




点击关注上方“ 知了小巷 ”,
设为“置顶或星标”,第一时间送达干货。
前文回顾
宏观角度深入了解了:
下面从微观的⻆度出发 ,具体分析数据中台的⽀撑技术 ,以电商场景为例,分别阐释 元数据中⼼ 、指标管理 、模型设计 、数据质量等技术如何在企业落地。
元数据
数据中台的构建,需要确保全局指标的业务⼝径⼀致 ,要把原先⼝径不⼀致的、重复的指标进⾏梳理,整合成⼀个统⼀的指标字典 。⽽这项⼯作的前提,是要搞清楚这些指标的业务⼝径 、数据来源和计算逻辑 。⽽这些数据呢都是元数据。
如果没有这些元数据,就没法去梳理指标,更谈不上构建⼀个统⼀的指标体系 。当我们 看到⼀个数700W,如果我们不知道这个数对应的指标是每⽇⽇活,就没办法理解这个数据的业务含义,也就⽆法去整合这些数据。 所以我们必须要掌握元数据的管理,才能构建⼀个数据中台。
那么问题来了:元数据中⼼应该包括哪些元数据呢?什么样的数据是元数据?
元数据包括哪些?
元数据一般可划为三类:数据字典、数据⾎缘和数据特征。我们还是通过⼀个例⼦来理解这三类元数据。
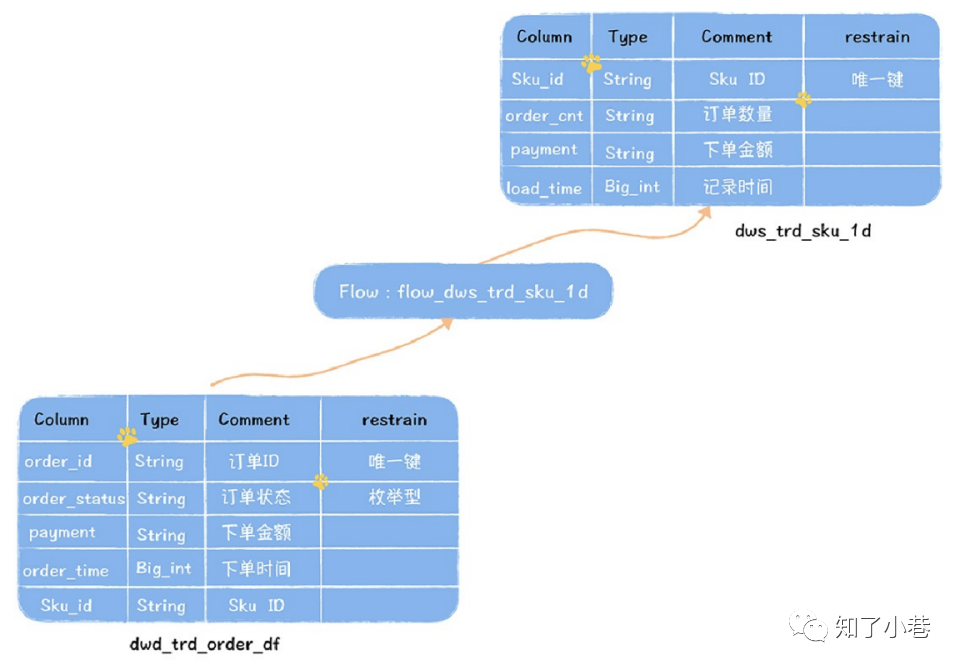
在这个图中,dwd_trd_order_df是⼀张订单交易明细数据,任务flow_dws_trd_sku_1d读取这张表,按照sku粒度,计算每⽇sku的交易⾦额和订单数量,输出轻度汇总表dws_trd_sku_1d。
数据字典描述的是数据的结构信息,我们以dws_trd_sku_1d为例,数据字典包括:

数据⾎缘 是指⼀个表是直接通过哪些表加⼯⽽来,在上⾯的例⼦中,dws_trd_sku_1d是通过dwd_trd_order_df的数据计算⽽来,所以,dwd_trd_order_df是dws_trd_sku_1d的上游表。
数据⾎缘⼀般会帮我们做影响分析和故障溯源 。 ⽐如说有⼀天,⽼板看到某个指标的数据违反常识,需要去排查这个指标计算是否正确, ⾸先需要找到这个指标所在的表,然后顺着这个表的上游表逐个去排查校验数据,才能找到异常数据的根源。
