





本篇是es的node模块介绍,node模块控制整个es业务组件的启动和停止,同时提供信息和状态统计。
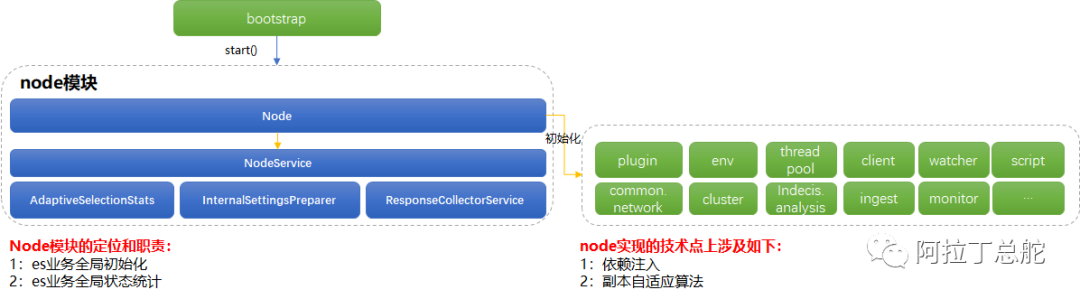
如上图,node模块自身业务非常简单,其业务上主要是进行es全局的初始化,以及提供节点的状态统计。上一节我们介绍了bootstrap模块,bootstrap是做系统层级的预置和初始化,node则是由bootstrap调用,开启了真正业务层级的初始化,例如plugin初始化,network初始化等。但是就实现层面而言,挺复杂的。下面就来展开剖析。
1. es中node的角色有哪些?如何配置
es中node有三种角色,分别是:
master:master角色节点负责集群的管理类操作,例如索引管理操作,sharding分配等。不参与数据操作(如数据查询,聚合)。只有master节点才具备选举成为集群的控制主节点的资格。
data:data角色节点,数据存储和操作的节点,其属于I/O、内存、CPU密集型
ingest:ingest角色节点可以执行由一个或多个接收处理器组成的预处理管道。其在索引备创建之前进行一些转换等预处理。
如下图:对应的配置方式则为:在elasticsearch.yml中分别设置node.master、node.data、node.ingest。默认值均为true。

而实际上es node内核层面除了上述三种角色外,还有一个node.ml角色,在其扩展插件包中存在。是关于机器学习节点,如果启用机器学习,则必须存在至少一个节点的node.ml为true。机器学习节点用来运行作业并处理机器学习API请求。
2. es中node的统计指标有哪些?
从上图中定位,es的node模块提供全局业务统计信息和状态指标,那有哪些统计信息和状态指标呢?
统计信息方面,如下:包含有配置信息(来自于elasticsearch.yml和扩展模块提供的配置),os,进程,jvm,线程池,transport,插件,索引,协调服务。而提供这些信息详情的均由monitor模块或者各自的模块提供,esnodeService中只是做个信息汇总。
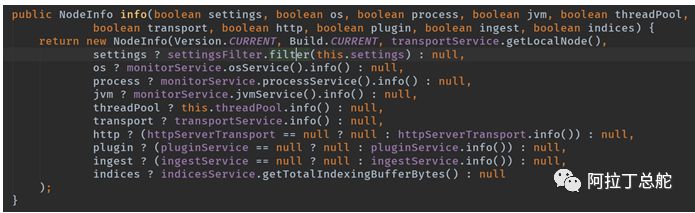
接口/_nodes?pretty显示的信息正式从此处得来:

统计指标方面:如下图,也很多。

接口/_nodes/stats?pretty显示的信息正式从此处得来。
3. es中关于node模块都有哪些控制参数?
除了node的角色配置参数外,还有如下:
node.portsfile:默认为false,在elasticsearch.yml中配置,如果开启了,则会在日志目录下生成http.ports和transport.ports 记录绑定的http监听地址和transport监听地址。
node.local_storage:是否将节点的元数据持久化到磁盘,默认为true,只有节点角色为ingest的时候才可以为false
node.name:节点名称,如果未配置,则自动获取节点的hostname。
node.attr.xx:节点的扩展属性。例如node.attr.rack可描述节点所在的机柜信息。利用扩展属性,可以针对性的将es数据的主分片和副本分片分配到不同的物理机,或者不同的机架,机房。提高系统的可用性。
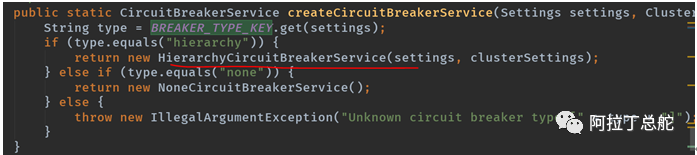
indices.breaker.type:断路器类型。枚举[hierarchy,none]。默认为hierarchy。Es中有多种断路器用来防止业务操作引起es的OOM现象。如果配置为none,则意味着不启用断路器。否则启用。
4. es中如何初始化业务模块
node是做全局业务初始化的,其在bootstrap模块中构造node实例,并start启动。按理说初始化业务对象,就new一把就成的。但是es中实现的方式比较新颖,或者说怪异。所以单拎出来简单介绍下:代码核心逻辑如下,初看,这货的写完看得人一头雾水。从inject名字看是依赖注入。看着似乎es自己实现了一套依赖注入的框架。org.elasticsearch.common.inject包下就是其依赖注入框架。使用此的意图很明显,全局业务初始化都是使用单例模式。
实际上,并不是es自己实现了一套依赖注入的框架,而是使用了google开源的Guice组件。Guice是个轻量级的依赖注入框架,提供Java和注解两种模式使用,而我们常用的Spring是提供注解和配置两种模式的。Es只是将Guice以源码的方式引用了进来,并存放于其org.elasticsearch.common.inject下。
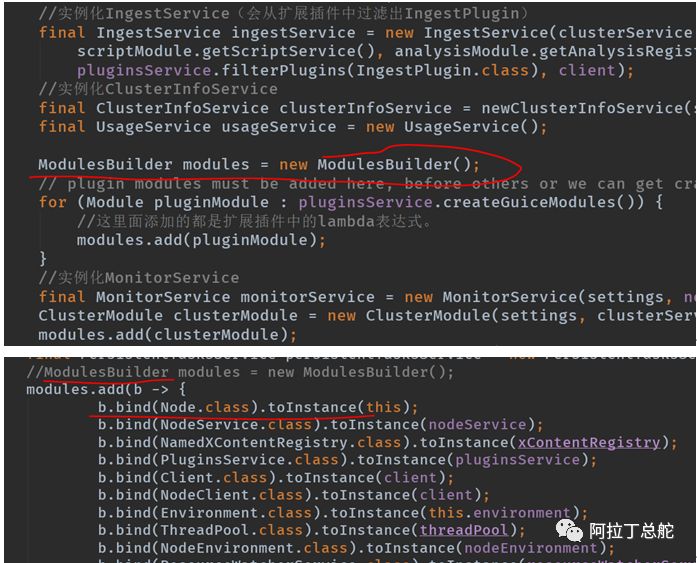
而node类中再讲inject作为其成员变量,在后面start,stop等的时候直接通过其获取单例:例如下获取实例方式:
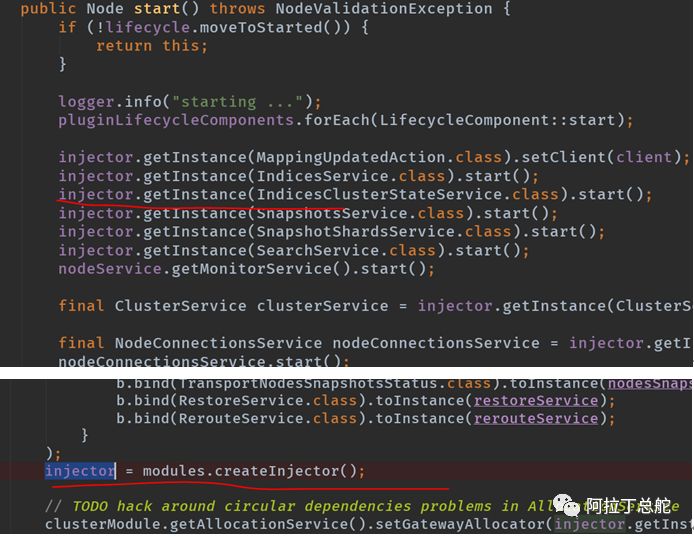
关于google提供的Guice的介绍,看起官网文档:https://github.com/google/guice
至于Node中初始化的业务介绍,则再后续介绍业务组件的时候展开来说。本节只介绍node模块,故不再此部分展开。
5. 关于自适应副本选择(ARS)
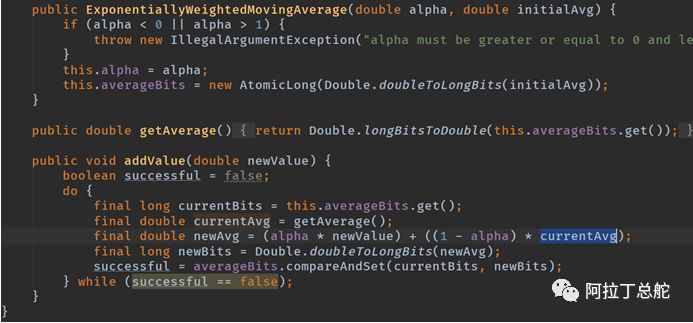
Node模块使用了指数加权移动平均算法,用来提供节点上队列大小,响应时间,服务时间的指标,具体在ResponseCollectorService类中。
这个类是ClusterStateListener的实现类,也就是当es的集群状态发生变化的时候,ResponseCollectorService会订阅到这个变化。如下,只有一个成员变量,其维护的是节点与其几个统计指标:
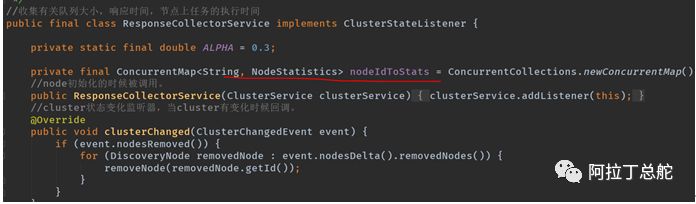
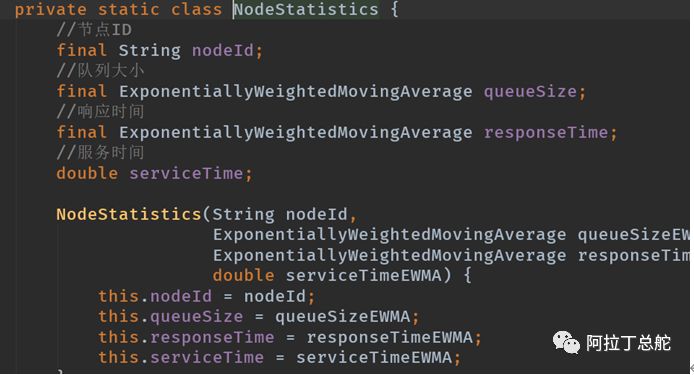
我们先介绍下这个类的使用场景,再来细看队列大小,响应时间是如何通过指数加权移动平均算法计算的。
如下所示,是用来做自适应副本选择的。
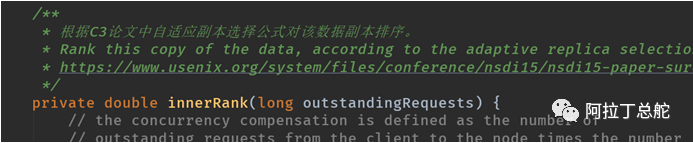
关于自适应副本选择使用场景,这涉及到es是如何进行查询逻辑的。
Es数据分片分为主分片和副本分片,es进行一次查询,在收到搜索请求后,会首先确定查询那个shard,其次确定哪些节点包含该shard的副本,然后轮询的方式选择其中某一个副本,而这种轮询的方式可能不是最合适的,譬如选择的副本所在的es正在进行FGC,或者正在进行高I/O的操作,那么此时通过这个副本去搜索数据性能上会下降很大。而自适应副本选择解决的就是此问题。
ES中的ARS(自适应副本选择)实现是基于一个cassandra数据库写的学术论文:关于ES对ARS的使用详细参考:
https://www.elastic.co/cn/blog/improving-response-latency-in-elasticsearch-with-adaptive-replica-selection

