




微信公众号:java流水账
本号记录国服安琪拉日常编程流水帐,欢迎后台留言
背景
公司风险部门的同学平常都是在impala中查看T+1的业务数据,希望技术部门提供一个看板,能够实时查看当前各个业务线的调用外部数据的情况,所以有了这篇文章,grafana平常用influxdb、kairosDB作为数据源比较多,现在记录一下用mysql作为数据源的实践。
第一步:配置数据源
Grafana的安装网上教程很多,大家如果公司没有可以测试环境自己搭一个,有的申请一个账号,我们直接开始安装后的数据源配置,步骤如下:
 配置图
配置图
如上图所示:
配置中选择Data Sources;
设置数据的名称,数据源类型选择MySQL;
填写MySQL的主机、用户名密码,保存&测试。
第二步:配置图表
先看配置完成之后的效果图,如下:
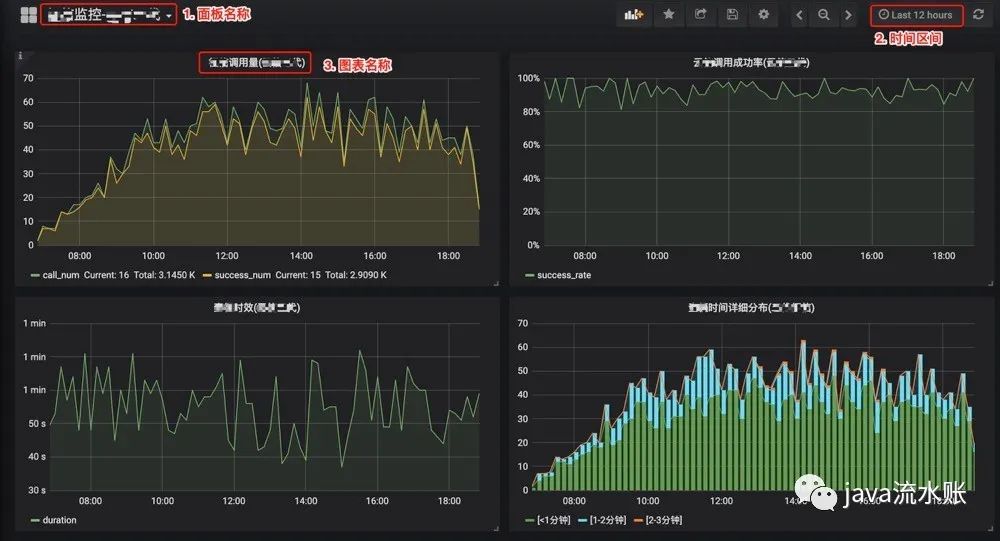 效果图1
效果图1

