





如今,用户对他们的数据仓库的要求越来越高。这导致了数仓技术所提供的技术的进步,并导致一些可能的技术变化。例如,在这篇文章中,我们看实时数据仓库(RTDW),这是客户在Cloudera上构建的一类用例,并且这类用例在我们的客户中变得越来越普遍。
让我们看看一个正在推出5G的大型亚洲电信提供商。他们使用Cloudera构建了实时数仓,以确保良好的客户体验并控制维护成本。通过实时查看其网络的各个方面,可以实时识别潜在的故障硬件,从而避免对客户呼叫/数据服务造成影响。当解决方案更便宜时,这也使得他们有机会及早修复该问题。
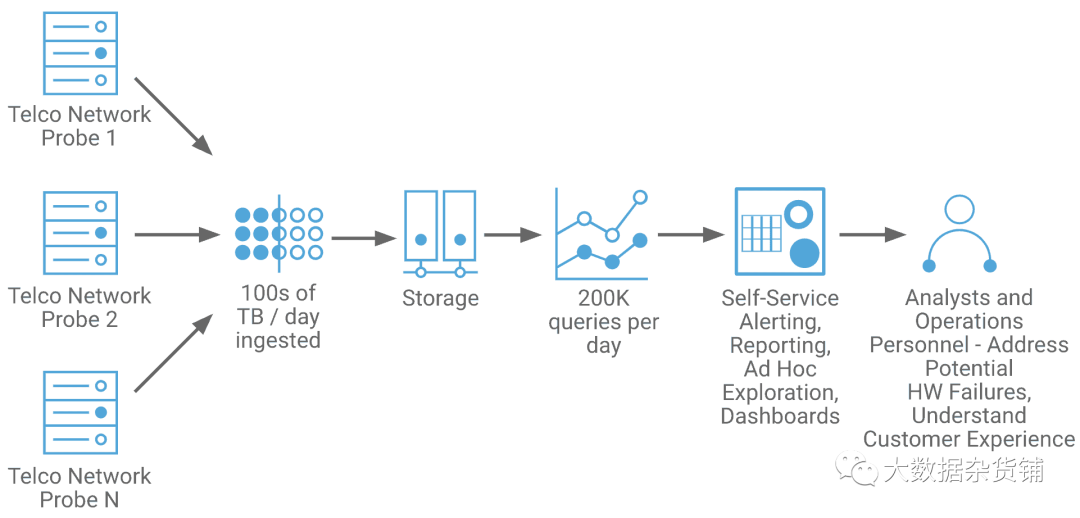
每天摄取100 TB的网络事件数据
数据更新和删除以确保数据正确性
每天200,000个查询
混合的Ad Hoc探索、仪表板、和警报监控
越来越多的客户要求的功能是:
分析实时数据、近实时数据和历史数据
跨数据域的相关性,即使这些数据域不是传统上存储在一起的(例如:实时客户事件数据与CRM数据一起;网络传感器数据与市场营销活动管理数据一起)
“大数据”的极端规模,但具有“小数据”的感觉和语义
将以上所有内容集成到一个安全的集成平台中
推动这一趋势的因素包括技术、业务和文化。
在技术方面,比以往任何时候都更便宜,更轻松地检测所有内容并通过消息传递系统实时发送数据。
在业务方面,公司和政府正在将其尽可能多的业务数字化和自动化,以使决策和资产管理更加有效。
在文化方面,人们希望能够立即获得所需的答案,而不必去问别人(感谢Google和Wikipedia)。
另一个例子更突出了这一趋势。美国的一家公司AdTech为数字广告客户提供处理、付款和分析服务。数据处理和分析推动了他们的整个业务。因此,他们需要一个能够与现代大数据系统的规模保持同步,但提供传统关系数据库的语义和查询性能的数据仓库。他们选择在Cloudera上构建RTDW。
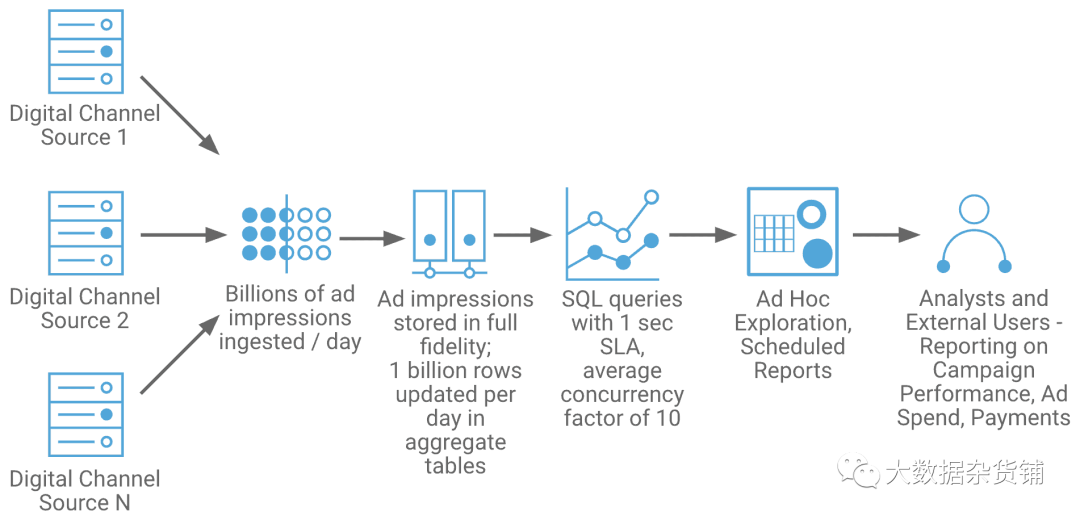
