




本篇文章主要介绍,在学习、编写Spark程序时,至少要掌握的Scala语法,多以示例说明。建议在用Scala编写相关功能实现时,边学习、边应用、边摸索以加深对Scala的理解和应用。
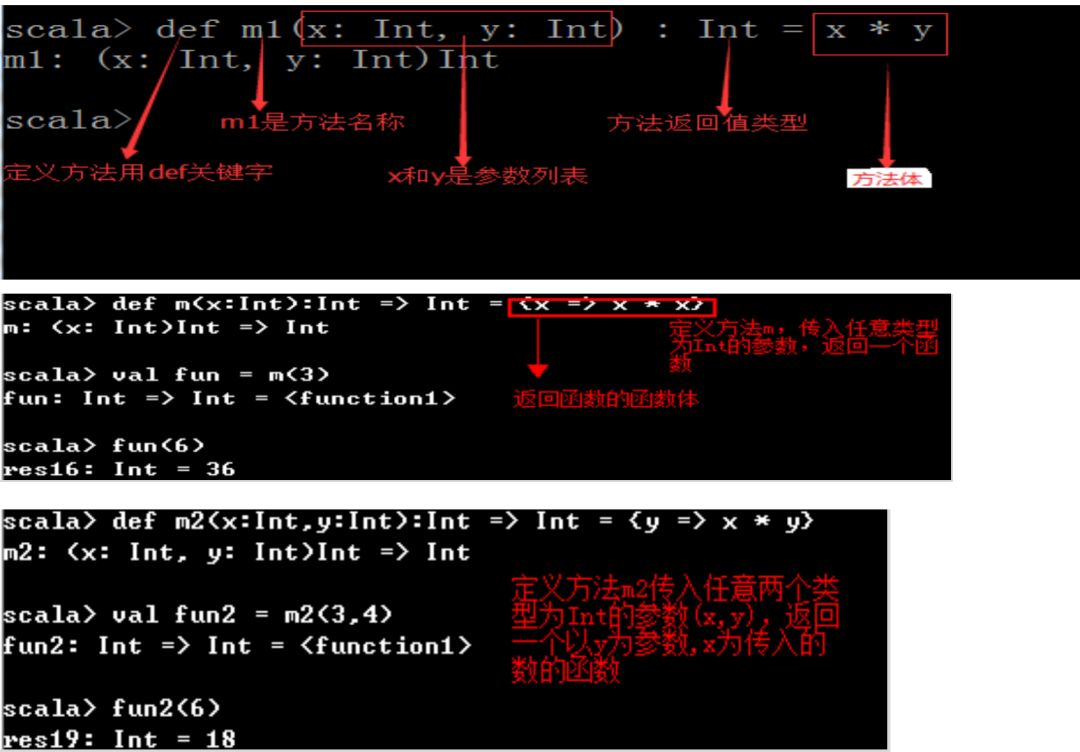
def main(args: Array[String]): Unit = {
使用val定义的变量值是不可变的,相当于java里用final修饰的变量
val i = 1
使用var定义的变量是可变的,在Scala中鼓励使用val
var s = "hello"
Scala编译器会自动推断变量的类型,必要的时候可以指定类型
变量名在前,类型在后
val str: String = "hello"
}复制
def main(args: Array[String]): Unit = {
val x = 1
判断x是否大于0,将最终结果赋给y,打印y
二者等效, Scala语言强调代码简洁
var y = if(x > 0) {x} else {-1}
val y = if(x > 0) x else -1
支持混合类型表达式,返回值类型是Any
var y = if(x > 0) x else "no"
如果缺失else,相当于if (x > 0) 1 else ()
scala表达式中有一个Unit类,写作(),相当于java中void
val y = if(x > 0) 1
if和else if
val f = if (x < 0) 0 else if (x >= 1) 1 else -1
println(y)
}复制
def main(args: Array[String]): Unit = {
val x = 0
scala中{}可包含一系列表达式,块中运行最终结果为块的值
val result = {
if(x < 0) -1 else if(x >= 1) 1 else "error"
}
println(result)
}复制
def main(args: Array[String]): Unit = {
表达式1 to 10返回一个Range区间,每次循环将区间中的一个值赋给i
for (i <- 1 to 3) {
println(i)
}
i代表数组中的每个元素
val arr = Array("a", 1, "c")
for (i <- arr) {
println(i)
}
高级for循环
每个生成器都可以带一个条件,注意:if前面没有分号
相当于双层for循环,i每获得一个值对1to3进行全部遍历并赋值给j然后进行条件判断
for (i <- 1 to 3; j <- 1 to 3 if (i != j)) {
println(i + j)
}
for推导式:如果for的循环体以yield开头,则该循环会构建一个集合
每次迭代生成集合中的一个元素 集合类型为Vector
var v = for (i <- 1 to 3) yield i * i
println(v)
遍历一个数组,to:包头包尾;until:包头不包尾
for (i <- arr.length - 1) {
println(arr(i))
}
for(i <- 0 until arr.length) {
println(arr(i))
}
}复制
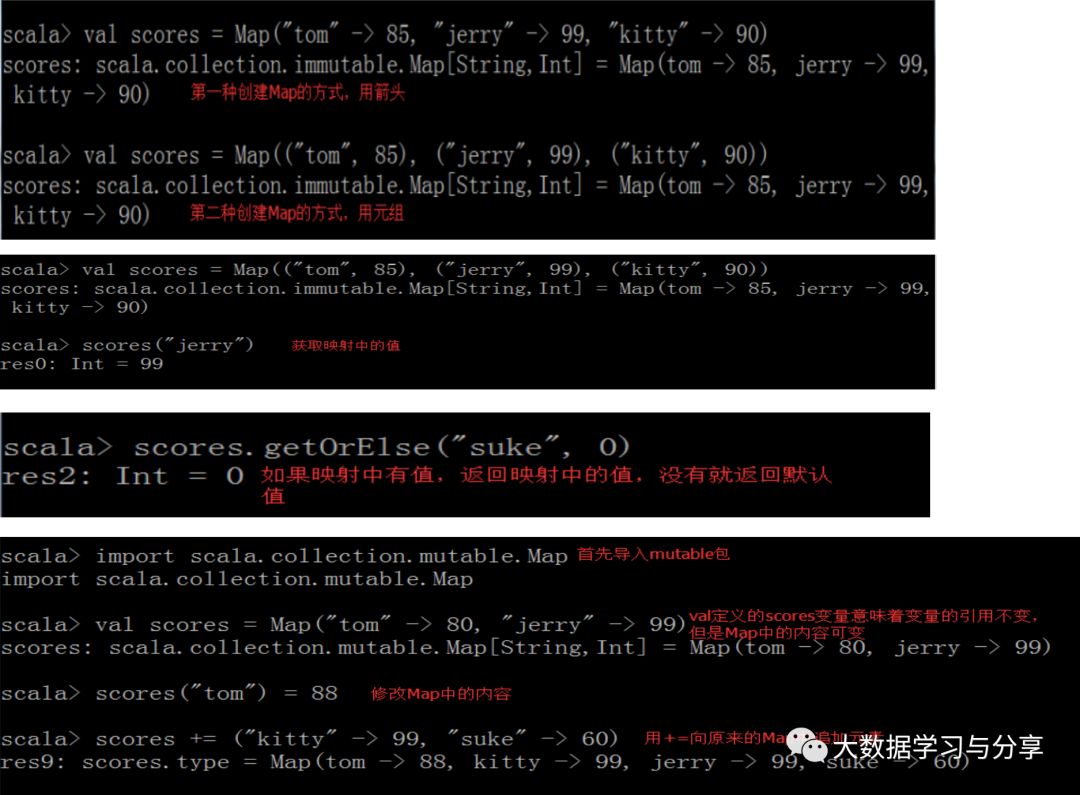
def main(args: Array[String]): Unit = {
val map = Map("a"->1,"b"->2)
//根据key获取value匹配match中的逻辑有值返回Some类型(已封装数据),无值返回None
val v = map.get("b") match {
case Some(i) => i
case None => 0
}
println(v)
更好的方式
val value = map.getOrElse("c",0)
println(value)
}复制