⽽数据特征主要是指数据的属性信息,我们以dws_trd_sku_1d为例:

元数据的种类⾮常多,为了管理这些元数据,必须要构建⼀个元数据中⼼。 接下来看看如何搭建⼀个元数据中⼼,打通企业的元数据。
业界元数据中⼼产品
对于做系统设计有⼀个习惯,就是先看看业界的产品都是怎么设计的,避免闭门造⻋。
业界的⽐较有影响⼒的产品:
1. 开源的有Netflix的Metacate、Apache Atlas;
2. 商业化的产品有Cloudera Navigator。
重点了解Metacate和Atlas这两款产品,⼀个擅⻓于管理数据字典,⼀个擅⻓于管理数据⾎缘,通过了解这两款产品,更能深⼊的理解元数据中⼼应该如何设计。
Metacate多数据源集成型架构设计
https://github.com/Netflix/metacat
关于Metacate ,可以在GitHub上找到相关介绍,关于这个项⽬的背景和功能特性。
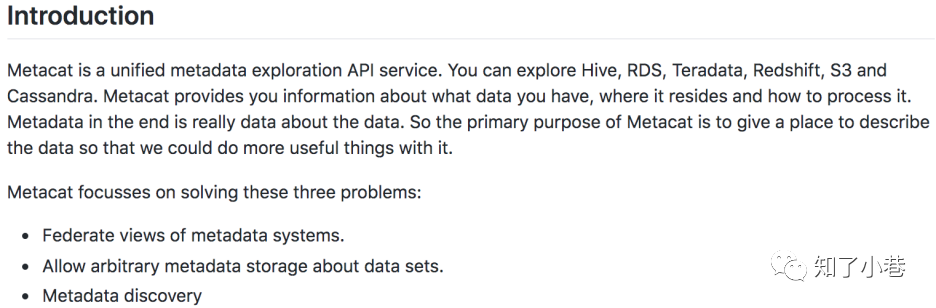
这里强调⼀个点,就是它多数据源的可扩展架构设计 ,因为这个点对于数据字典的管理,真的太重要!
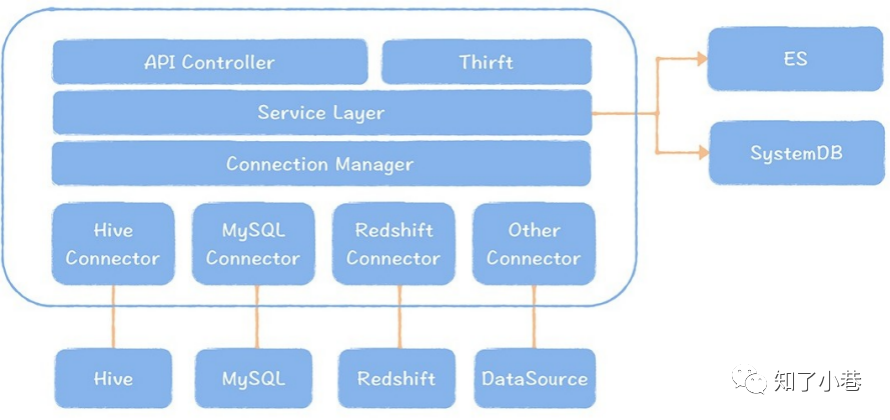
在⼀般的公司中,数据源类型⾮常多是很常⻅的现象,包括Hive、MySQL、Oracle 、 Greenplum 等等。 ⽀持不同数据源,建⽴⼀个可扩展的、统⼀的元数据层是⾮常重要的 ,否则你的元数据是缺失的。
从上⾯Metacate的架构图中,可以看到,Metacate的设计⾮常巧妙,它并没有单独再保存⼀份元数据, ⽽是采取直连数据源拉的⽅式,⼀⽅⾯它不存在保存两份元数据⼀致性的问题,另⼀⽅⾯,这种架构设计很轻量化,每个数据源只要实现⼀个连接实现类即可,扩展成本很低,这种设计叫做集成型设计 。这种设计⽅式对于希望构建元数据中⼼的企业,是⾮常有借鉴意义的。
Apache Atlas 实时数据⾎缘采集