效果图2
如上图所示,我做了实时的调用量、调用成功率、调用时效、流程时间分布、按照业务线区分调用量、调用失败原因分布等。
说明一下,我所有的图表都基于一张日志表,因为都是线上真实数据,就只贴出表结构,数据不贴出来了,表结构如下:
CREATE TABLE `credit_log` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`appid` varchar(60) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '应用id',
`userid` bigint(20) NOT NULL COMMENT '用户id',
`batchno` varchar(50) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '批次号',
`options` varchar(50) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '机构类型',
`request` text COLLATE utf8mb4_unicode_ci COMMENT '请求报文',
`task` text COLLATE utf8mb4_unicode_ci COMMENT '任务',
`redistopic` varchar(50) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT 'redis队列topic',
`status` int(11) NOT NULL DEFAULT '-1' COMMENT '0:成功 1:用户信息不全 2:异常 3:签章异常 4:上传异常 5**结果异常 9:不在有效时间/重复查征',
`errcode` int(11) DEFAULT NULL COMMENT '错误码',
`message` varchar(2048) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '详细说明',
`inserttime` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '添加时间',
`updatetime` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '更新时间',
`isactive` tinyint(1) NOT NULL DEFAULT '1' COMMENT '是否有效',
`retrytime` int(11) DEFAULT '0' COMMENT '重试次数',
`idnumber` varchar(64) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '身份证号码',
`queststatus` int(11) NOT NULL DEFAULT '-1' COMMENT '请求状态 0:成功 1:失败 2:异常',
`uploadstatus` int(11) NOT NULL DEFAULT '-1' COMMENT '上传状态 0:成功 1:失败 2:异常',
`querystatus` int(11) NOT NULL DEFAULT '-1' COMMENT '查询状态 0:成功 1:失败 2:异常',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_batchno` (`batchno`),
KEY `idx_userid` (`userid`) USING BTREE,
KEY `idx_inserttime` (`inserttime`) USING BTREE,
KEY `idx_updatetime` (`updatetime`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='日志表';复制
配置示例
下面会把典型的场景和图表配置信息贴出来。
2.1 调用量为例,配置如下:
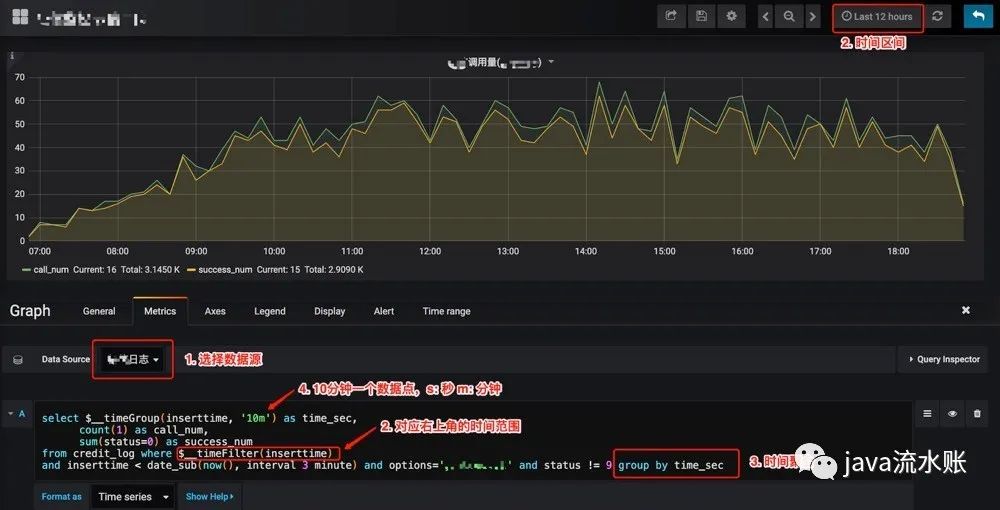 调用量
调用量
如上图所示,最重要的配置在metrics里面,选择数据源,然后写sql,简化后的sql如下:
select $__timeGroup(inserttime, '10m') as time_sec,
count(1) as call_num,
sum(status=0) as success_num
from credit_log where $__timeFilter(inserttime)
group by time_sec复制
注意二个点:
$__timeGroup是聚合函数,这里是以10分钟一组,group by求和;
$__timeFilter(inserttime)是时间区间函数,右上角时间选择筛选的是inserttime
下面这张图展示了Metrics(指标)的另外三个值得关注的地方:
 Metrics(指标)
Metrics(指标)
另外还有几个配置的点:
General(常规选择)、Metrics(指标)、Axes(坐标轴)、Legend(图例)、 Display(显示样式)、Alert(告警)、Time range(时间范围)。
重点说Axes:
 Axes(坐标轴)说明
Axes(坐标轴)说明
上面是调用量方面的,大家可以根据自己的数据表举一反三。
2.2 流程耗时分布图为例,sql如下:
通过这张图可以看到时间分布情况。
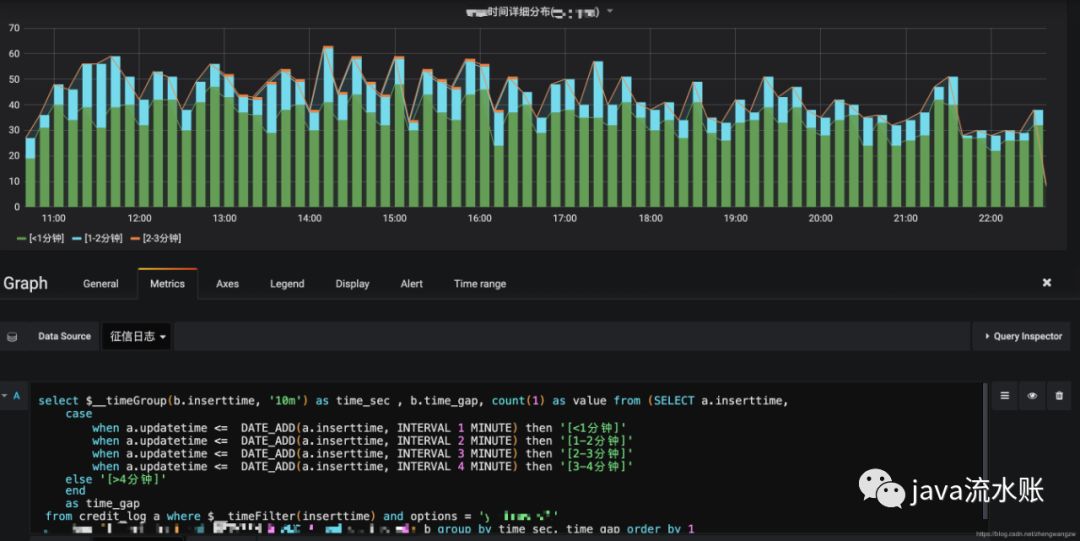 流程耗时分布图
流程耗时分布图
第三步:使用变量
如果图表需要只看某条业务线的,或者只看指定条件的数据。
举个我这里的实际业务场景,就是很多业务线会调用我的站点,拉取外部机构的数据,那业务线和外部机构就是二个变量,我可以在grafana中提前定义好,先看效果图(以表格为例):

业务线变量
业务线可以指定,查看指定的某个或某几个业务线的数据,如下图所示:

左上角有二个下拉列表我把详细sql也贴出来:
SELECT date_format(inserttime, '%Y-%m-%d') as '日期', options, count(1) as '调用量',
sum(case when queststatus=0 then 1 else 0 end) as '发起成功量', sum(case when status=0 then 1 else 0 end) as '写数成功量',
cast(100 * sum(status=0) *1.0/count(1) as DECIMAL(5,2)) as '成功率' from credit_log where
$__timeFilter(inserttime) and options in ('$options') group by 1,2 order by 1 asc复制
上面sql中 就是提前创建的变量。
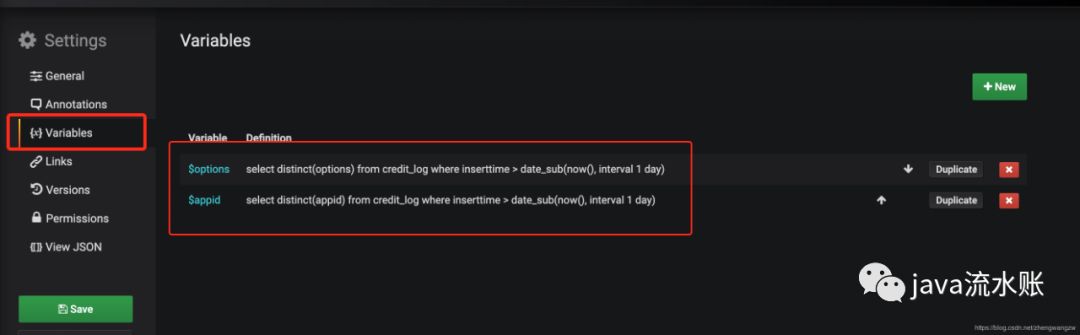
如何创建变量呢?
入口在Dashboard右上角的设置图标这里

👇就是我定义的机构和业务线的变量

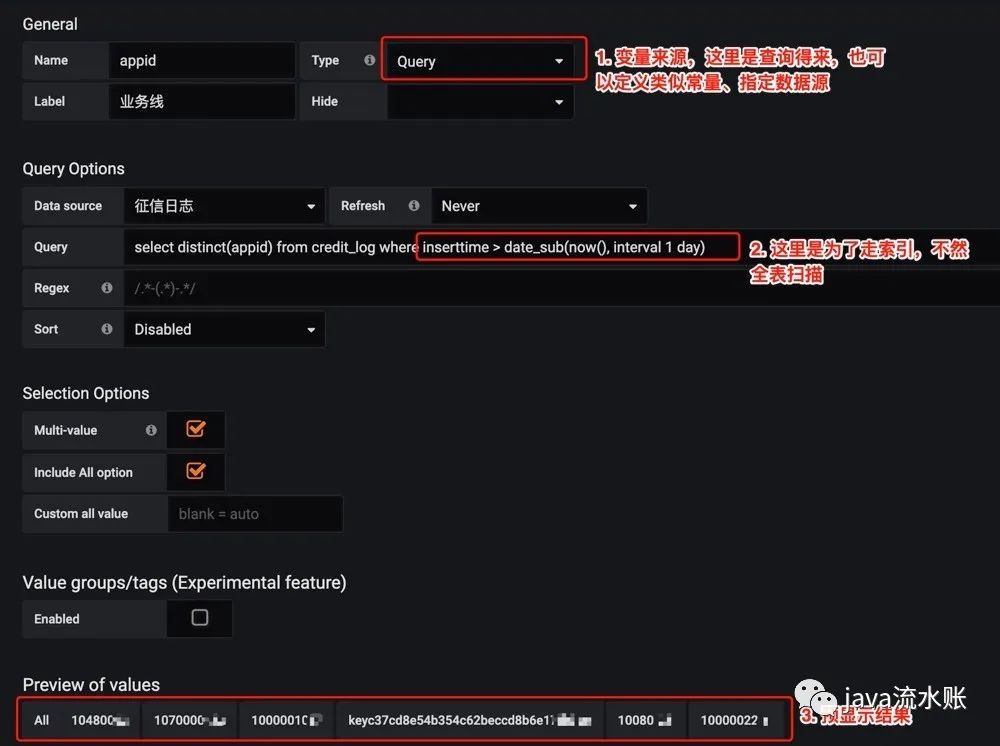
以业务线为例,

这里设置好变量之后,在图表sql中就可以使用 options∗∗就是提前创建的变量。如何创建变量呢?入口在Dashboard右上角的设置图标这里
结束语
这个只是Grafana用Mysql做业务实时数据分析的一点非常小的应用,还有很多其他数据源可以用,例如ElasticSearch、InfluxDB、Zabbix、Prometheus等数据源。
如果大家感兴趣,后面可以分享我使用influxdb + kafka + flink做日志监控的工程实践。
----------------------------国服安琪拉------------------------------------
这里没有敷衍的复制粘贴,博眼球的面试资料分享,有的只是尽可能清晰的讲清个人开发中遇到的一个个问题和总结。欢迎大家关注Java流水账,纯粹的个人技术公众号。
另外如果有兴趣,可以添加我微信: hitwh35 进技术沟通群

