




本文主要介绍关于达梦中存储的表,堆表,及索引对象及空间回收和大小查看内容。
1 存储对象
1.1 对于普通表和索引
1)初始簇数目 INITIAL:指建立表时分配的簇个数,必须为整数,最小值为 1,最大值为 256,缺省为 1;
2) 下次分配簇数目 NEXT:指当表空间不够时,从数据文件中分配的簇个数,必须为
整数,最小值为 1,最大值为 256,缺省为 1;
3)最小保留簇数目 MINEXTENTS:当删除表中的记录后,如果表使用的簇数目小于这
个值,就不再释放表空间,必须为整数,最小值为 1,最大值为 256,缺省为 1;
4) 填充比例 FILLFACTOR:指定插入数据时数据页的充满程度,取值范围从 0 到
100。默认值为 0,等价于 100,表示全满填充,未充满的空间可供页内的数据更
新时使用。插入数据时填充比例的值越低,可由新数据使用的空间就越多;更新数
据时填充比例的值越大,更新导致出现的页分裂的几率越大;
5 )表空间名:在指定的表空间上建表或索引,表空间必须已存在,默认为用户缺省的
表空间。
操作示例:
如表 PERSON 建立在表空间 TS_PERSON 中,初始簇大小为 5,最小保留簇数目为 5,下次分配簇数目为 2,填充比例为 85。
create table person
(personid int identity(1,1) cluster primary key,
sex char(1) not null,
name varchar(50) not null,
email varchar(50))
storage
(initial 5,minextents 5,next 2,on ts_person,fillfactor 85);
分区表上指定分区的存储参数:
create table partition_table
(c1 int,c2 int)
partition by range(c1)
(partition par1 values less than(5),
partition par2 values less than(100) storage(on ts_person));
警告: 范围分区未包含MAXVALUE,可能无法定位到分区
1.2 堆表
普通表都是以 B 树形式存放的,ROWID 都是逻辑的 ROWID,即从 1 一直增长下去。在并发情况下,每次插入过程中都需要逻辑生成 ROWID,这样影响了插入数据的效率;对于每一条数据都需要存储 ROWID 值,也会花费较大的存储空间。简单地说,堆表是指采用了物理 ROWID 形式的表,即使用文件号、页号和页内偏移而
得到 ROWID 值,这样就不需要存储 ROWID 值,可以节省空间。逻辑 ROWID 在插入或修改过程中,为了确保 ROWID 的唯一性,需要依次累加而得到值,这样就影响了效率,而堆表只需根据自己的文件号、页号和页内偏移就可以得到 ROWID,提高了效率。
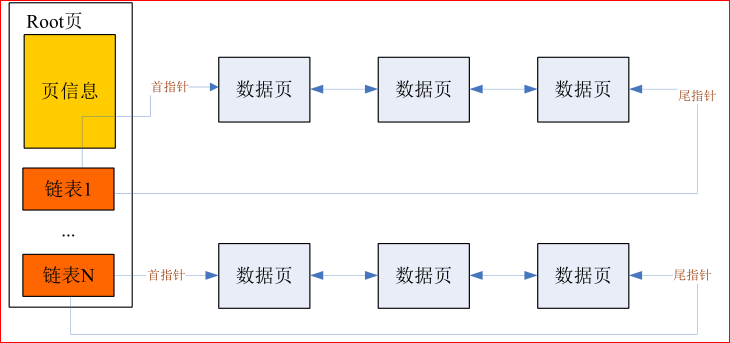
普通表都是以 B 树形式而存储在物理磁盘上, 而堆表则采用一种“扁平 B 树”方式存储,为支持并发插入,扁平 B 树可以支持最多 128 个数据页链表 (最多 64 个并发分支和最多 64 个非并发分支) ,在 B 树的控制页中记录了所有链表的首、尾页地址。对于非并发分支,如果分支数有多个,即存在多个链表,则不同的用户登录系统之后,会依据其事务 ID 号,随机选择一条链表来对堆表进行插入操作。对于并发分支,则不同用户会选择不同的分支来进行插入,如果存在多个用户选择了同一条分支的情况, 才需要等待其他用户插入结束并释放锁之后才能进行插入。在并发情况下,不同用户可以在不同的链表上进行插入,效率得到较大提升。
1.2.1 创建堆表:
两种方式:一是采用在配置文 件Dm.ini中设置参数,一种是在建表语句中显示指定
用户可以在配置文件中,添加 LIST_TABLE 参数:
- 如果 LIST_TABLE = 1,则在未显式指定表是否为堆表或非堆表时,默认情况下
创建的表为堆表; - 如果 LIST_TABLE = 0,则在未显式指定表是否为堆表或非堆表时,默认情况下
创建的表为普通表形式。
不管参数 LIST_TABLE 设置为何值,创建表时可以在 STORAGE 选项中指定需要创建
的表形式, 与堆表创建形式相关的关键字有三个,分别是 NOBRANCH、BRANCH、
CLUSTERBTR。详细语法形式参见《DM7_SQL 语言使用手册》 。 - NOBRANCH:如果指定为 NOBRANCH,则创建的表为堆表,并发分支个数为 0,非