同样,关于Apache Atlas的背景和功能, 元数据管理之Apache Atlas简介 。

这里强调 Atlas实时数据⾎缘采集的架构设计,因为它为解决⾎缘采集的准确性和时效性难题提供了很多的解决思路。
⾎缘采集,⼀般可以通过三种⽅式:
1. 通过静态解析SQL,获得输⼊表和输出表;
2. 通过实时抓取正在执⾏的SQL,解析执⾏计划,获取输⼊表和输出表;
3. 通过任务⽇志解析的⽅式,获取执⾏后的SQL输⼊表和输出表。
第⼀种⽅式,⾯临准确性的问题,因为任务没有执⾏,这个SQL对不对都是⼀个问题。
第三种⽅式,⾎缘虽然是执⾏后产⽣的,可以确保是准确的,但是时效性⽐较差,通常要分析⼤量的任务⽇志数据。
所以第⼆种 ⽅式,是⽐较理想的实现⽅式,⽽Atlas就是这种实现。
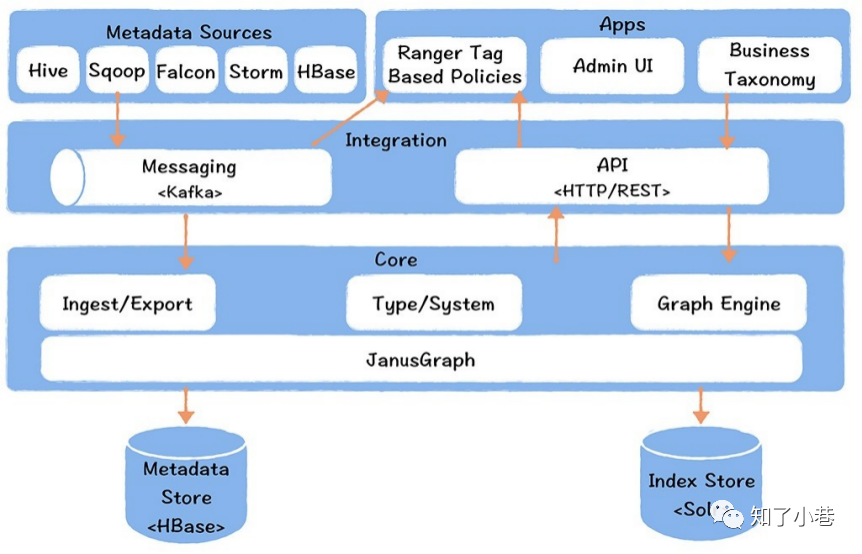
对于Hive计算引擎,Atlas通过Hook⽅式,实时地捕捉任务执⾏计划,获取输⼊表和输出表,推送给Kafka,由⼀个Ingest模块负责将⾎缘写⼊JanusGraph图数据库中。 然后通过API的⽅式,基于图查询引擎,获取⾎缘关系。 对于Spark,Atlas提供了Listener的实现⽅式,此外Sqoop、Flink 也有对应的实现⽅式。
下⾯了解⼀下⽹易元数据中⼼的设计,以便掌握⼀个元数据中⼼在设计时应该考虑哪些点。
⽹易元数据中⼼设计
在设计之初,设定了元数据中⼼必须实现的5个关键⽬标:
其⼀,多业务线、多租⼾⽀持。
在⽹易,电商、⾳乐都是不同的业务线,同⼀个业务线内,也分为算法、数仓、⻛控等多个租⼾,所以元数据中⼼必须⽀持多业务线、多租⼾。
其⼆,多数据源的⽀持。
元数据中⼼必须要能够⽀持不同类型的数据源(⽐如 MySQL、Hive、Kudu 等),同时还要⽀持相同数据源的多个集群 。 为了规范化管理,还需要考虑将半结构化的KV也纳⼊元数据中⼼的管理(⽐如Kafka、Redis、HBase等)。这些系统本⾝并没有表结构元数据,所以需要能够在元数据中⼼⾥定义Kafka每个Topic的每条记录JSON中的格式,每个字段代表什么含义。