每天流入并存储数十亿次广告展示事件
每天在汇总表中十亿条记录更新
Ad hoc探索和预定报告
每个查询的目标SLA为1秒
平均查询并发系数为10

什么是实时数据仓库?
描述RTDW的最简单方法是,其外观在感觉上就像是普通的数据仓库,但是所有的一切都会变的更快,即使保持更大规模的数据上。这是数据仓库现代化的一种类型,可让您具有“小数据”语义和“大数据”规模的性能。
数据以更快的速度到达仓库–认为每秒数百万个事件的流媒体数据不断到达
数据可最佳查询所需的时间更快-到达后立即进行查询,无需进行处理、聚合或压缩
查询运行的速度更快–小型选择性查询以10或100毫秒为单位进行衡量;大型、扫描或计算繁重的查询以很高的带宽处理
必要时,数据变化的很快-如果由于某种原因需要校正或更新数据,则无需大量重写即可就地完成
尽管这听起来似乎很明显,甚至有些琐碎,但数十年来的数据仓库却显示出了其他情况。对于大量快速到达的数据,要保持交互性能非常困难,其中一些数据可能需要更新,并且需要使用大量不同模式的查询。Cloudera提供了RTDW功能,可以在所有这些框中打勾。因此,许多客户正在构建RTDW应用程序,这是他们使用Cloudera现代化数据仓库实践的总体策略的一部分。
下表提供了组成RTDW的用例特征的更多详细信息。
摄取 | 中等到更高的吞吐量,通常是流式接入 针对仅插入以及插入+更新的模式进行了优化 |
查询 | 针对单点查找、分析、变异等进行了优化,具有低延迟和高并发性 流式传输的数据可以以最佳方式立即查询 可以将流入的数据与历史数据一起进行查询,从而避免了使用Lambda 架构 |
数据模型 | 常规的企业数据类型 小型或者中型的数据模型;主要是维度模型和非范式化模型,偶尔会有范式模型 |
下面的图1显示了实时数据仓库的标准体系结构。它具有快速获取、快速存储和BI即时查询的关键元素。
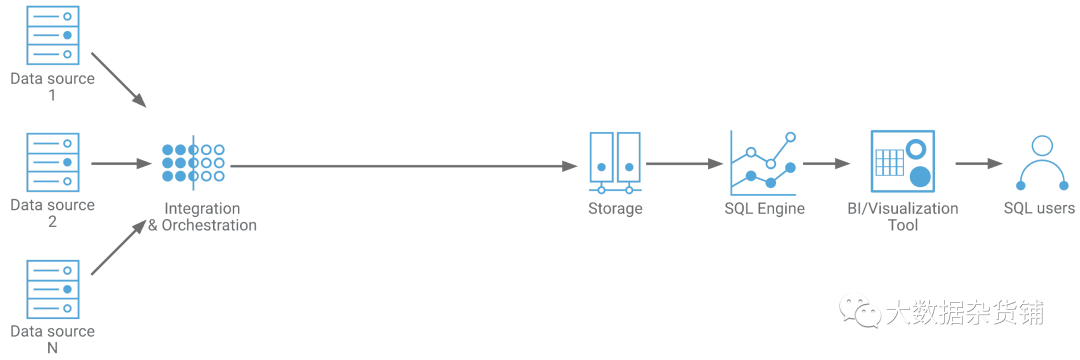
图1.实时数据仓库的基本架构