Scala中的+、-、*、/、%等操作符的作用与Java一样,位操作符&、|、^、>>、<<也一样。但在Scala中:这些操作符实际上是方法。例如:a + b是a.+(b)方法调用的简写:a 方法 b可以写成 a.方法(b)。

//偏函数,它是PartialFunction[-A,+B]的一个实例,A代表参数类型,B代表返回值类型,常用作模式匹配(后文阐述)。
def func1: PartialFunction[String, Int] = {
case "one" => 1
case "two" => 2
case _ => -1
}
def func2(num: String): Int = num match {
case "one" => 1
case "two" => 2
case _ => -1
}
def main(args: Array[String]) {
println(func1("one"))
println(func2("three"))
}复制
2.1 数组
import scala.collection.mutable.ArrayBuffer
//scala导包比如导入scala.collection.mutable下所有的类:scala.collection.mutable._
object ArrayDemo {
def main(args: Array[String]): Unit = {
println("======定长数组======")
初始化一个长度为8的定长数组,所有元素初始化值为0
var arr1 = new Array[Int](8)
底层调用的apply方法
var arr2 = Array[Int](8)
toBuffer会将数组转换成数组缓冲
println(arr1.toBuffer) ArrayBuffer(0, 0, 0, 0, 0, 0, 0, 0)
println(arr1(2)) 使用()来访问元素
println("=======变长数组(数组缓冲)======")
val varr = ArrayBuffer[Int]()
向数组缓冲尾部追加一个或多个元素(+=)
varr += 1
varr += (2, 3)
追加一个数组用 ++=
varr ++= Array(4, 5)
varr ++= ArrayBuffer(6, 7)
指定位置插入元素-1和3;参数1:指定位置索引,参数2:插入的元素可以是多个
// def insert(n: Int, elems: A*) { insertAll(n, elems) }
varr.insert(0,-1,3)
varr.remove(0) 删除指定索引处的元素
从指定索引处开始删除,删除多个元素;参1:指定索引,参2:删除个数
varr.remove(0,2)
从0索引开始删除n个元素
varr.trimStart(2)
从最后一个元素开始删除,删除指定个数的元素(length-n max 0)
varr.trimEnd(2)
)
reduce ==>非并行化集合调用reduceLeft
(((1+8)+3)+5)...
println(varr.reduce((x,y)=> x+y))
println(varr.reduce(_+_))
println(varr.reduce(_-_))
Array("one","two","three").max two,字符串比较大小,按照字母表顺序
Array("one","two","three").mkString("-")//以"-"作为数组中元素间的分隔符one-two-three
Array("one","two","three").mkString("1","-","2")//1one-two-three2
参1:arr元素的数组个数,参2:arr中每个数组中元素个数
val arr = Array.ofDim[Int](2, 3)
arr.head arr.last 数组的第一个和最后一个元素
}
}复制
def main(args: Array[String]) {
定义一个数组
val arr = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
