





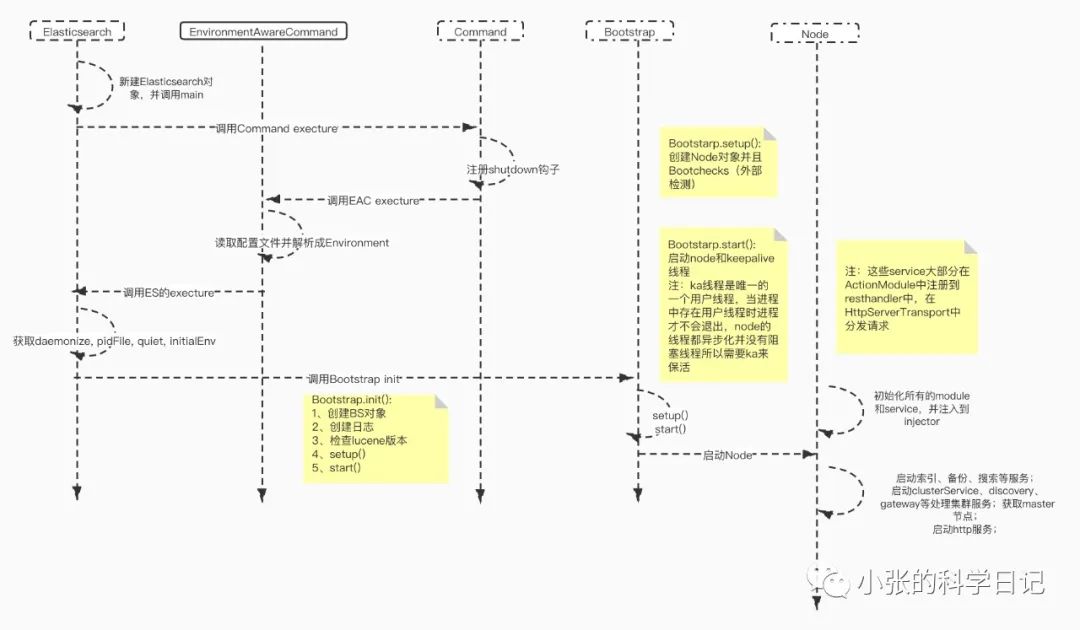
一、单节点启动的时序图
Elasticsearch的启动看起来相比Prometheus繁杂,但和大部分服务一样,启动过程也是配置的解析、服务各项依赖的检查、以及子模块的启动,有所不同的是这三项中的具体内容:解析了什么、检查了什么、启动了什么,而在入门系列不会一一细写,而是侧重在启动了什么这方面,对整体有所掌握后,再去刨根挖底。
下图简单描绘了启动流程,Node作为节点的抽象,其中封装了各个子模块的自动,各个子模块启动后异步工作(所以需要保活线程),完成加载本地数据、配置、选主等等工作。
二、各个子服务的功能简述
Node的启动过程比较复杂,各种Module、Service牵涉很多,所以我们直接看停止Node时关闭了哪些服务,代码如下:
private Node stop() {if (!lifecycle.moveToStopped()) {return this;}logger.info("stopping ...");injector.getInstance(ResourceWatcherService.class).stop();injector.getInstance(HttpServerTransport.class).stop();injector.getInstance(SnapshotsService.class).stop();injector.getInstance(SnapshotShardsService.class).stop();// stop any changes happening as a result of cluster state changesinjector.getInstance(IndicesClusterStateService.class).stop();// close discovery early to not react to pings anymore.// This can confuse other nodes and delay things - mostly if we're the master and we're running tests.injector.getInstance(Discovery.class).stop();// we close indices first, so operations won't be allowed on itinjector.getInstance(ClusterService.class).stop();injector.getInstance(NodeConnectionsService.class).stop();nodeService.getMonitorService().stop();injector.getInstance(GatewayService.class).stop();injector.getInstance(SearchService.class).stop();injector.getInstance(TransportService.class).stop();pluginLifecycleComponents.forEach(LifecycleComponent::stop);// we should stop this last since it waits for resources to get released// if we had scroll searchers etc or recovery going on we wait for to finish.injector.getInstance(IndicesService.class).stop();logger.info("stopped");return this;}复制
相比较启动服务就简洁很多了,据此简述下各个服务的功能:
HttpServerTransport : 提供rest接口
SnapshotsService : 快照服务
IndicesServiceIndicesService: 根据集群的状态处理索引
SnapshotShardsService:shard级别快照服务
GatewayService:存储恢复集群的状态
Discovery:选主
SearchService:搜索服务
NodeConnectionsService:节点的连接,每个节点到其他节点都有几条连接
ClusterService:集群管理服务,目前只看到发布集群状态功能
三、启动后加入集群
在HttpServerTransport启动之前(对外提供服务之前),节点就应该先加入集群,确定加入集群后才能对外提供服务,discovery.startInitialJoin() 则是处理join的逻辑。
discovery.start(); // start before cluster service so that it can set initial state on ClusterApplierServiceclusterService.start();assert clusterService.localNode().equals(localNodeFactory.getNode()): "clusterService has a different local node than the factory provided";transportService.acceptIncomingRequests();discovery.startInitialJoin();final TimeValue initialStateTimeout = DiscoverySettings.INITIAL_STATE_TIMEOUT_SETTING.get(settings());configureNodeAndClusterIdStateListener(clusterService);if (initialStateTimeout.millis() > 0) {final ThreadPool thread = injector.getInstance(ThreadPool.class);ClusterState clusterState = clusterService.state();ClusterStateObserver observer =new ClusterStateObserver(clusterState, clusterService, null, logger, thread.getThreadContext());if (clusterState.nodes().getMasterNodeId() == null) {logger.debug("waiting to join the cluster. timeout [{}]", initialStateTimeout);final CountDownLatch latch = new CountDownLatch(1);observer.waitForNextChange(new ClusterStateObserver.Listener() {@Overridepublic void onNewClusterState(ClusterState state) { latch.countDown(); }@Overridepublic void onClusterServiceClose() {latch.countDown();}@Overridepublic void onTimeout(TimeValue timeout) {logger.warn("timed out while waiting for initial discovery state - timeout: {}",initialStateTimeout);latch.countDown();}}, state -> state.nodes().getMasterNodeId() != null, initialStateTimeout);try {latch.await();} catch (InterruptedException e) {throw new ElasticsearchTimeoutException("Interrupted while waiting for initial discovery state");}}}injector.getInstance(HttpServerTransport.class).start();复制
1、找到主节点
Discocery.findMaster 中ping所有的配置的master节点,并按照ping响应将节点加入到active master和 candidates 列表,如果active master不为空,选择其中id最小的节点作为主节点。
private DiscoveryNode findMaster() {logger.trace("starting to ping");List<ZenPing.PingResponse> fullPingResponses = pingAndWait(pingTimeout).toList();if (fullPingResponses == null) {logger.trace("No full ping responses");return null;}if (logger.isTraceEnabled()) {StringBuilder sb = new StringBuilder();if (fullPingResponses.size() == 0) {sb.append(" {none}");} else {for (ZenPing.PingResponse pingResponse : fullPingResponses) {sb.append("\n\t--> ").append(pingResponse);}}logger.trace("full ping responses:{}", sb);}final DiscoveryNode localNode = transportService.getLocalNode();// add our selvesassert fullPingResponses.stream().map(ZenPing.PingResponse::node).filter(n -> n.equals(localNode)).findAny().isPresent() == false;fullPingResponses.add(new ZenPing.PingResponse(localNode, null, this.clusterState()));// filter responsesfinal List<ZenPing.PingResponse> pingResponses = filterPingResponses(fullPingResponses, masterElectionIgnoreNonMasters, logger);List<DiscoveryNode> activeMasters = new ArrayList<>();for (ZenPing.PingResponse pingResponse : pingResponses) {// We can't include the local node in pingMasters list, otherwise we may up electing ourselves without// any check verifications from other nodes in ZenDiscover#innerJoinCluster()if (pingResponse.master() != null && !localNode.equals(pingResponse.master())) {activeMasters.add(pingResponse.master());}}// nodes discovered during pingingList<ElectMasterService.MasterCandidate> masterCandidates = new ArrayList<>();for (ZenPing.PingResponse pingResponse : pingResponses) {if (pingResponse.node().isMasterNode()) {masterCandidates.add(new ElectMasterService.MasterCandidate(pingResponse.node(), pingResponse.getClusterStateVersion()));}}if (activeMasters.isEmpty()) {if (electMaster.hasEnoughCandidates(masterCandidates)) {final ElectMasterService.MasterCandidate winner = electMaster.electMaster(masterCandidates);logger.trace("candidate {} won election", winner);return winner.getNode();} else {// if we don't have enough master nodes, we bail, because there are not enough master to elect fromlogger.warn("not enough master nodes discovered during pinging (found [{}], but needed [{}]), pinging again",masterCandidates, electMaster.minimumMasterNodes());return null;}} else {assert !activeMasters.contains(localNode) :"local node should never be elected as master when other nodes indicate an active master";// lets tie break between discovered nodesreturn electMaster.tieBreakActiveMasters(activeMasters);}}复制
2、向主节点发送Join请求
这里也分为两种情况,一是本节点就是主节点,后面等待选举出正式的节点,落选的话同二;二是其他节点为主节点,本节点向主节点发送Join请求,并等待主节点发布新的状态,接收到新状态判断下主节点是否是预期节点,是的话加入集群成功,不是的话启动rejoin逻辑。
private void innerJoinCluster() {DiscoveryNode masterNode = null;final Thread currentThread = Thread.currentThread();nodeJoinController.startElectionContext();while (masterNode == null && joinThreadControl.joinThreadActive(currentThread)) {masterNode = findMaster();}if (!joinThreadControl.joinThreadActive(currentThread)) {logger.trace("thread is no longer in currentJoinThread. Stopping.");return;}if (transportService.getLocalNode().equals(masterNode)) {final int requiredJoins = Math.max(0, electMaster.minimumMasterNodes() - 1); // we count as onelogger.debug("elected as master, waiting for incoming joins ([{}] needed)", requiredJoins);nodeJoinController.waitToBeElectedAsMaster(requiredJoins, masterElectionWaitForJoinsTimeout,new NodeJoinController.ElectionCallback() {@Overridepublic void onElectedAsMaster(ClusterState state) {synchronized (stateMutex) {joinThreadControl.markThreadAsDone(currentThread);}}@Overridepublic void onFailure(Throwable t) {logger.trace("failed while waiting for nodes to join, rejoining", t);synchronized (stateMutex) {joinThreadControl.markThreadAsDoneAndStartNew(currentThread);}}});} else {// process any incoming joins (they will fail because we are not the master)nodeJoinController.stopElectionContext(masterNode + " elected");// send join requestfinal boolean success = joinElectedMaster(masterNode);synchronized (stateMutex) {if (success) {DiscoveryNode currentMasterNode = this.clusterState().getNodes().getMasterNode();if (currentMasterNode == null) {// Post 1.3.0, the master should publish a new cluster state before acking our join request. we now should have// a valid master.logger.debug("no master node is set, despite of join request completing. retrying pings.");joinThreadControl.markThreadAsDoneAndStartNew(currentThread);} else if (currentMasterNode.equals(masterNode) == false) {// update cluster statejoinThreadControl.stopRunningThreadAndRejoin("master_switched_while_finalizing_join");}joinThreadControl.markThreadAsDone(currentThread);} else {// failed to join. Try again...joinThreadControl.markThreadAsDoneAndStartNew(currentThread);}}}}复制
3、节点正式启动
加入集群逻辑主要是为了描述节点启动的过程,并没有详尽描述选主的逻辑。