并发分支个数为 1; - BRANCH(n,m):如果为该形式,则创建的表为堆表,并发分支个数为 n,非并发
个数为 m; - BRANCH n:指定创建的表为堆表,并发分支个数为 n,非并发分支个数为 0;
- CLUSTERBTR:创建的表为非堆表,即普通 B 树表。
如下例创建的 LIST_TABLE 表有并发分支 2 个,非并发分支 4 个。
CREATE TABLE LIST_TABLE(C1 INT) STORAGE(BRANCH (2,4));
1.2.2 堆表的限制
聚集索引
堆表采用了物理 ROWID,即通过文件号、页号和页内偏移直接生成该值。这样如果我
们知道了 ROWID 值,也就知道文件号、页号和页内偏移这些变量,就可以直接定位到某条记录,所以没有必要再为堆表创建聚集索引了。在创建堆表时,系统会默认创建聚集索引,该索引只是一个根页信息。 显式建立聚集索引是不允许的, 如果用户需要借助聚集索引主键对数据进行排序则不推荐使用堆表列存储。
由于列存储采用了不同方式对表进行物理存储, DM 服务器暂时不支持堆表的列存储。
1.2.3 维护堆表
建议在经常查询的列上建立二级索引,这样在进行操作中,先通过二级索引找到记录
ROWID,就可以直接找到数据,效率有较大提高。
堆表虽然支持表的 ALTER 操作,但是建议轻易不要进行此类操作。对表进行 ALTER
操作,数据记录的 ROWID 有可能发生改变,这样每次进行 ALTER 操作,都可能进行索引的重建,需要花费较多的时间。
达梦服务器支持对堆表的备份与还原操作。 还原数据时, B树数据和二级索引可以同时被还原。
可以通过系统过程SP_TABLEDEF(‘SCHEMA_NAME’,’TABLE_NAME’)查看堆表的定
义信息,该函数的详细信息可参考 《DM8_SQL 语言使用手册》 。
SQL> desc sp_tabledef
行号 NAME TYPE$ IO DEF RT_TYPE
---------- --------------- -------------- -- --- -------
1 SP_TABLEDEF PROC
2 SYS.SCHMNAME VARCHAR(32767) IN
3 SYS.TABLENAME VARCHAR(32767) IN
SQL> create table list_table(id number) storage (branch 2);
操作已执行
SQL> call sp_tabledef('SYSDBA','LIST_TABLE');
行号 COLUMN_VALUE
---------- ---------------------------------------------------------
1 CREATE TABLE "SYSDBA"."LIST_TABLE" ( "ID" NUMBER) STORAGE(ON "MAIN", BRANCH 2) ;
1.3 Huge表
HUGE 表是建立在自己特有的 HTS 表空间上的。 建立 HUGE 表如果不使用默认的表空间,
则必须要先创建一个 HUGE TABLESPACE,默认 HTS 表空间为 HMAIN。
如建立一个名称 HTS_NAME 的 HTS 表空间, 表空间路径为为 e:\HTSSPACE。 示例如下:
CREATE HUGE TABLESPACE HTS_NAME PATH 'e:\HTSSPACE';
- 区大小(一个区的数据行数) 。 区大小可以通过设置表的存储属性来指定, 区的大
小必须是 2 的多少次方,如果不是则向上对齐。取值范围:1024 行~1024*1024
行。默认值为 65536 行。 - 是否记录区统计信息,即在修改时是否做数据的统计。
- 所属的表空间。创建 HUGE 表,需要通过存储属性指定其所在的表空间,不指定则
存储于默认表空间 HMAIN 中。HUGE 表指定的表空间只能是 HTS 表空间。 - 文件大小。 创建 HUGE 表时还可以指定单个文件的大小, 通过表的存储属性来指定,
取值范围为 16M~1024*1024M。不指定则默认为 64M。文件大小必须是 2 的多少
次方,如果不是则向上对齐。 - 日志属性。1)LOG NONE:不做镜像;2)LOG LAST:做部分镜像;3)LOG ALL:
全部做镜像。
示例:
STUDENT 表的区大小为 65536 行,文件大小为 64M,指定所在的
表空间为 HTS_NAME , 做完整镜像, S_COMMENT 列指定的区大小为不做统计信息, 其它列 (默认)都做统计信息。