将偶数取出乘以10后再生成一个新的数组
val res = for (e <- arr if e % 2 == 0) yield e * 10
println(res.toBuffer)
filter过滤接收一个返回值为boolean的函数,过滤掉返回值为false的元素
map将数组中的每一个元素取出来(_)进行相应操作
val r = arr.filter(_ % 2 == 0).map(_ * 10)
println(r.toBuffer)
数组元素求和,最大值,排序
println(arr.sum+":"+arr.max+":"+arr.sorted.toBuffer)
}复制
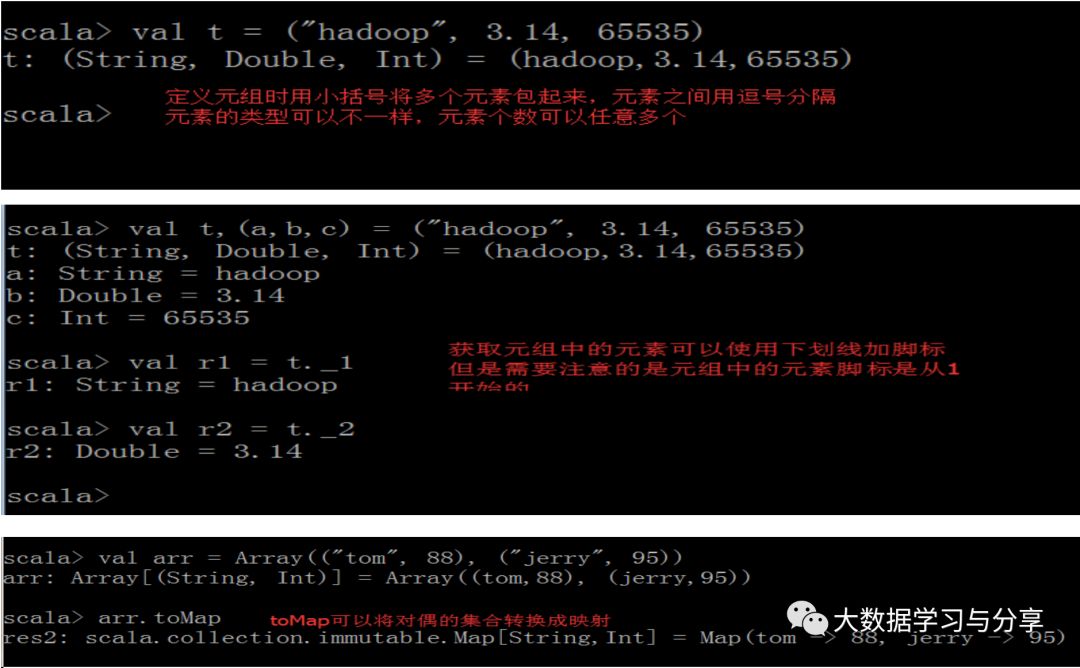
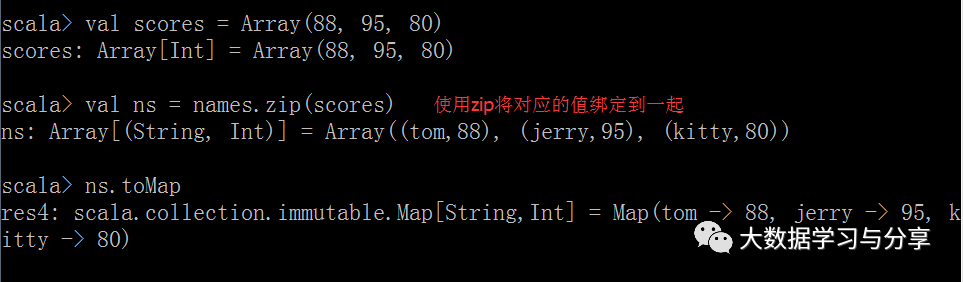
def main(args: Array[String]): Unit = {
创建一个不可变集合
val lt = List(1, 2, 3)
*//添加元素到lt前面生成一个新的List
val lt2 = ("a", -1, 0) :: lt
val lt3 = lt.::(0)
val lt4 = 0 +: lt
val lt5 = lt.+:(0)
println(lt + "==>" + lt2 + "==" + lt3 + "==" + lt4 + "==" + lt5)
val lt6 = lt :+ 4
println("添加元素到后面:"+lt6 )*/
合并两个集合,lt0在lt前面
val lt0 = List(4,5,6,7)
val lt7 = lt0.union(lt)
val lt8 = lt0 ++ lt
println(lt7 +":"+lt8 )
println("lt0在lt后面"+lt ++ lt0)
将两个集合中的元素一一绑定,如果元素数不一致以较少元素集合为准
println(lt0.zip(lt).toMap)
将lt0插入到lt前面生成一个新的集合
println(lt0 ++: lt)
println(lt.:::(lt0))
}复制
def main(args: Array[String]): Unit = {
// 构建一个可变列表,初始有3个元素1,2,3 alt+enter导包
val lst0 = ListBuffer[Int](1,2,3)
创建一个空的可变列表
val lst1 = new ListBuffer[Int]
向lst1中追加元素,注意:没有生成新的集合
lst1 += 4
lst1.append(5)
println(lst1)
将lst1中的元素最近到lst0中, 注意:没有生成新的集合
println(lst0 ++= lst1)
将lst0和lst1合并成一个新的ListBuffer 注意:生成了一个集合
println(lst0 ++ lst1)
将元素追加到lst0的后面生成一个新的ListBuffer
val lst3 = lst0 :+ 5
println(lst3)
}复制
def main(args: Array[String]): Unit = {
// 构建一个可变列表,初始有3个元素1,2,3 alt+enter导包
val lst0 = ListBuffer[Int](1,2,3)
创建一个空的可变列表
val lst1 = new ListBuffer[Int]
向lst1中追加元素,注意:没有生成新的集合
lst1 += 4
lst1.append(5)
println(lst1)
将lst1中的元素最近到lst0中, 注意:没有生成新的集合
println(lst0 ++= lst1)
将lst0和lst1合并成一个新的ListBuffer 注意:生成了一个集合
println(lst0 ++ lst1)
将元素追加到lst0的后面生成一个新的ListBuffer
val lst3 = lst0 :+ 5
println(lst3)
}
