




大数据仓库,是越来越流行的数据解决方案。传统烟囱式的数据开发模式,显然不能满足日益增长的数据需求,而作为大数据量化方案、解决大数据问题、发掘数据价值的大数据仓库被很多公司采纳使用。想要建设好数据仓库,就要了解数据仓库模型设计及其原理、怎样处理数据仓库建设的需求分析?又如何处理基础数据元和维度表、事实表?下面就来简单谈谈数据仓库建模方法论。
理解数据仓库
1.1、数据仓库产生的背景
数据仓库演化的两个阶段:
1),传统烟囱式数据仓库
使用关系型数据库如Mysql、Oracle继承数据,数据量小,一般TB级别数据,如果数据量继续增加,计算风险成倍增加,出现卡死跑不动的现象。而且传统数据库面临的问题是拓展性差、业务理论混乱、往往一种数据模型只能解决一类业务需求。应用单一、主要用于分析商业数据,如BI。

传统数据仓库优点:
a、数据安全可靠,遵守数据库的三范式原则。
b、存储数量小,响应时间极快。
c、数据存储频率高,产生用户行为机会存储到数据库。
传统数据仓库缺点:
a、存储的数据量小,结构简单。
b、只能针对某一个业务过程进行数据分析。
c、大数据量难存,大数据量难算。
2,大数据仓库
大数据仓库,顾名思义就是数据量大,PB、ZB级别。依赖于分布式文件系统和分布式计算来承载业务数据的增长和计算。大数据仓库可以支撑在线应用,又分为离线数据仓库和实时数据仓库。采用严谨的方法理论,清晰的架构模型,开发维护起来更方便。
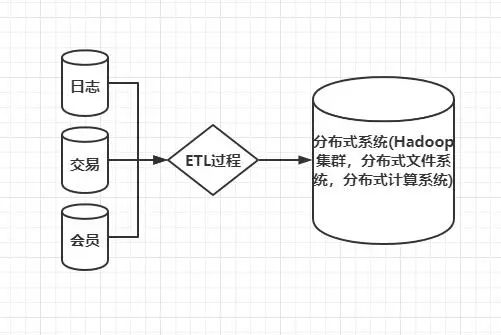
1.2 数据仓库的概念
数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合,用于支持管理决策、商业营销、运营分析。数据仓库实际上是一种数据存储,它将各种异构数据源中的数据集成在一起,并保持其语义一致,为企业决策提供支持。
1,面向主题。在较高层次对数据综合、归类,针对某一分析领域所抽象出来的分析对象。
构建主题的步骤:首先抽象出需要分析的主题域,确定每个主题域需要分析的维度、其所包含哪些数据表。一般主题域所有表都有一个连接键,作为主题的一部分,通过这个连接键可把主题域所有表关联汇总成一张宽表。如会员主题,分为会员基本信息、会员积分数据、会员的资产数据、会员的行为数据、会员的信用等多张表。
2,集成的。数据来源的格式类型不同;编码、命名格式、属性单位不一致,然后对原有数据进行综合、计算。
把不同表、不同类型的数据放入到统一的数据仓库中。如Mysql、Oracle、Redis、Hbase中的数据,我们通过同步全量数据把数据存入统一的系统中。对于增量数据设置定时抽取,可以才有并发架构,多任务同时同步,把数据持续存到我们的分布式文件系统中来。
3,时变的。数据仓库的数据是不同时间的数据集合;随时间变化不断增加、删除、综合数据;数据仓库表结构中一般都带有时间字段。
数据仓库的数据不是一成不变的,它是随着时间变化不断新增内容,更新与时间有关的综合数据,这些数据一般都包含有时间字段。
4、稳定非易失的。.数据仓库中的数据一般只插入新增,不做update更新、delete删除操作。
数据是经过抽取而形成的分析型数据,不具有原始性(不是第一手数据,一般是经过其他数据源或业务系统,抽取到数据仓库中),主要供企业决策分析之用,执行的主要是查询操作,一般情况下不执行更新操作。抽到数据仓库的数据在ODS层不做任何操作,来保持数据的原始性(不改变字段属性,不补值等操作)。
1.3 数据仓库的实际应用
数据仓库主要用来分析数据,给运营管理者提供数据支撑。诸如对用户行为进行分析、对用户信用进行分析。这里以电商为例,如通过对用户行为进行分析,分析用户的购物行为来建立数据模型,针对不同消费行为的用户给予不同程度的运营管理。把分析后的数据做成报表、商业BI等,给与决策者数据支撑。
写在最后:
数仓建设告一段落了,趁着十一有时间,写点关于数仓建设的个人见解。从3月份入职新公司到现在也有半年了,我用半年的时间,把公司大部分业务理清,然后借助云平台开始建设数据仓库。
因为公司使用的是传统数仓,我要做的就是把oracle数据库里的数据跟据数仓方法论,转化建设为大数据数据仓。从零到一是痛苦的,走了很多弯路,期间还要帮算法小伙伴做各种数据模型,天天熬夜加班总算搞出来一点东西。
十一放假前,数仓建设算是告一段落。在此期间借鉴、查询了很多资料,我会把数仓建设过程中需要注意和掌握的概念理论简单谈谈,有错误的地方,希望大家能积极参与解答,指点一二,感谢。
用的技术栈不多,更多就是写HQL。因为使用的第三方平台,集群搭建、底层的东西不需要我问太多。我做的就是数仓建设的典型工作。天天HQL、天天HQL,真是名副其实的SQL BOY。需要经常写的就是UDF、UDAF这类函数了。
但是呢,为了不让代码太生疏,我经常会想法设法的使用代码来做一遍ETL过程,其实写SQL就可以解决的问题。主要是怕长期不写代码,以后再写就不会了。
往期回顾