正如看到的图2中,这是很容易延伸以覆盖可能需要的附加功能。这些包括流处理/分析、批处理、分层存储(即用于主动归档或将实时数据与历史数据结合在一起)或机器学习。
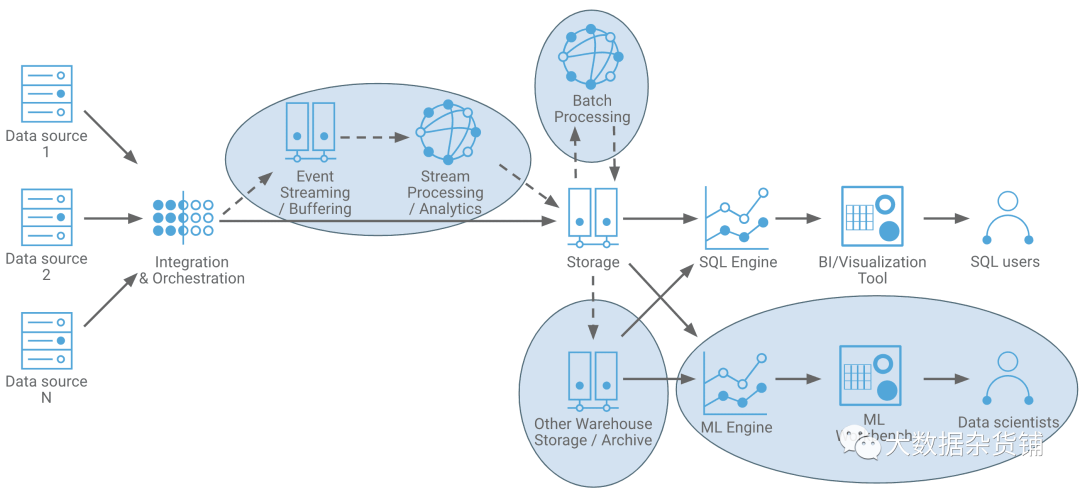
图2.具有扩展功能的实时数据仓库的体系结构
典型的RTDW应用
除了了解RTDW的属性外,查看可在RTDW类别内构建的应用程序类型也很有用。
通用的RTDW
这些是端到端的大量应用程序,用于通用数据处理、商业智能、运营报告、仪表板和Ad hoc探索。但是重要的警告是,摄取速度、开发人员的语义丰富性、数据新鲜度和查询延迟至关重要。可以将它们划分为一个目的(即数据集市),也可以将其作为企业数据仓库进行更全面的划分。
除了上述“实时数据仓库”中描述的特征以外,,通用RTDW具有以下属性:
需要完整的ANSI SQL支持
通常需要进行更新,有时需要较高的工作负载百分比
例如,事务数据的更正,变更检测捕获(CDC),缓慢变化维(SCD)2类逻辑,迟到事件数据的重新排序
在流中完成处理逻辑并随后在数据存储中应用更新的通用
优化访问全保真原始数据和聚合
优化访问当前数据和历史数据
时间序列和事件分析专用RTDW
有时您知道数据事件和分析总是有时间要素,并且事先知道用户将要运行的查询类型。您可以利用这些知识来构建专门用于时间序列和事件分析的RTDW。这样可以极大地提高速度、查询延迟和可伸缩性。折衷是失去了支持的查询模式的通用性,这是可以的,因为首先选择这种专门方法的原因是,它对于您的特定用例是理想的,并且您不需要任何更通用的方法。
除了上述“实时数据仓库”中描述的RTDW特性之外,时间序列和事件分析RTDW具有以下描述:
当数据中始终有时间元素时使用
在预先知道查询模式时,不需要联接,相对静态且不需要临时探索时使用
当出于性能或规模原因而需要数据预聚合时使用
相对简单的数字和文本数据的混合,没有复杂的类型或长字符串
不需要更新数据
添加流分析和流处理
