排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
【技术分享】孙玄:MongoDB在58同城的应用实践
【技术分享】孙玄:MongoDB在58同城的应用实践
数据库技术大会
2016-09-09
613
本文整理自DTCC2016主题演讲内容,录音整理及文字编辑IT168@ZYY@老鱼。如需转载,请先联系本公众号获取授权!
演讲嘉宾
孙玄
58同城技术委员会
架构组主任
58同城高级系统架构师,技术委员会架构组主任,产品技术学院优秀讲师,58同城即时通讯、C2C技术负责人,代表58同城多次参与QCon、SDCC、DTCC、Top100等业界大会嘉宾演讲,并为《程序员》杂志两次撰稿。前百度高级工程师,参与基础系统的设计与实现。毕业于浙江大学。
分享内容
大家好,我是来自58的孙玄,今天分享的主题是《MongoDB在58同城的应用实践》,主要内容如下所示:
首先介绍一下MongoDB在58的使用情况,从2011年到2014年,58基本使用了三年MongoDB,三年中,整个公司的业务线都在大规模使用MongoDB。在2014年,由于技术选型的改变,58配合业务特点做了一些调整。14年和15年,58基本很少使用MongoDB,但随着赶集和英才对MongoDB的频繁使用,58于今年又开始大规模使用MongoDB。
就我个人而言,从15年开始真正使用MongoDB,主要应用在业务线上,所以分享的内容主要针对15年之前MongoDB在58的应用案例和实践。随着MongoDB社区的发展,特别是3.0的崛起,可能会略有不足。以上便是此次分享的背景,接下来切入主题。
基本上在2014年底,58比较核心的业务线都在使用MongoDB,包括IM,交友,招聘,信息质量,测试以及赶集和英才。现在最核心的数据存储也是采用MongoDB在做,后期由于技术选型以及业务调整,使用量有所下降。
接下来讲一下选用MongoDB的原因,作为一款NoSQL产品,选择的同时我们会考虑到它的特性,主要有如下几方面:
一是扩展性,MongoDB提供了两种扩展性,一种是Master—Slave,基于主从复制机制,现在58用的比较多的是Replic Set,实际上就是副本集结构。我们会针对不同的业务项进行垂直拆分。
二是高性能,MongoDB在3.0之前,整个的存储引擎依赖于MMAP。MMAP是整个的写内存,就是写磁盘。数据写入内存之后,要通过操作系统的MMAP机制,特别做数据层的,如果数据存多份的话,就可能会造成数据不一致的问题。MongoDB在提供高性能的同时,数据只存一份。这种情况下,设计提供高性能的同时,可以很好地解决数据一致性问题。
除此之外,MongoDB也有其他一些特性,包括丰富的查询,full index支持和Auto-Sharding。另外,做任何选择一定要结合业务逻辑。58原来是分类信息网站,主要的业务特征是并发量比较大,但58和电商的自主交易不同,对事务没那么高要求。在这种场景下,选择MongoDB作为核心存储机制,是非常不错的选择。
MongoDB不像关系型数据库,必须定义Schema,MongoDB比较个性化,对Schema的支持也没有那么严格,可以在表里随意更改结构。但free schema是否真的free吗?比如原来的关系型数据库,需要定义每一列的名称和类型,存储时只需存储真正的数据就可以了,schema本身不需要存储。由于MongoDB没有schema的概念,存储的自由度大了,但整个存储空间会带来一些额外开销,毕竟要存储字段名,value值无法改变,但可以减少字段名的长度,比如age可以考虑用A表示。这时可能会出现可读性问题,我们在业务层做了映射,用A代表age。同时,减小整个数据的字段名,通过上层映射解决可读性问题。