ARS的公式如上图,ES对其进行了改进。在该公式中,对于每个搜索请求,Elasticsearch对分片的每个副本进行排名,以确定哪个最有可能成为将请求发送到的“最佳”副本。Elasticsearch不会以循环方式向分片的每个副本发送请求,而是选择“最佳”副本并将请求路由到那里。而ARS的实现依赖于指数加权移动平均算法(EWMA)。
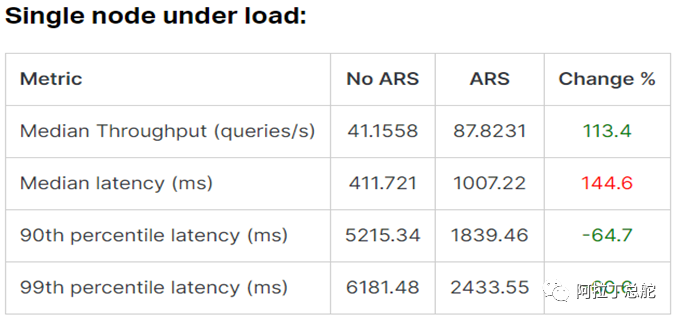
自适应副本选择和轮询选择两种模式下性能对比如下图,可以看到ARS模式对于提高es吞吐量有显著的效果。
ARS在Elasticsearch6.1和更高版本中可用,但在所有6.x版本中默认情况下处于关闭状态。可以通过更改cluster.routing.use_adaptive_replica_selection设置来动态打开它。
总结下,node模块主要提供全局业务组件初始化、node级别的信息统计、为IndexShardRouting提供自适应副本选择的底层算法实现。