在某些情况下,当数据流流入仓库时,您需要对其进行处理。这可以用于流处理(例如,数据清理,特征工程,CDC协调)或流分析(例如,当阈值超过数据统计滚动窗口时发出警报,根据预测模型对事件数据评分,以决定要采取何种行动接下来。对流中的数据进行操作使您能够在“机器时间”内做出更好的决策,这补充了一旦数据到达仓库后就可以在“人工时”做出更好的决策的能力。
使用Cloudera构建RTDW
Cloudera提供了平台Cloudera数据平台(CDP),用于在公共云和私有云中构建端到端数据应用程序。CDP包含丰富的服务,可用于移动、存储、处理和查询数据。其中一些在Cloudera Data Warehouse(CDW)服务中提供,而其他一些在Cloudera DataHub服务中的不同模板化群集类型中提供。下表总结了用于在CDP中创建RTDW应用程序的构造块。
使用… | 包含... | 用于… |
CDW | Hive | EDW的灵活、可扩展的查询引擎 在单个查询中将Druid数据与其他仓库数据合并 |
Druid | Analytics存储和查询引擎,用于预先聚合的事件数据 快速摄取流数据,交互式查询,超大规模 | |
Hue | 用于运行Hive和Impala查询的SQL编辑器 | |
DataViz (技术预览) | 用于可视化,仪表板和报告构建的工具 连接到Druid、Impala、Hive和其他企业数据源 | |
DataHub– 实时数据集市模板 | Kudu | 分析存储引擎,用于处理大量快速到达的数据 可变性,随机访问,快速扫描,交互式查询 |
Impala | 交互式查询引擎,可对大量数据进行快速BI 在单个查询中将Kudu数据与其他仓库数据合并 | |
Spark Streaming | 微批量流处理引擎 丰富,过滤,转换运动数据 | |
Solr | 用于运行Impala + Kudu查询的SQL编辑器 | |
DataHub– 流消息传递模板 | Kafka | 高吞吐量和大规模分布式事件流 消息的持久性,以确保传递 |