其三,数据⾎缘。
元数据中⼼需要⽀持数据⾎缘的实时采集和⾼性能的查询。 同时,还必须⽀持字段级别的⾎缘。 什么是字段级别的⾎缘,我们来举个例⼦。
insert overwrite table t2 select classid, count(userid) from t1 group by classid;复制
t2表是由t1表的数据计算来的,所以t2和t1是表⾎缘上下游关系,t2的classid字段是由t1的classid字段产⽣的,count字段是由userid经过按照classid字段聚合计算得到的,所以t2表的classid与t1的classid存在字段⾎缘,t2表的count分别与t1表的classid和userid存在⾎缘关系。
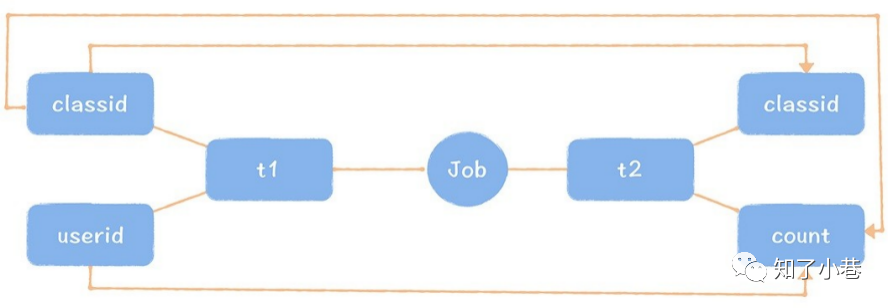
字段⾎缘在做溯源的时候⾮常有⽤,因为⼤数据加⼯链路的下游是集市层,为了⽅便使⽤者使⽤,⼀般都是⼀些很宽的表(列很多的表,避免join带来的性能损耗),这个表的上游可能是有⼏⼗个表产⽣的,如果不通过字段⾎缘限定溯源范围,就会导致搜索范围变得很⼤,⽆法快速地精准定位到有问题的表。
另外,数据⾎缘还必须要⽀持⽣命周期管理,已经下线的任务应该⽴即清理⾎缘,⾎缘要保留⼀段时间,如 果没有继续被调度,过期的⾎缘关系应该予以清理。
其四,与⼤数据平台集成。
元数据中⼼需要与Ranger集成,实现基于tag的权限管理⽅式。

在元数据中⼼中可以为表定义⼀组标签,Ranger可以基于这个标签,对拥有某⼀个标签的⼀组表按照相同的权限授权。这种⽅式⼤幅提⾼了权限管理的效率。⽐如,对于会员、交易、⽑利、成本,可以设定表的敏感等级,然后根据敏感等级,设定不同的⼈有权限查看。
另外,元数据中⼼作为基础元数据服务,包括⾃助取数分析系统,数据传输系统,数据服务,都应该基于元 数据中⼼提供的统⼀接⼝获取元数据。
其五,数据标签。
