




继续更新ElasticSearch学习记录:Query和Filter区别
两者的区别我们先来看EleasticSearch官方的解释:


主要区别:
Query在执行时既要计算文档是否匹配,还要计算文档相对于其他文档的匹配度有多高,匹配度越高,_score 分数就越高
Filter在执行时只关心文档是否和查询匹配,不会计算匹配度,也就是得分;Filter为什么会更快?经常使用的过滤器将被Elasticsearch自动缓存,以提高性能。
性能对比:
Fileter过滤查询是对集合包含/排除的简单检查,快速返回结果,如果存在多个Filter过滤条件,当至少有一个过滤查询是“稀疏”(仅有少量匹配的文档)时,可以利用各种优化,并且可以将缓存经常使用的filter过滤查询缓存在内存中以加快访问速度。
Query检索(评分查询)不仅要查找匹配的文档,还要计算每个文档的相关程度,这通常会使其比非评分文档更复杂。另外,查询结果不可缓存。所以效率相对于Filter要差很多。
查询示例
1、filter与query示例
PUT filter_query/_doc/1{“address”: {“country”: “china”,“province”: “shandong”,“city”: “jinan”},“name”: “ljs1”,“age”: 32,“join_date”: “2021-08-01”}PUT filter_query/_doc/2{“address”: {“country”: “china”,“province”: “shandong”,“city”: “qingdao”},“name”: “ljs2”,“age”: 35,“join_date”: “2015-07-05”}PUT filter_query/_doc/3{“address”: {“country”: “china”,“province”: “shandong”,“city”: “yantai”},“name”: “ljs3”,“age”: 25,“join_date”: “2015-06-05”}PUT filter_query/_doc/4{“address”: {“country”: “china”,“province”: “shandong”,“city”: “weifang”},“name”: “ljs4”,“age”: 28,“join_date”: “2015-05-05”}
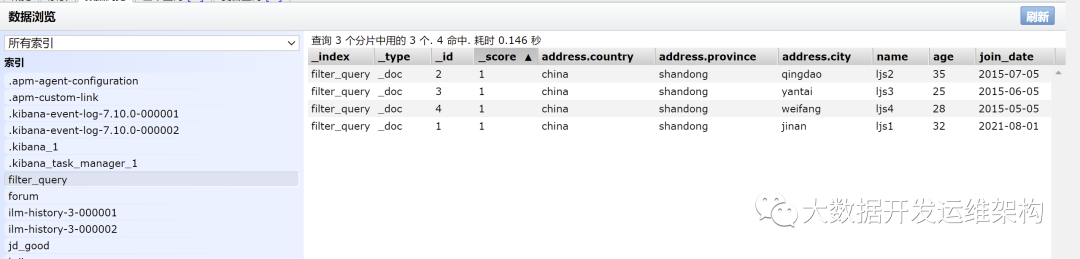
这个做下查询测试:
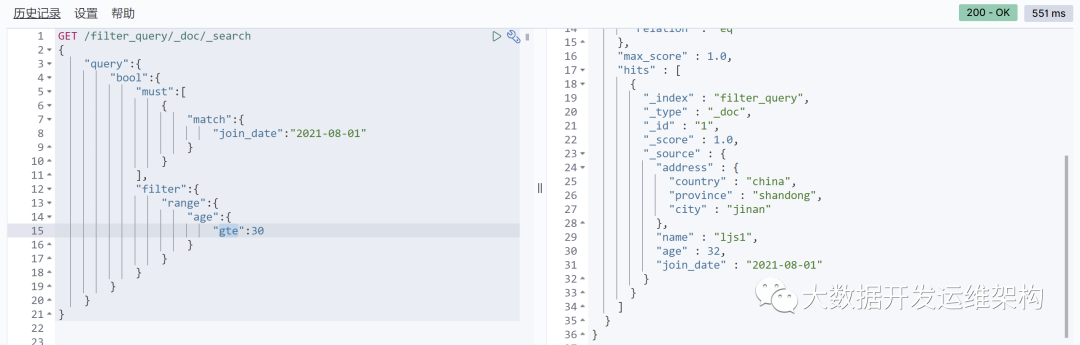
年龄必须大于等于32,同时join_date必须是2021-08-01
2.查询语句json:
GET /filter_query/_doc/_search{"query":{"bool":{"must":[{"match":{"join_date":"2021-08-01"}}],"filter":{"range":{"age":{"gte":30}}}}}}
3.kibana发送请求,查询结果如下:
文章转载自大数据开发运维架构,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