DataHub– 流管理模板 | Nifi | 数据集成,分发和路由引擎 胶水将多个数据引擎组合成端到端流 |
DataHub– 流分析模板 | Flink | 引擎通过数据流提供状态分析计算 对运动中的数据进行警报,评分,决策 |
下面的两个图显示了这些组件如何结合RTDW应用程序的不同口味工作,如上所述。
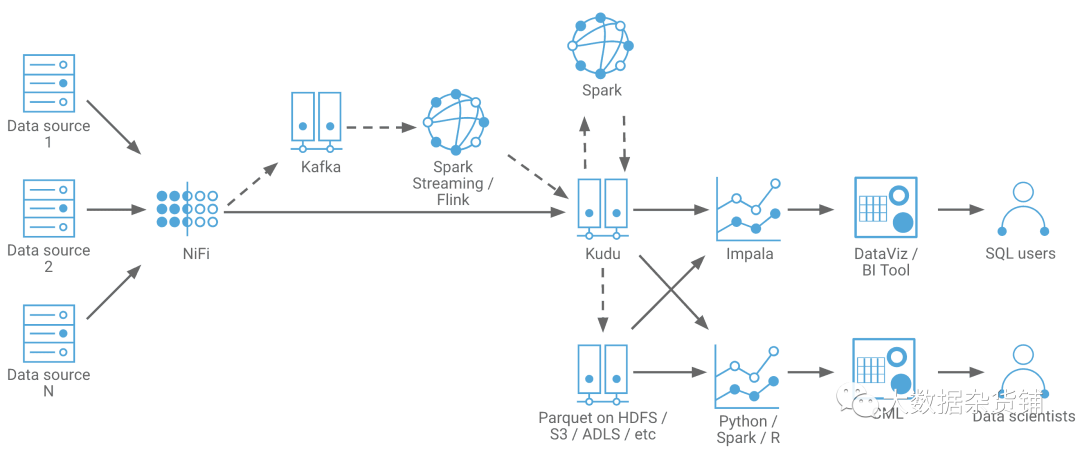
图3. Cloudera CDP中的通用实时数据仓库
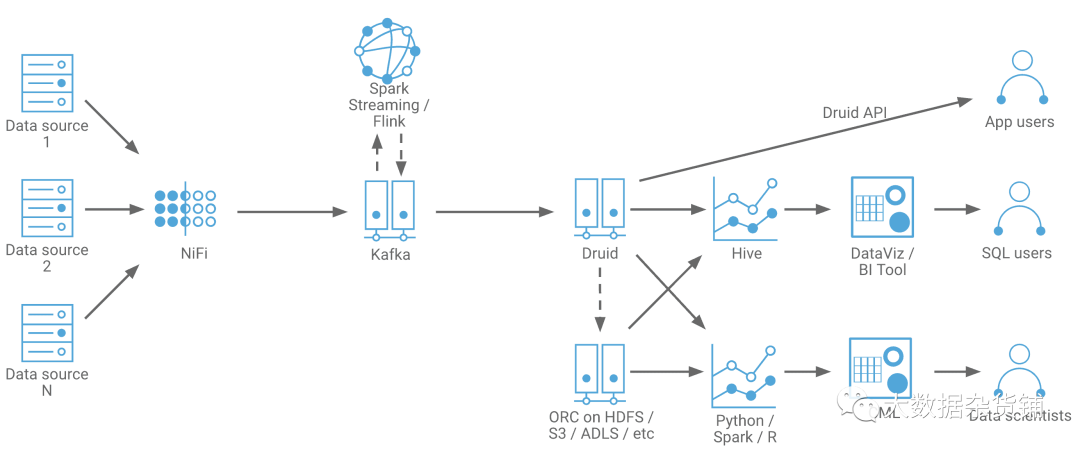
图4. Cloudera CDP中的时间序列和事件分析专用实时数据仓库
下一步是什么?
请关注本系列的下一篇文章,我们将在其中更深入地讨论RTDW的这两种形式。这些将提供有关技术如何协同工作以及如何构建自己的RTDW应用程序的更多详细信息。
深入研究时间序列和事件分析专门的RTDW ,具有Apache Druid、Apache Hive、Apache Kafka和Cloudera DataViz。
深入研究通用RTDW ,其中包括Apache Kudu、Apache Impala和Apache NiFi。
同时,如果您想了解更多信息,请观看此视频,其中显示了如何使用Apache Kafka,Apache Druid,Apache Hive和Cloudera DataViz在CDP中构建端到端事件分析应用程序。此外,我们还有一个网络研讨会和博客,介绍如何使用Apache Kudu和Apache Impala在CDP中创建时间序列应用程序。最后,如果您想了解更多关于使用CDP来做分析,处理和数据的路由内流,请观看这段视频,其中突出显示了Apache NiFi和Apache Kafka。
作者:Justin Hayes
原文链接:https://blog.cloudera.com/an-overview-of-real-time-data-warehousing-on-cloudera/