def main(args: Array[String]): Unit = {
* 创建一个List
val lst0 = List(1,7,9,8,0,3,5,4,6,2)
将lst0中每个元素乘以10后生成一个新的集合
val lst1 = lst0.map(_*10)
val lst2 = for(i <- lst0) yield i * 10
println(lst1 + ":" +lst2)
将lst0中的偶数取出来生成一个新的集合
val lst3 = lst0.filter(_ % 2 == 0)
val lst4 = for(i <- lst0 if(i % 2 == 0)) yield i
println(lst3 + ":" +lst4)
将lst0排序后生成一个新的集合
val lst5 = lst0.sorted//升序
val lst6 = lst0.sortWith(_>_)//降序
val lst7 = lst0.sortBy(x => x)//升序
println(lst5 + ":" +lst6 + ":" +lst7)
反转顺序
println(lst5.reverse)
将lst0中的元素4个一组,类型为Iterator[List[Int]]
val it = lst0.grouped(4)
// println(it.toBuffer)
将Iterator转换成List
val lst8 = it.toList
将多个list压扁成一个List
println(lst8.flatten)
先按空格切分,再压平
val lines = List("hello tom hello jerry", "hello jerry", "hello kitty")
lines.map(_.split(" ")).flatten
lines.flatMap(_.split(" "))//
并行计算求和
println(lst0.par.sum)
println(lst0.par.reduce(_+_))//非指定顺序
println(lst0.par.reduceLeft(_+_))//指定顺序
折叠:有初始值(无特定顺序)
val lst11 = lst0.fold(100)((x, y) => x + y)
折叠:有初始值(有特定顺序)
val lst12 = lst0.foldLeft(100)((x, y) => x + y) */
聚合
val arr = List(List(1, 2, 3), List(3, 4, 5), List(2), List(0))
// println(arr.flatten.sum)
*先局部求和,再汇总
_+_.sum:第一个下划线是初始值和后面list.sum和,_.sum是list的和,非并行化时只初始化1次只携带1次
_+_:初始值和list元素和的和 */
val result = arr.aggregate(10)(_+_.sum,_+_)
val res = arr.aggregate(10)((x,y)=>x+y.sum,(a,b)=>a+b)
println(result+":"+res)
val l1 = List(5,6,4,7)
val l2 = List(1,2,3,4)
求并集
val r1 = l1.union(l2)
求交集
val r2 = l1.intersect(l2)
求差集
val r3 = l1.diff(l2)
println(r3)
}复制
def main(args: Array[String]): Unit = {
不可变Set
* val set1 = new HashSet[Int]()
将元素和set1合并生成一个新的set,原有set不变
val set2 = set1 + 4
set中元素不能重复
val set3 = set1 ++ Set(5, 6, 7)
val set0 = Set(1,3,5) ++ set3
println(set0)*/
创建一个可变的HashSet
val set1 = new mutable.HashSet[Int]()