另外我们还做了数据压缩,其实我们有很多文本数据,文本数据的压缩率还是比较高的,我们对部分业务也采取了数据压缩的方式。在Auto-sharding方面,我们采用库级sharding,collection sharding采用手动sharding。当整个表的行数量比较大时,会进行拆分,把一些比较大的文档切分成小文档,包括这些文档的嵌套存储,都是MongoDB相对于其他关系型数据库而言比较优秀的地方。
自动生成_id其实就相当于主键的概念,默认的字段长度是12个字节,整个存储空间的占用比较大,我们尽可能根据业务特征,在业务层把该字段填充成我们自己的字段。如果存储用户信息,该字段可以填成UID,因为UID最大是八个字节。一方面可以减小整个存储空间,另一方面,虽说_id可以在MongoDB服务端生成,但我们尽可能把_id生成工作放在业务层或应用层,可以减少MongoDB在服务端生成_id的开销,写入压力比较大时,整个性能的节省非常明显。
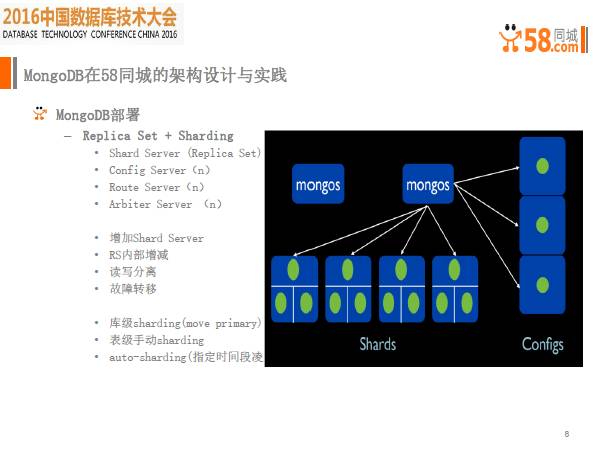
接下来是部署层面,每一个分片上是Replica Set,同时开启Sharding功能,基本结构如上图右边所示,每个分片做一个Sharding,在Sharding上有Replica Set的概念。通过这个架构,所有configs直接通过mongos到shards。增加sharding或者在sharding上做增减,实际上对整个应用是比较透明的。这样部署一方面可以很好的满足业务需求,另一方面可以很好地满足内部扩展和故障转移。
另一个比较隐蔽的话题就是sharding操作,大家可能都比较关心,Auto-Sharding到底靠不靠谱。就我个人理解而言,既然要用Auto-sharding,就要解决sharding key的问题。如果选用单一递增的sharding key,可能会造成写数据全部在最后一片上,最后一片的写压力增大,数据量增大,会造成数据迁移到前面的分区。如果选用随机key,的确可以避免写问题,但如果写随机,读就会出现问题,可能会出现大量随机IO,对一些传统磁盘而言影响是致命的。那如何选取合适的sharding-key呢?先要保证该key在整个大范围内单调递增,这样随机选择时,可以保证相对均匀,不会引发其他问题。
此外,我们在测试中发现,数据迁移过程中经常会出现一些问题。一旦发生数据迁移,比如从A迁到B片,数据可能同时存在于两片数据上,直至迁移完成,整个数据才会全部存在于B片上。58的业务特点属于中午访问的人很少,这时MongoDB集群的负载比较低,系统会认为此适合进行数据迁移,将会开启Auto-sharding。午饭时间结束之后,访问量就开始逐渐增加。此时,整个迁移尚未完成,不会立即停止,集群的OPS会瞬间从几千掉到几十,这对业务的影响非常大。这时,我们会指定整个sharding的迁移时间,比如从凌晨两点到早上六点这段时间属于业务低峰期,这段时间可以允许sharding进行业务迁移,同时开启数据库级别的分片。这样可以避免Auto-sharding数据迁移带来的问题。
另外,做整个设计特别是业务设计时,一定要了解业务发展场景,比如半年或一年内,大概可以增长到什么样的规模,需要提前做预期。根据业务发展情况,就知道大概需要开多少分片,每一片放多少数据量合适。
做整个规划时,也需要考虑容量性能。至少要保证Index数据和Hot Data全部加载到内存中,这样才可以保证MongoDB的高性能,否则性能压力还是蛮大的。2011年开始使用MongoDB时,数据库内存是32g,后来一路上升至196g,其实随着业务的发展,整个硬件投入成本也是蛮高的。实际上如果内存足够大,整个性能情况还是比较令人满意的。
