




“弓术并非技术。当你射穿自己的心时,就能达到佛陀的境地。”——阿波研造

科技改变生活,创意点亮生活
释放你的潜力和才华,用平凡创造不凡
Tesseract(识别引擎)
安装步骤:
MacOS系统中,安装OSX下的包(Formula)管理软件 Homebrew 。 通过 Homebrew 安装 Tesseract-OCR。 增加 Tesseract-OCR 的多语言识别功能。
1.安装 Homebrew:
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
2.查看 Tesseract-OCR 安装信息:
brew info tesseract
输出:
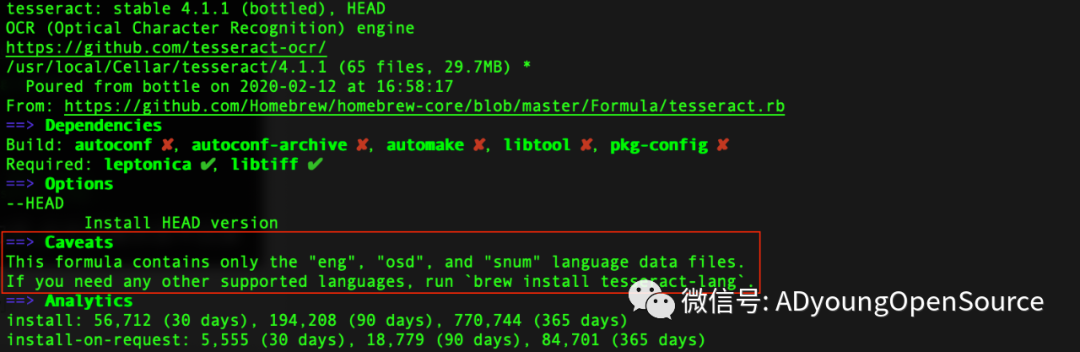
==> Caveats This formula contains only the "eng", "osd", and "snum" language data files. If you need any other supported languages, run `brew install tesseract-lang`.
注明标准包中语言只包括少量几种语言数据。如果想要更多支持语言,需要输入:
brew install tesseract-lang
3.安装 Tesseract-OCR 同时支持多语言识别:
brew install tesseract-lang
Tesseract-OCR 核心操作命令:
tesseract imagename outputbase {-l lang[+lang]} [-psm pagesegmode] [configfile...]
0 = Orientation and script detection (OSD) only.1 = Automatic page segmentation with OSD.2 = Automatic page segmentation, but no OSD, or OCR3 = Fully automatic page segmentation, but no OSD. (Default)4 = Assume a single column of text of variable sizes.5 = Assume a single uniform block of vertically aligned text.6 = Assume a single uniform block of text.7 = Treat the image as a single text line.8 = Treat the image as a single word.9 = Treat the image as a single word in a circle.10 = Treat the image as a single character.
举例使用 Tesseract-OCR 识别操作:

tesseract Users/AAA/Desktop/ffmpeg1.png out -l chi_sim+eng


往期文章
▲
Sometimes ever, sometimes never.
相聚有时,后会无期。

编辑、排版|青泉石上
本文为原创,未经许可请勿转载
文章转载自创意开源,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