向HashSet中添加元素
set1 += 2
add等价于+=
set1.add(4)
set1 ++= Set(1,3,5)
println(set1)
删除一个元素
set1 -= 5
set1.remove(2)
println(set1)
}复制
//在Scala中,类不用声明为public
//Scala源文件中可以包含多个类,所有这些类都具有公有可见性
class Person {
val修饰的变量是只读属性,相当于Java中final修饰的变量,只提供get()
val id = "1"
var修饰的变量,提供get()和set()
var age: Int = 18
类私有字段,只有本类和本类的伴生对象可以访问
private var name = "zs"
对象私有字段只有本类能访问
private[this] val pet = "xq"
}
/**(单例对象,静态对象)
* 伴生对象:与class名相同,并且在同一个文件中*/
object Person {
def main(args: Array[String]): Unit = {
val p = new Person
// p.id = "2"// p.pet
println(p.id +":"+p.age+":"+p.name)
p.name = "ls"
p.age = 20
println(p.age+":"+p.name)
}
}复制
/**每个类都有主构造器,主构造器的参数直接放置类名后面,可以在主构造器中对字段赋值,对于主构造器中参数已赋值的在new的时候可以不再赋值
private[com.bigdata] class Study{}:只有com.bigdata或其子包下的类能访问Stu
class Stu(name:String){}:构造参数name没有val、var修饰
相当于private[this] name:String ,只有本类能访问
class Stu private(name:String){}:private修饰主构造器(私有构造器),只有伴生对象能new */
class Student(val name: String, val age: Int) {
//主构造器会执行类定义中的所有语句
println("执行主构造器")
try {
println("读取文件")
throw new IOException("io exception")
} catch {
case e: NullPointerException => println("打印异常Exception : " + e)
case e: IOException => println("打印异常Exception : " + e)
} finally {
println("执行finally部分")
}
private var gender = "male"
//用this关键字定义辅助构造器
def this(name: String, age: Int, gender: String){
//每个辅助构造器必须以主构造器或其他的辅助构造器的调用开始
this(name, age)
this.gender = gender
}
}复制
1.单例对象
在Scala中没有静态方法和静态字段,但是可以使用object这个语法结构来达到同样的目的。主要作用:
1)存放工具方法和常量
2)高效共享单个不可变的实例
3)单例模式
2.伴生对象
单例对象,不需要new,用【类名.方法】调用单例对象中的方法
伴生对象
在scala的类中,与类名相同且与该类在同一个文件的对象叫伴生对象。类和伴生对象之间可以相互访问私有的方法和属性,但类的字段被private[this]修饰的只有本类能访问复制
object AppObjectDemo extends App{
//不用写main方法
println("Scala")
}复制
def main(args: Array[String]) {
//调用了Array伴生对象的apply方法
//def apply(x: Int, xs: Int*): Array[Int]