另外,MongoDB整个数据库是按照文件来存储的,如果有大量表需要删除的话,建议将这些表放到统一的数据库里,将会减少碎片,提高性能。单库单表绝对不是最好的选择,表越多,映射文件越多,从MongoDB的内存管理方式来看,浪费越多;同时,表越多,回写和读取时,无法合并IO资源,大量的随机IO对传统磁盘是致命的;单表数据量大,索引占用高,更新和读取速度慢。
另外一个是Local库,Local主要存放oplog,oplog到底设多少合适呢?根据58的经验来看,如果更新比较频繁而且存在延时从库,可以将oplog的值设置的稍微大一点,比如20G到50G,如果不存在延时从库,则可以适当放小oplog值。
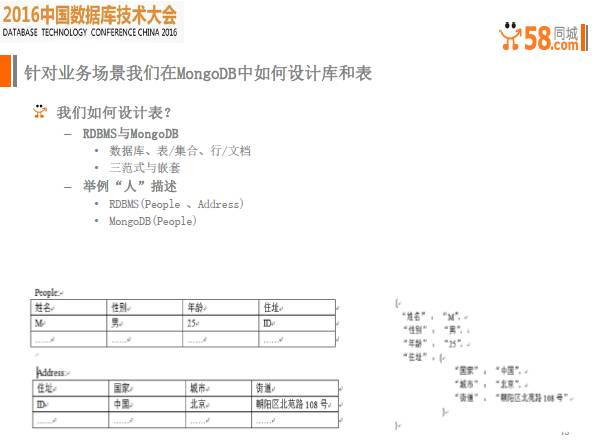
针对业务场景设计库和表,因为MongoDB实际上是带有嵌入式功能的,比如以人为例,一个人有姓名,性别,年龄和地址,地址本身又是一个复杂的结构,在关系型数据库里,可能需要设置两张表。但在MongoDB里非常简单,把地址做成嵌套文档就可以了。
表设计无非这几种,一对一,一对多和多对多的关系,一对一关系比如用户信息表,实际上就是明显的一对一关系,类似于关系型数据的设计,用uid替换_id,做一个主键就ok了。
一对多的关系比如用户在线消息表,一个人其实可以收到很多消息,这是明显的一对多关系,可以按照关系型数据库来设计,按行扩展;也可以采用MongoDB嵌套方式来做,把收到的消息存在一个文档里,同时MongoDB对一个文档上的每一行会有限制,如果超过16兆,可能会出现更新不成功的情况。
多对多关系如上图示例,整个包括Team表,User表,还有两者之间的关系表。在关系型数据库里,这是三张表,一张表是整个Team表的元数据,另一张表是User表的元数据,同时还有关系表,表示二者的包含关系。在MongoDB里,可以借助嵌套关系来完成这件事。
每次通过Team表中的teammates反查询得到teamid,Teammates需要建立索引,具体设计可以参照上图。当整个表比较大的时候,可以做手工分表,这点与关系型数据库类似。
当数据库中一个表的数量超过了千万量级时,我们会按照单个id进行拆分,比如用户信息表,我们会按照uid进行拆分。比如一些商品表,既可以按照用户来查询,又可以按照整个人来查询,这时候怎么办呢?
首先对整个表进行分表操作,infoid包含uid的信息,对infoid进行水平拆分,既可以按照uid查询,又可以按照infoid查询,可以很好地满足商品信息表的需求,整体思路还是按照水平拆分的方式。
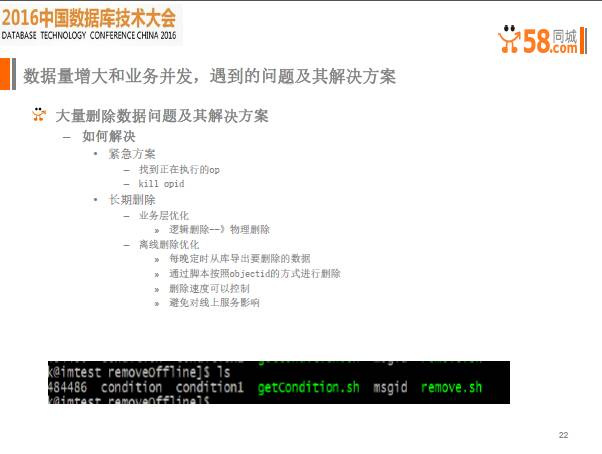
起初,我们做了IM离线消息集合结构,也就是说,当某人不在线时,我可以把消息先存起来,待他上线时,再把整个消息拉过去。在这个过程中考虑到发生物理删除时,更新压力会比较大,我们采用逻辑更新,在表中设置flag字段,flag为0,表示消息未读,flag为1表示消息已读。批量删除已经读取的离线消息,可以直接采用MongoDB的删除命令,非常简单。但当数据量比较大时,比如达到5KW条时,就没那么简单了,因为flag没有索引,我们晚上20点开始部署删除,一直到凌晨依然没有删除完毕,整个过程报警不断,集群的服务质量大幅下降。
原因很简单,因为你要进行删除,实际上就是做了一个全表扫描,扫描以后会把大量冷数据交换到内存,造成内存里全都是冷数据。当数据高峰期上来以后,一定会造成服务能力急剧下降。怎么解决呢?
