





前言
在数据库系统中,复制( Replication)主要作用在于提供高可用性(HA)和有效灾难恢复(DR)。此博客旨在确定复制在数据库系统中的作用,概要描述复制及其类型,以及PostgreSQL中复制选项。
基于硬件的复制
实时 - 所有更改立即应用于后续系统。
更容易安装 - 无需脚本或软件配置。
独立于应用程序 - 复制发生在存储层,独立于OS 软件应用程序。
数据完整性和一致性 - 由于镜像发生在存储层,可以有效地生成存储磁盘的精确副本,因此可以自动确保数据的完整性和一致性。
尽管硬件复制具有一些非常吸引人的优点,但它还有其自身的局限性。它通常依赖于供应商,即必须使用相同类型的硬件,并且通常不是非常经济有效的。
基于软件的复制
此复制可以从通用解决方案到特定产品的解决方案进行描述。通用解决方案倾向于通过在软件级别实现不同系统间的数据复制来模拟硬件复制。负责执行复制的软件会复制写入源存储的每个bit位数据并将其传播到目标系统。特定产品的解决方案,更考虑产品要求,通常用于特定产品。基于软件的复制有其优点和缺点。一方面,它提供了灵活性和对复制方式的控制,非常具有成本效益,同时也提供了更好的功能集。但另一方面,它需要大量配置,需要持续监控和维护。
数据库复制
现在让我们将注意力转向数据库复制主题。
在进入更多细节之前,我们首先讨论用于描述数据库复制系统中的不同组件的不同术语。Primary-Standby,Master-Slave,Publisher-Subscriber,Master-Master Multimaster是最常用的术语,用于描述参与复制设置的数据库服务器。术语Primary,Master和Publisher用于描述努力将其接收的更改传播到其它活动节点。而Standby,Slave和Subscriber术语用于描述将从活动节点接收传播更改的从节点。在本博客中,我们将使用Primary来描述从节点的活动节点。可以在Primary-Standby和Multi-master配置中配置数据库复制。
在主 - 备配置中,只有一个实例接收数据更改,然后将它们分配给备用数据库。
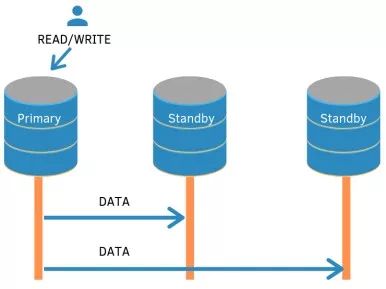
主备模式

多主模式
同步/异步复制
复制过程的核心是主节点将数据传输到备节点的能力。与其他数据库传输策略非常相似,这可以以同步方式处理,其要点是等待所有备用数据库确认它们已经在磁盘上接收和写入数据,收到这些确认后,客户才会收到确认。或者,主节点可以在本地提交数据,并在可能的情况下将事务数据传输到备用数据库,期望备用数据库将在磁盘上接收和写入数据。在这种情况下,备用服务器不会向主服务器发送确认。前一种策略称为同步复制,这称为异步复制。
基于硬件和软件的解决方案都支持同步和异步复制。
两种类型的复制策略如下图所示:
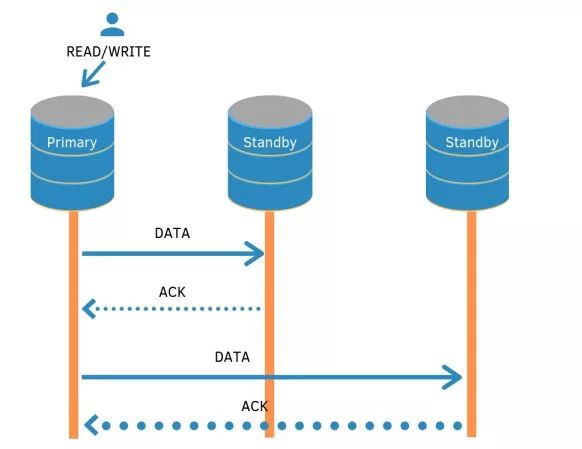
同步复制
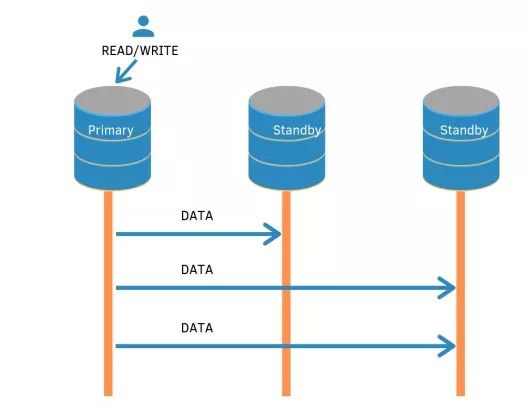
异步复制
由于两种策略的主要区别在于确认备节点上写入的数据;使用这两种技术都有优点和缺点。配置同步复制,使得所有系统都是最新的并且复制是实时完成的。但与此同时,由于主节点等待备节点确认,它会对系统性能产生不利影响。异步复制往往提供更好的性能,因为没有等待来自备节点确认消息的时间。
级联复制
本文描述至此,我们已经看到只有主节点将事务数据传输到备节点。这可以在多节点间分配负载;即已接收数据并写入磁盘的备节点可将其传输到配置为从的其它备用节点,这称为级联复制。其中在主从节点间以及备节点之间配置复制。以下是级联复制的图示。
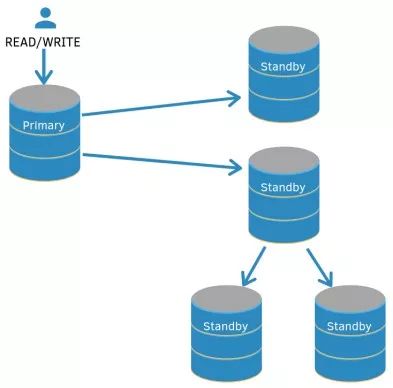
级联复制
备机模式
温备(Warm standby)是一个术语,用于描述备用服务器,该备用服务器允许备用数据库从主服务器接收更改,但不允许任何客户端直接连接到它。热备用是用于描述备用服务器的术语,备用服务器还允许接受客户端连接。
PostgreSQL复制
最后,我想分享PostgreSQL可用的复制选项。
PostgreSQL提供内置的日志流和逻辑复制选项。内置复制仅在主 - 备用配置中可用。
流复制(SR)
在Postgres中也称为物理和二进制复制。二进制数据流式传输到备用数据库。流复制使用WAL(预写日志)传输此类数据。在主服务器上进行的任何更改首先写入WAL文件,然后再写入磁盘,数据库服务器可以将这些记录流式传输到任意数量的备用数据库。由于它是数据的二进制副本,因此也存在某些限制。只有在备用数据库上必须复制所有更改时,才能使用此类复制。如果只需要一部分更改,则无法使用此功能。备用服务器要么不接受连接,要么接受连接,但只提供只读查询。另一个限制是它不能与不同版本的数据库服务器一起使用。
整个设置,默认情况下,流复制是异步的,但是,打开同步复制并不困难。这种设置非常适合实现高可用性(HA)。如果主服务器出现故障,其中一个备用数据库就可以取代它,因为它们几乎就是它的精确副本。
基本配置如下:
# First create a user with replication role in the primary database, this user will be used by standbys to establish a connection with the primary:CREATE USER foouser REPLICATION;# Add it to the pg_hba.conf to allow authentication for this user:# TYPE DATABASE USER ADDRESS METHODhost replication foouser <ip address range> trust# Take a base backup on the stanby:pg_basebackup -h <primary-ip> -U foouser -D ~/standby# In postgresql.conf following entries are neededwal_level=replica # should be set to replica for streaming replicationmax_wal_senders = 8 # number of standbys to allow connection at a time# On the stanby, create a recovery.conf file in its data direcrtory with following contents:standby_mode=onprimary_conninfo='user=foouser host=<primary-ip> port=<primary-port>'Now start the servers and a basic streaming replication should work.
逻辑复制
与流复制相比,PostgreSQL中的逻辑复制是比较新的功能。流复制是整个数据的逐字节副本。但是,它不允许将单个表或数据子集从主服务器复制到备用数据库。逻辑复制可以将数据库中的特定对象复制到备用数据库,而不是复制整个数据库。它还允许在不同版本的数据库服务器之间复制数据,同时允许备用数据库接受读写查询。但要注意避免数据冲突的问题,因为如果允许主数据库和备用数据库在同一个表上写入,则可能会发生数据冲突,从而停止复制过程。在这种情况下,用户必须手动解决这些冲突。但是,备用数据库和主数据库都可以允许写入完全脱节的数据集,这将避免任何冲突解决需求。
基本配置如下:
# First create a user with replication role in the primary database, this user will be used by standbys to establish a connection with the primary:CREATE USER foouser REPLICATION;# Add it to the pg_hba.conf to allow authentication for this user:# TYPE DATABASE USER ADDRESS METHODhost replication foouser <ip address range> trust# For logical replication, base backup is not required, any of the two database instances can be used to create this setup.wal_level=logical # for logical replication, wal_level needs to be set to logical in postgresql.conf file.# on primary server, create a some tables to replicate and a publication that will list down these tables.CREATE TABLE t1 (col1 int, col2 varchar);CREATE TABLE t2 (col1 int, col2 varchar);INSERT INTO t1 ....;INSERT INTO t2 ....;CREATE PUBLICATION foopub FOR TABLE t1, t2;# on the standby, the structure of above mentioned tables needs to be created as DDL is not replicated.CREATE TABLE t1 (col1 int, col2 varchar);CREATE TABLE t2 (col1 int, col2 varchar);# on standby, create a subscription for the above publication.CREATE SUBSCRIPTION foosub CONNECTION 'host=<primary-ip> port=<primary-port> user=foouser' PUBLICATION foopub;With this a basic logical replication is achieved.
我希望这个博客能帮助您理解复制,区别PostgreSQL流复制和逻辑复制。此外,希望这可以帮助您更好地设计满足您需求的复制环境。
作者简介
Asif Rehman
高级软件工程师。
他于2005年加入EnterpriseDB,这是一家企业PostgreSQL的公司,并开始他的职业生涯,专注在PostgreSQL的开源开发方面。Asif的贡献包括开发与oracle兼容性相关的内部功能,以及围绕PostgreSQL开发工具。他于2018年9月加入HighGo Software。