元数据中⼼必须要⽀持对表和表中的字段打标签,通过丰富的不同类型的标签,可以完善数据中台数据的特征,⽐如指标可以作为⼀种类型的标签打在表上,主题域、分层信息都可以作为不同类型的标签关联到表。
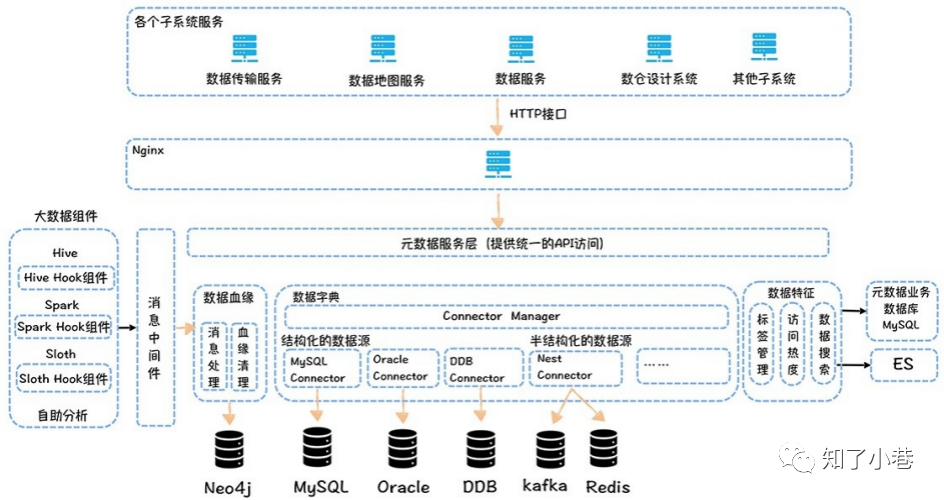
这个图按照功能模块分为数据⾎缘、数据字典和数据特征。
数据⾎缘由采集端、消息中间件、消费端以及⾎缘清理模块组成,基于Hive Hook,Spark Listener,Flink Hook ,可以获取任务执⾏时输⼊表和输出表,推送给统⼀的消息中间件(Kafka),然后消费端负责将⾎缘关系沉淀到图数据库中。
图数据库选择Neo4j,主要考虑是性能快、部署轻量化、依赖模块少,当然,开源的Neo4j没有⾼可⽤⽅案,并且不⽀持⽔平扩展,但是因为单个业务活跃的表规模基本也就在⼏万的规模,所以单机也够⽤,⾼可⽤可以通过双写的⽅式实现。
⾎缘还有⼀个清理的模块,主要负责定时清理过期的⾎缘,⼀般把⾎缘的⽣命周期设置为7天。
数据字典部分,参考了Metacate实现,由⼀个统⼀的Connector Mananger负责管理到各个数据源的连接。对于Hive、MySQL,元数据中⼼并不会保存系统元数据,⽽是直接连数据源实时获取。对于Kafka、HBase、Redis等KV,在元数据中⼼⾥内置了⼀个元数据管理模块,可以在这个模块中定义Value的schema信息。
数据特征主要是标签的管理以及数据的访问热度信息。元数据中⼼内置了不同类型的标签,同时允许⽤⼾⾃ 定义扩展标签类型。指标、分层信息、主题域信息都是以标签的形式存储在元数据中⼼的系统库⾥,同时元数据中⼼允许⽤⼾基于标签类型和标签搜索表和字段。
元数据中⼼统⼀对外提供了API访问接⼝,数据传输、数据地图、数据服务等其他的⼦系统都可以通过API接⼝获取元数据。另外Ranger可以基于元数据中⼼提供的API接⼝,获取标签对应的表,然后根据标签更新表对应的权限,实现基于标签的权限控制。
元数据中⼼构建好以后,这个元数据中⼼有没有界⾯?它⻓什么样⼦?⽤⼾咋使⽤这个元数据中⼼?