//arr1中只有一个元素5
val arr1 = Array(5)
//def apply[T: ClassTag](xs: T*): Array[T] = {}
var arr2 = Array[Int](8)
println(arr1.toBuffer)
//new了一个长度为5的array,数组里面包含5个null(没有指定泛型)
var arr2 = new Array(5)
}复制
trait Flyable {
def fly(): Unit = { println("I can fly") }
}
abstract class Animal {
def run(): Int
val name: String
}
/*class Human extends Animal with Flyable
class Human extends Flyable with其他trait(特质)
*/
class Human extends Animal with Flyable {
val name = "lz"
//t1、t2、、tn打印n次ABC,t1=(1, 2, 3,4)(a->1,b->2,c->3,d->4)
val t1, t2,t3, (a, b, c,d) = {
println("ABC")
(1, 2, 3,4)
}
//scala中重写一个非抽象方法必须使用override关键字
override def fly(): Unit = { println("123") }
//重写抽象方法可以使用也可以不使用override关键字
def run(): Int = { 1 }
}
object Main {
def main(args: Array[String]): Unit = {
val h = new Human
println(h.t1+":"+h.a+":"+h.b+":"+h.c+":"+h.t2)
}
}复制
Scala有一个十分强大的模式匹配机制,可以应用到很多场合:如替代Java中的switch语句、类型检查等。
// 1. 匹配字符串
import scala.util.Random
object Case01 extends App {
val arr = Array(1, 2, 3)
val i = arr(Random.nextInt(arr.length))
i match {
case 1 => {println(i)}
case 2 => {println(i)}
//下划线_:代表匹配其他所有类似于switch语句中default
case _ => {println(i)}
}
}
// 2. 匹配类型
import scala.util.Random
object Case02 extends App {
val arr = Array("a", 1, -2.0, Case02)
val elem = arr(Random.nextInt(arr.length))
println(elem)
elem match {
case x:Int => {println("Int"+x)}
//模式匹配时可以加守卫条件,如果不符合守卫条件,走case_
case y:Double if(y>=0) => println("Double "+ y)
case Case02 => {println("Int"+Case02)}
case _ => {println("default")}
}
}
// 3. 匹配数组
object Case03 extends App {
/* val arr = Array(0, 3, 5)
arr match {
case Array(1,x,y) => println(x+":"+y)
case Array(0) => println("only 0")
//表示匹配首元素是0的数组
case Array(0,_*) => println("0 ...")
case _ => println("else")
}*/