CREATE HUGE TABLE STUDENT
(S_NO INT,
S_CLASS VARCHAR,
S_COMMENT VARCHAR(79) STORAGE(STAT NONE))STORAGE(SECTION(65536) , FILESIZE(64), ON HTS_NAME) LOG ALL;
操作过程:
创建表空间:
SQL> create huge tablespace htbs path '/home/dmdba/dmdbms/data/huge';
操作已执行
此时在操作系统中可以查到/home/dmdba/dmdbms/data/huge:
[dmdba@enmoedu huge]$ pwd
/home/dmdba/dmdbms/data/huge
创建表:
SQL> create huge table student
(s_no int,
s_class varchar,
s_comment varchar(79) storage (stat none))
storage(section(65536),filesize(64),on htbs) log all;
操作已执行
查看操作系统目录 :
[dmdba@enmoedu huge]$ pwd
/home/dmdba/dmdbms/data/huge
[dmdba@enmoedu huge]$ ls
SCH150994945
随着数据的插入,此目录下文 越来越多,以如下结构存储
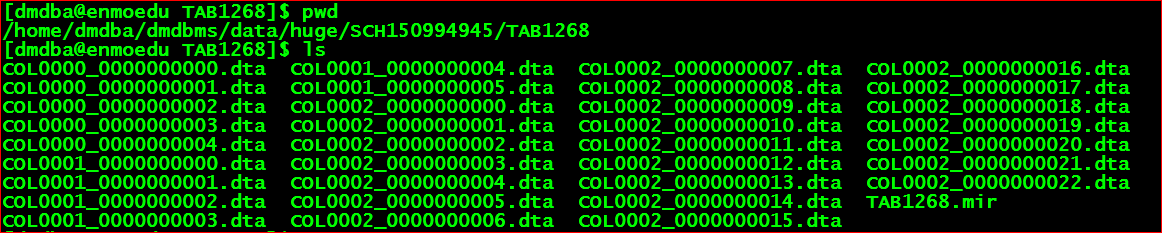
其中每个文 件的大小是64M.
[dmdba@enmoedu TAB1268]$ du -sh COL0000_0000000000.dta
65M COL0000_0000000000.dta
2 空间回收
表和索引对象的所占用的簇要么是全满的状态要么是半满的状态,空闲的簇会被
系统自动回收
3 空间限制
3.1 用户的空间限制
用户占用的空间是其下所有用户表对象占用空间的总和。可以限制用户使用空间的大
小,当用户创建表,创建索引,或者插入更新数据超过了指定的空间限制时,会报空间不足
的错误。如创建用户 TEST_USER 时可指定该用户使用的最大磁盘空间为 50M。
CREATE USER TEST_USER IDENTIFIED BY TEST_PASSWORD DISKSPACE LIMIT 50;
对用户的空间限制也可进行更改,如修改用户 TEST_USER 的磁盘空间限制为无限制。
ALTER USER TEST_USER DISKSPACE UNLIMITED;
3.2 表对象空间限制
表对象占用的空间是其上所有索引占用空间的总和。可以限制表对象使用空间的大小,
当在表对象上创建索引或者插入更新数据超过了指定的空间限制时,会报空间不足的错误。
如创建表 TEST 时可指定该表对象可使用的最大磁盘空间为 500M。
CREATE TABLE TEST (SNO INT, MYINFO VARCHAR) DISKSPACE LIMIT 500;
对表对象空间的限制也可进行更改,如修改表 TEST 的磁盘空间限制为 50M。
ALTER TABLE TEST MODIFY DISKSPACE LIMIT 50;
4 查看空间
4.1 查看用户占用的空间
可以使用系统函数 USER_USED_SPACE 得到用户占用空间的大小,函数参数为用户名,返回值为占用的页的数目。
SELECT USER_USED_SPACE('TEST_USER');
4.2 查看表占用的空间
可以使用系统函数 TABLE_USED_SPACE 得到表对象占用空间的大小,函数参数为模式名和表名,返回值为占用的页的数目。
SELECT TABLE_USED_SPACE('SYSDBA', 'TEST');
4.3 查看表使用的页数
可以使用系统函数 TABLE_USED_PAGES 得到表对象实际使用页的数目,函数参数为模式名和表名,返回值为实际使用页的数目。
SELECT TABLE_USED_PAGES('SYSDBA', 'TEST');
4.4 查看索引占用的空间
可以使用系统函数 INDEX_USED_SPACE 得到索引占用空间的大小,函数参数为索引
ID,返回值为占用的页的数目。
SELECT INDEX_USED_SPACE(33555463);
4.5 查看索引使用的页数
可以使用系统函数 INDEX_USED_PAGES 得到索引实际使用页的数目,函数参数为索引ID,返回值为实际使用页的数目。
SELECT INDEX_USED_PAGES(33555463);
