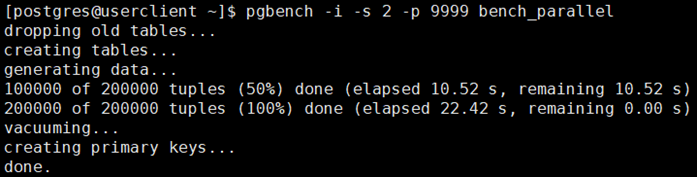
测试结果:
分别执行select查询数据的不同节点上的分布情况:
psql -c "SELECT min(aid), max(aid)FROM pgbench_accounts" -h 192.168.100.122 -p 5432 bench_parallelpsql -c "SELECT min(aid), max(aid)FROM pgbench_accounts" -h 192.168.100.124 -p 5432 bench_parallel复制
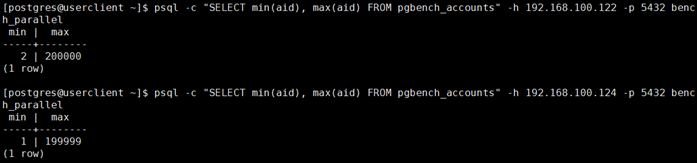
结果显示符合我们最初定义的分发规则。
分发性能测试
sql语句与C语言分发性能对比:
前面我们用sql语句实现了分发规则。每次写入数据的时候,pgpool都需要到系统数据库(运行在pgpool server上的数据库)中读取分发函数,并且执行一条SELECT查询,写入效率不高。于是我们考虑是否可以通过C语言函数来实现同样功能的分发规则,在一定程度上提高写入速度。
首先我们新建一个dist_fun.c的文件,以C的形式实现奇偶数据分发的规则:
#include "postgres.h"#include <string.h>#include "fmgr.h"#ifdef PG_MODULE_MAGICPG_MODULE_MAGIC;#endifPG_FUNCTION_INFO_V1(dist_def_tlbs);Datumdist_def_tlbs(PG_FUNCTION_ARGS){int32 arg = PG_GETARG_INT32(0);if (arg%2 == 0){PG_RETURN_INT32(0);}PG_RETURN_INT32(1);}复制
然后编译生成dist_fun文件,存放于路径/root/dist_func/下。最后按下面的格式修改dist_def_pgbench.sql文件中的函数定义部分,并重新写入到系统数据库中:
CREATE OR REPLACE FUNCTION pgpool_catalog.dist_def_tbls(anyelement)RETURNS integer AS '/root/dist_func/dist_fun', 'dist_def_tbls'LANGUAGE C STRICT;复制
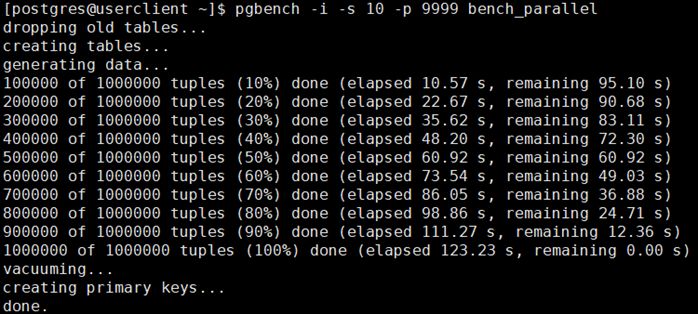
分别在两种规则下通过pgbench生成一百万条数据进行对比:
(1) SELECT定义规则:
(2) C函数实现规则:
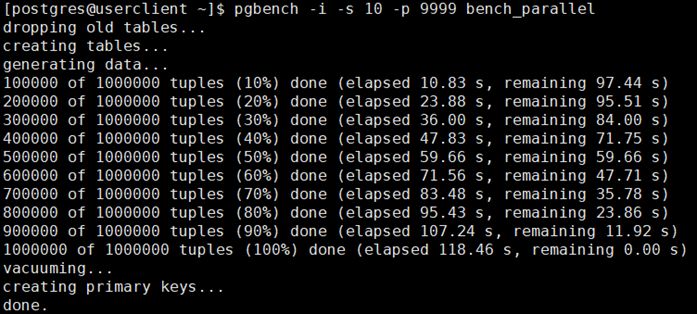
对比发现即使用C语言来定义分区规则,写入速度提升仍并不显著。
如果我们关闭parallel mode,在数据写入的过程中就会跳过分发部分,直接写入到主节点中。我们再用pgbench写入一百万条数据时,仅需要不4秒钟。
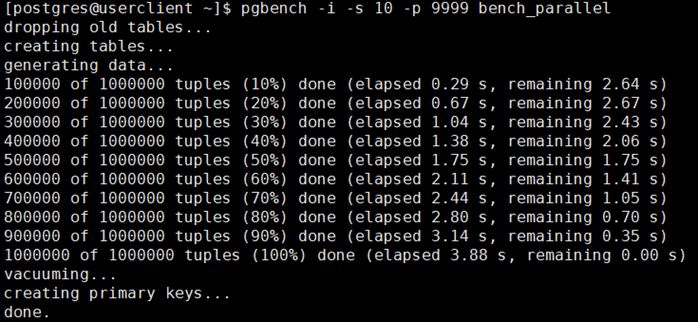
可见在一次性写入大量数据时,pgpool的分区存储会大大降低写入速度,性能远不及单节点存储的效率。
总结
Pgpool-II的并行模式可以实现将数据分区存储的功能,用户可以自定义分区规则,充分利用每个节点的存储空间。但由于每条数据写入都要通过系统数据库中的dist_def表查询分区规则,在一次性写入大量数据的情况下会非常耗时。因此,在对写入速度要求不高,或者很少一次性大量写入的场景下,可以采用pgpool自带的并行模式来完成数据分区存储的方案。
此外,parallel mode在pgpool-II 3.4.0版本上已经被弃用,相关代码在3.5.0的版本上被完全移除。官方文档中没有提及移除的原因。可能后续会有更好的解决方案。