/* val lst = List(0,-1,1,2)
//head首元素,tail除首元素之外的元素 take从1开始取
println(lst.head+":"+lst.tail+":"+lst.take(1))
lst match {
//首元素0,Nil代表空列表
case 0 :: Nil => println("only 0")
//只有两个元素
case x :: y :: Nil => println(s"x:$x--y:$y")
case 0 :: x => println(s"0...$x")//head和tail
case _ => println("else")
}*/
val tup = (-1.2, "a", 5)
tup match {
//元组有几个元素,case后跟的元组也要有几个元素
case (1, x, y) => println(s"hello 123 $x , $y")
case (_, z, 5) => println(z) //前两个元素为任意值
case _ => println("else")
}
val lst1 = 9 :: (5 :: (2 :: Nil))
val lst2 = 9 :: 5 :: 2 :: List()
println(lst2+":"+lst1)//952:952
}复制
import scala.util.Random
case class Task(id:String)
case class HeartTime(private val time:Long)//构造case class可new可不new
case object CheckTimeOut
object Main {
def main(args: Array[String]) {
val arr = Array(CheckTimeOut, HeartBeat(88888), Task("0001"))
val a = arr(Random.nextInt(arr.length))
a match {
case Task(id) => {println(s"$id")}//取id值 固定写法
case HeartTime(time) => {println(s"$time")}
case CheckTimeOutTask => {
println("check")
}
//匹配其他情况
case _ => prinln("do something")
}
}
}复制


大数据常用技术栈
Spark通识

文章转载自大数据学习与分享,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
2025年4月中国数据库流行度排行榜:OB高分复登顶,崖山稳驭撼十强
墨天轮编辑部
1302次阅读
2025-04-09 15:33:27
2025年3月国产数据库大事记
墨天轮编辑部
736次阅读
2025-04-03 15:21:16
2025年3月国产数据库中标情况一览:TDSQL大单622万、GaussDB大单581万……
通讯员
531次阅读
2025-04-10 15:35:48
征文大赛 |「码」上数据库—— KWDB 2025 创作者计划启动
KaiwuDB
458次阅读
2025-04-01 20:42:12
数据库,没有关税却有壁垒
多明戈教你玩狼人杀
408次阅读
2025-04-11 09:38:42
优炫数据库成功应用于国家电投集团青海海南州新能源电厂!
优炫软件
384次阅读
2025-03-21 10:34:08
天津市政府数据库框采结果公布!
通讯员
315次阅读
2025-04-10 12:32:35
最近我为什么不写评论国产数据库的文章了
白鳝的洞穴
311次阅读
2025-04-07 09:44:54
从HaloDB体验到国产数据库兼容性
多明戈教你玩狼人杀
268次阅读
2025-04-07 09:36:17
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
259次阅读
2025-04-14 09:40:20