数据地图:元数据中⼼的界⾯
数据地图是基于元数据中⼼构建的⼀站式企业数据资产⽬录,可以看作是元数据中⼼的界⾯。数据开发、分析师、数据运营、算法⼯程师可以在数据地图上完成数据的检索,解决了“不知道有哪些数据?”“到哪⾥找数据?”“如何准确的理解数据”的难题。
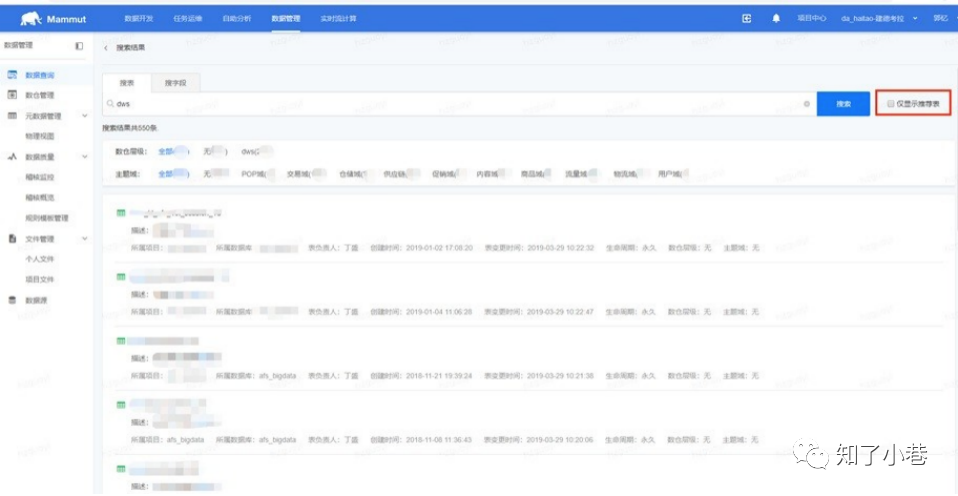
数据地图提供了多维度的检索功能,使⽤者可以按照表名、列名、注释、主题域、分层、指标进⾏检索,结 果按照匹配相关度进⾏排序。考虑到数据中台中有⼀些表是数仓维护的表,有⼀些表数仓已经不再维护,在结果排序的时候,增加了数仓维护的表优先展⽰的规则。同时数据地图还提供了按照主题域、业务过程导览,可以帮助使⽤者快速了解当前有哪些表可以使⽤。
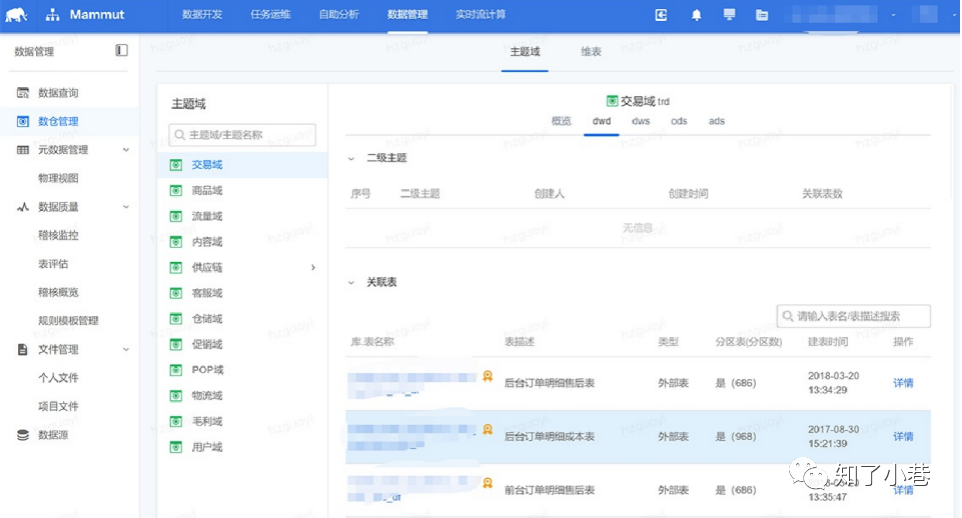
当使⽤者定位到某⼀个表打开时,会进⼊详情⻚,详情⻚中会展⽰表的基础信息,字段信息、分区信息、产 出信息以及数据⾎缘。数据⾎缘可以帮助使⽤者了解这个表的来源和去向,这个表可能影响的下游应⽤和报 表,这个表的数据来源。
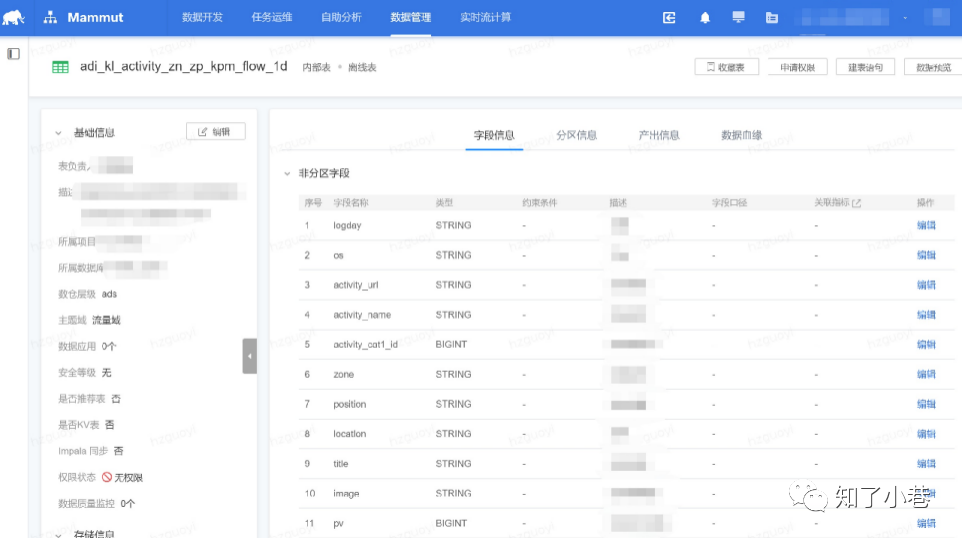
数据地图同时还提供了数据预览的功能,考虑到安全性因素,只允许预览10条数据,⽤于判断数据是否符合 使⽤者的预期。数据地图提供的收藏功能,⽅便使⽤者快速找到⾃⼰经常使⽤的表。当数据开发、分析师、数据运营找到⾃⼰需要的表时,在数据地图上可以直接发起申请对该表的权限申请。