首先把正在进行的opid kill掉,至少先让它恢复正常,另外可以在业务方面做优化,最好在用户读完以后,直接把整个逻辑删除掉就OK了。其次,对删除脚本进行优化,以前我们用flag删除时,既没有主键也没有索引,我们每天定期从从库把需要删除的数据导出来,转换成对应的主键来做删除,并且通过脚本控制整个删除速度,整个删除就比较可控了。
另外我们发现,一旦大量删除数据,MongoDB会存在大量的数据空间,这些空洞数据同时也会加载到内存中,导致内存有效负荷低,数据不断swap,导致MongoDB数据库性能并没有明显的提升。
这时的解决方案其实很容易想到,MongoDB数据空间的分配以DB为单位,本身提供了在线收缩功能,不以Collection为单位,整个收缩效率并不是很好,因为是online收缩,又会对在线服务造成影响,这时可以采取线下的解决方案。
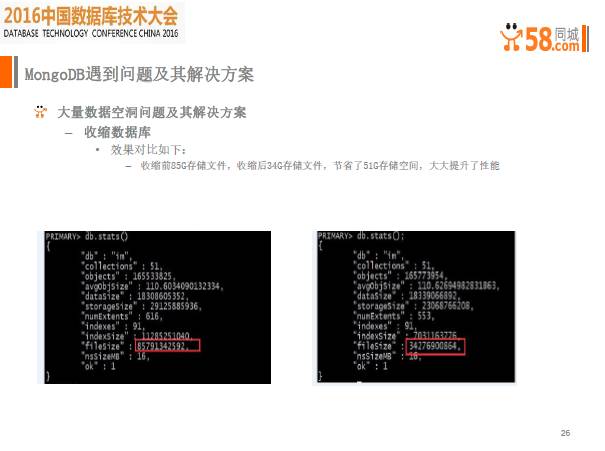
方案二,收缩数据库,把已有的空洞数据remove掉,重新生成一份空洞数据。先预热从库,把预热从库提升为主库,把之前主库的数据全部删除,重新同步数据,同步完成后,预热此库,把此库提升为主库,完全没有碎片,收缩率达到100%。但这种方式持续时间长,投入维护成本高,如果只有2个副本的情况下, 收缩过程单点存在一定风险。
这时在线上做对比,我们发现,收缩前大概是85G的数据量,收缩之后是30G,大概节省了50G的存储量,整个收缩效果还是蛮好的,通过这种方式来做还是比较好的。
另外讲一下MongoDB的监控,MongoDB提供了很多监控工具,包括mongosniff,mongostat,mongotop,以及命令行监控,还有第三方监控。我们自己怎么做呢?
我们针对MongoDB本身的性能情况,用的比较多的是mongostat,可以反映出整个服务的负载情况,比如insert,query,update以及delete,通过这些数据可以反映出MongoDB的整体性能情况。
这其中有些字段比较重要,locked表示加锁时间占操作时间的百分比,faults表示缺页中断数量,miss代表索引miss的数量,还包括客户端查询排队长度,当前连接数,活跃客户端数量,以及当前时间,都可以通过字段反映出来。
根据经验来说,locked、faults、miss、qr/qw,这些字段的值越小越好,最好都为0,locked最好不要超过10%,faults和miss的原因可能是因为内存不够,内冷数据或索引设置不合理,qr|qw堆积会造成数据库处理慢。
Web自带的控制台监控和MongoDB服务一同开启,可以监控当前MongoDB所有的连接数,各个数据库和collection的访问统计,包括Reads,Writes,Queries等,写锁的状态以及最新的几百行日志文件。
官方2011年发布了MMS监控,MMS属于云监控服务,可视化图形监控。在MMS服务器上配置需要监控的MongoDB信息(ip/port/user/passwd等),在一台能够访问你的MongoDB服务的内网机器上运行其提供的Agent脚本,Agent脚本从MMS服务器获取到你配置的MongoDB信息,Agent脚本连接到相应的MongoDB获取必要的监控数据,Agent脚本将监控数据上传到MMS的服务器,登录MMS网站查看整理过后的监控数据图表。
除此之外,还有第三方监控,因为MongoDB的开源爱好者对它的支持比较多,所以会在常用监控框架上做一些扩展。
以上是MongoDB在58同城的使用情况,包括使用MongoDB的原因,以及针对不同的业务场景如何设计库和表,数据量增大和业务并发时遇到的典型问题及解决方案。
今天的分享到此结束,谢谢大家!
关于DTCC
中国数据库技术大会(DTCC)是目前国内数据库与大数据领域最大规模的技术盛宴,于每年春季召开,迄今已成功举办了七届。大会云集了国内外顶尖专家,共同探讨MySQL、NoSQL、Oracle、缓存技术、云端数据库、智能数据平台、大数据安全、数据治理、大数据和开源、大数据创业、大数据深度学习等领域的前瞻性热点话题与技术,吸引IT人士参会5000余名,为数据库人群、大数据从业人员、广大互联网人士及行业相关人士提供了极具价值的交流平台。
mongodb
文章转载自
数据库技术大会
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