数据地图对于提⾼数据发现的效率,实现⾮技术⼈员⾃助取数有重要作⽤。经过实践,数据地图是数据中台中使⽤频率最⾼的⼀个⼯具产品,在⽹易,每天都有500以上⼈在使⽤数据地图查找数据。
总结
以元数据作为起点,了解元数据应该包括数据字典、数据⾎缘和数据特征,然后通过分析两个业界⽐较有影响⼒的元数据中⼼产品,结合⽹易数据中台实践,给出了元数据中⼼设计的5个关键特性和技术实现架构,最后介绍了基于元数据中⼼之上的数据地图产品。
⼏个关键点:
1. 元数据中⼼设计上必须注意扩展性,能够⽀持多个数据源,所以宜采⽤集成型的设计⽅式。
2. 数据⾎缘需要⽀持字段级别的⾎缘,否则会影响溯源的范围和准确性。
3. 数据地图提供了⼀站式的数据发现服务,解决了检索数据,理解数据的“找数据的需求”。
最后,元数据中⼼是数据中台的基⽯,它提供了我们做数据治理的必须的数据⽀撑。
往期推荐:
Kafka消息送达语义说明
Hadoop YARN:ApplicationMaster向ResourceManager注册AM源码调试
Apache Hadoop YARN:Client<-->ResourceManager源码解析
Apache Hadoop YARN:Client<-->ResourceManager源码DEBUG
Hadoop YARN:ApplicationMaster与ResourceManager交互源码解析
Hive-DML(Data Manipulation Language)数据操作语言
Hive-DDL(Data Definition Language)数据定义


